The paper introduces MTP-D, a self-distillation framework designed to enhance Multi-Token Prediction (MTP) in Large Language Models. By aligning MTP heads with the main head's output distribution using a gradient-detached, TopN-selected KL divergence loss, the method achieves a +7.5% MTP head acceptance rate and up to 220.4% inference speedup relative to a 1-head baseline.
TL;DR
Inference efficiency is the "last mile" for scaling Large Language Models (LLMs). While Multi-Token Prediction (MTP) allows models to predict multiple future tokens in parallel, its benefits are often throttled by low acceptance rates of the predicted tokens. MTP-D solves this by using the main head to "teach" the MTP heads via self-distillation. The result? A 7.5% jump in acceptance rates and a massive 220.4% speedup when scaled up to 16 heads using a novel looped extension strategy.
Problem & Motivation: The Acceptance Rate Trap
Standard MTP architectures face a brutal reality: if each MTP head has a moderate acceptance rate (e.g., 70%), the probability of accepting a sequence of 4 tokens drops exponentially. Furthermore, training these auxiliary heads often distracts the model from its primary goal—accurate next-token prediction—leading to a performance trade-off known as the "seesaw effect."
Existing works like DeepSeek-V3 made progress with cascaded architectures, but the gap between the main head's "wisdom" and the MTP heads' "guesses" remained too wide for practical high-speed scaling.
Methodology: High-Fidelity Self-Distillation (MTP-D)
The authors suggest that the main head already possesses the superior semantic mapping needed. MTP-D taps into this by introducing a Self-Distillation loss ($L_{KL}$).
1. Gradient-Detached Alignment
To avoid the "seesaw effect," MTP-D applies a stop-gradient (sg) operation on the main head's logits. This ensures that while the MTP heads learn to mimic the main head, the main head's weights are not "pulled" or corrupted by the relatively nosier MTP training signals.
2. TopN Logits Selection
Distilling over a 122k+ vocabulary is computationally expensive and numerically unstable. The authors found that selecting only the Top 10,000 logits covers ~99.5% of the probability mass, providing a clean, focused signal for the MTP heads to learn the distribution modes of the teacher.
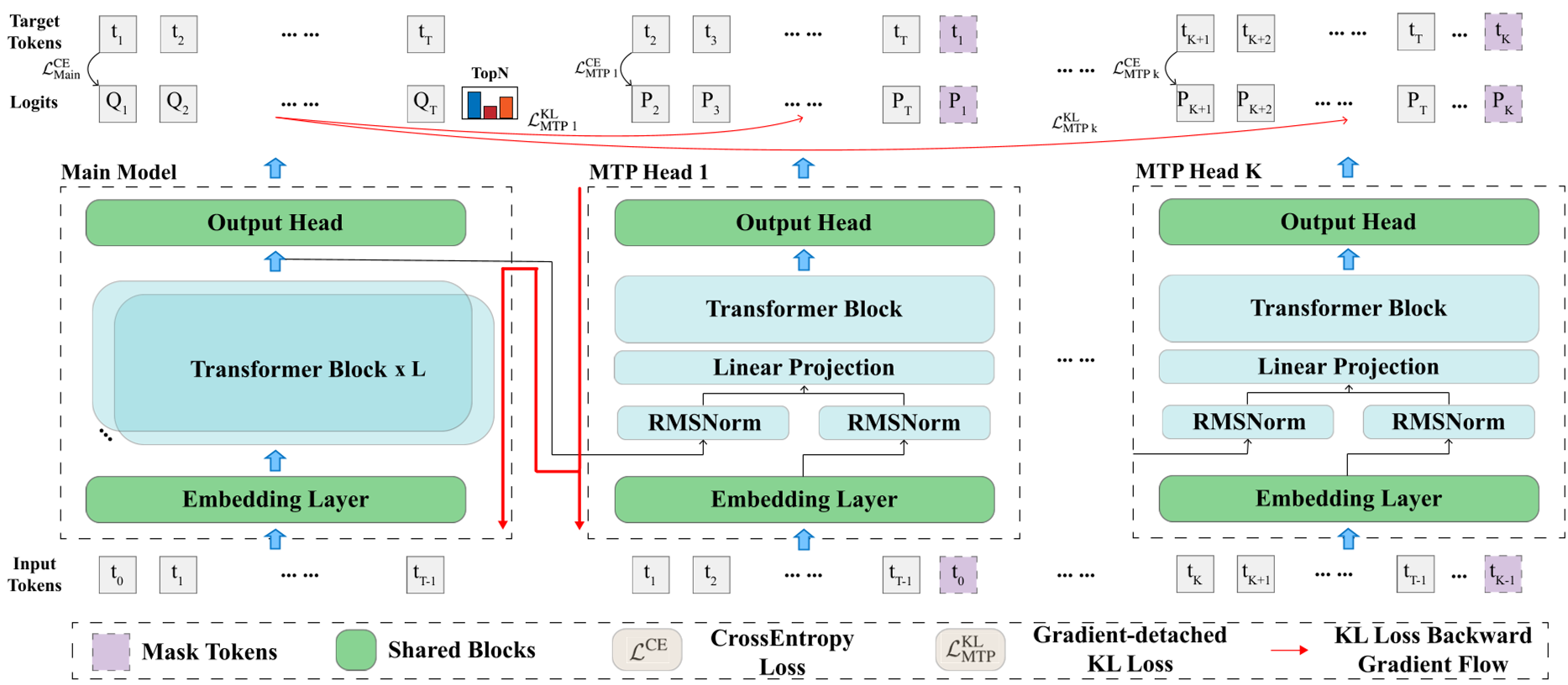 Figure 1: The MTP-D framework showing the red gradient-detached distillation path from the main head to MTP heads.
