TACO (Terminal Agent Compression) is a plug-and-play, self-evolving framework designed to compress redundant terminal observations for long-horizon agentic tasks. By automatically discovering and refining structured compression rules, it achieves state-of-the-art performance gains (1%-4% accuracy increase) on benchmarks like TerminalBench 1.0/2.0 and SWE-Bench Lite while significantly reducing token overhead.
TL;DR
Terminal agents often get "lost" in the noise of verbose logs and build traces. TACO (Terminal Agent Compression) is a new self-evolving framework that treats context management as a dynamic learning task. By evolving a pool of semantic compression rules, TACO reduces token waste by 10% and boosts agent accuracy by up to 4%, enabling even small models to solve complex, long-horizon software engineering tasks.
The Bottleneck: The Quadratic Cost of Verbosity
When an AI agent interacts with a terminal, it receives raw output—sometimes thousands of lines of apt-get installation progress or make logs.
- The Context Saturation: These logs are 99% noise but consume the limited context window.
- The Quadratic Growth: As the conversation history grows, re-sending these logs at every step leads to a quadratic explosion in token costs.
- The Signal-to-Noise Problem: Critical error messages (the "Signal") are buried under megabytes of "Unpacking..." and "Setting up..." lines (the "Noise").
Prior methods used static truncation (cutting the middle) or fixed summaries, but terminal outputs are too heterogeneous for one-size-fits-all rules.
Methodology: Semantic Filtering through Self-Evolution
TACO introduces a plug-and-play adapter that sits between the terminal and the LLM agent. Its core innovation is a three-tier evolution process:
- Rule Initialization: Instead of starting from scratch, TACO uses a Global Rule Pool of proven compression patterns (e.g., how to handle
piporgitlogs). - Intra-Task Evolution: If an agent hits a new type of output (e.g., a specific binary disassembly), TACO invokes a "shadow LLM" to generate a regex-based compression rule on the fly.
- The Feedback Loop: If the agent complains ("Wait, I need to see the full output!"), TACO marks that rule as "over-aggressive" and refines it into a more conservative version.
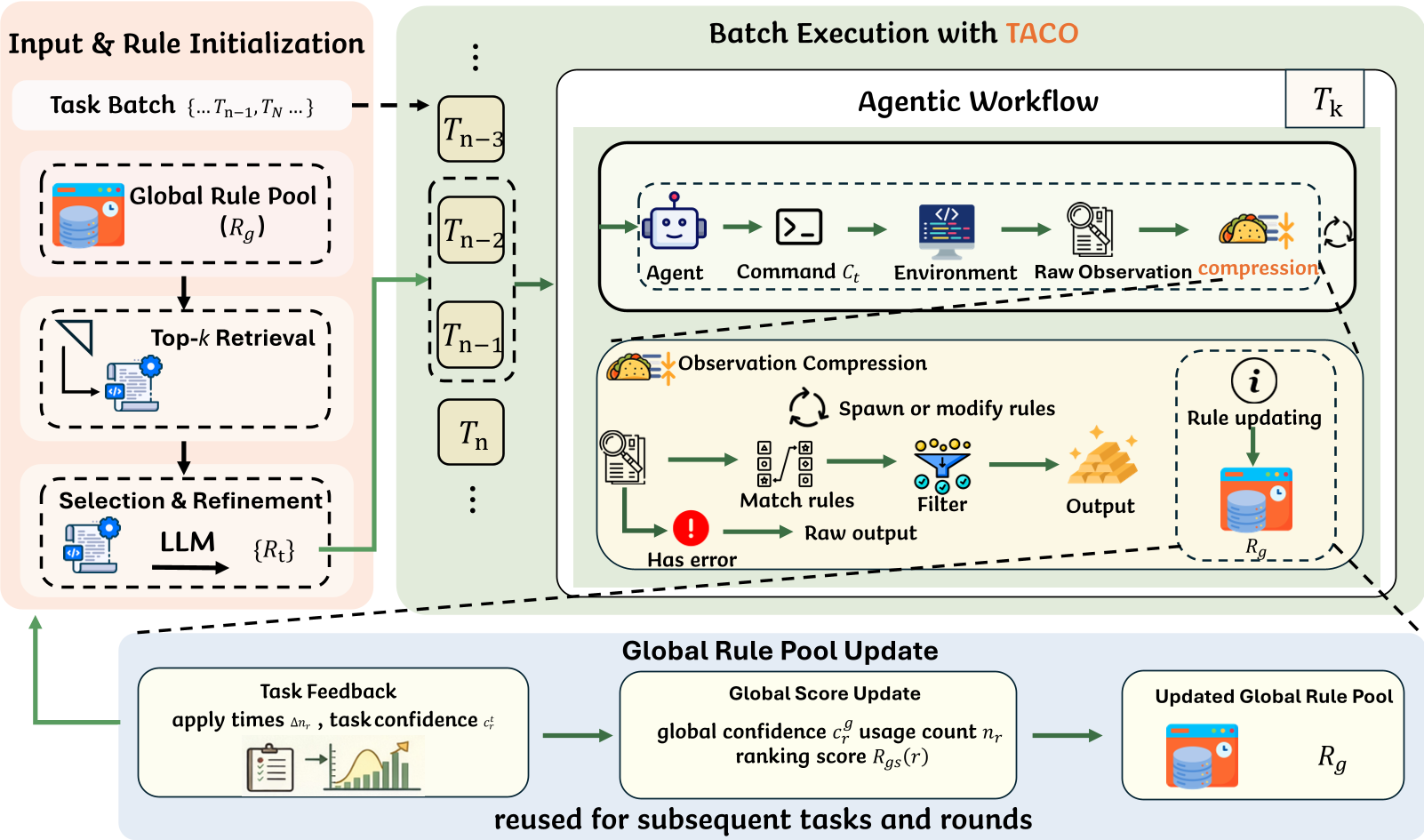 Figure 1: The TACO framework workflow, highlighting the Global Rule Pool and the online evolution mechanism.
Figure 1: The TACO framework workflow, highlighting the Global Rule Pool and the online evolution mechanism.
Experimental Results: Doing More with Less
The researchers tested TACO on TerminalBench (1.0 & 2.0) and SWE-Bench Lite using backbones from 8B to 1T parameters.
- Accuracy Boost: On TerminalBench 2.0, adding TACO consistently improved performance by 1-4%.
- Efficiency: For massive models like DeepSeek-V3.2 and MiniMax-M2.5, TACO reduced the "Token per Step" significantly.
- Empowering Small Models: Smaller models (Qwen-8B/14B) often fail early because their context overflows. TACO allowed these models to "stay in the game" longer, increasing their success rate by effectively cleaning their "working memory."