Figure 1: The MTP-D framework showing the red gradient-detached distillation path from the main head to MTP heads.
3. Looped Extension Strategy
Scaling from 1 to 16 heads is traditionally difficult. MTP-D introduces Looped Extension: taking a group of trained MTP heads ($1 \dots m$) and using them to initialize the next group ($m+1 \dots 2m$). By freezing the main head and previously trained heads, the model learns extended dependencies with minimal extra tokens (only 70B instead of the full 350B pre-training set).
Experiments & Results: Breaking the Speed Barrier
The method was validated on 2B Dense and A1B MoE models across seven benchmarks (GSM8K, MATH, TriviaQA, etc.).
- Acceptance Rate (AR) Boost: MTP-D consistently outperformed standard MTP, maintaining higher cumulative acceptance rates even as the head index increased.
- Inference Speedup: For a 4-head setup, MTP-D achieved a 1.23x speedup over standard 4-head MTP and a 2.07x speedup over 1-head MTP.
- Extreme Scaling: By looping up to 16 heads, the model reached a 220% speedup ratio, a significant milestone for speculative decoding research.
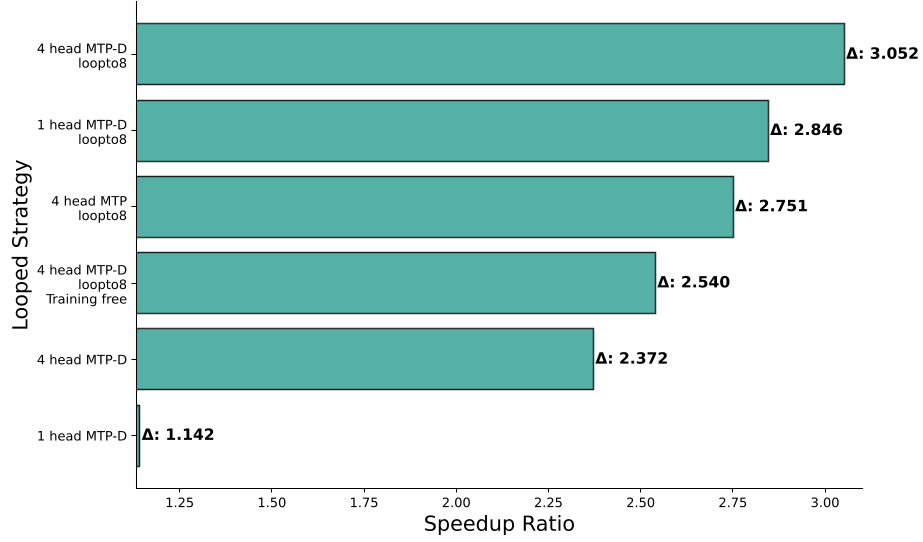 Figure 2: Speedup ratios across benchmarks showing MTP-D's superior scalability compared to standard MTP.
Figure 2: Speedup ratios across benchmarks showing MTP-D's superior scalability compared to standard MTP.
Critical Analysis & Conclusion
MTP-D demonstrates that distributional consistency is the secret sauce for speculative decoding. When the draft heads "think" like the main head—not just by predicting the ground truth but by matching the entire probability spread—the speculative decoding process becomes much more robust.
Takeaway: This work provides a template for industrial-scale LLMs to leverage MTP without sacrificing accuracy. Future work will likely look into post-training (SFT/RLHF) to see if these acceptance rates hold during chat and complex reasoning tasks.
Limitations: The study notes that while 16 heads are possible, the cascaded architecture still sees a gradual decline in marginal utility. Finding the "golden ratio" of heads to model size remains an open research question.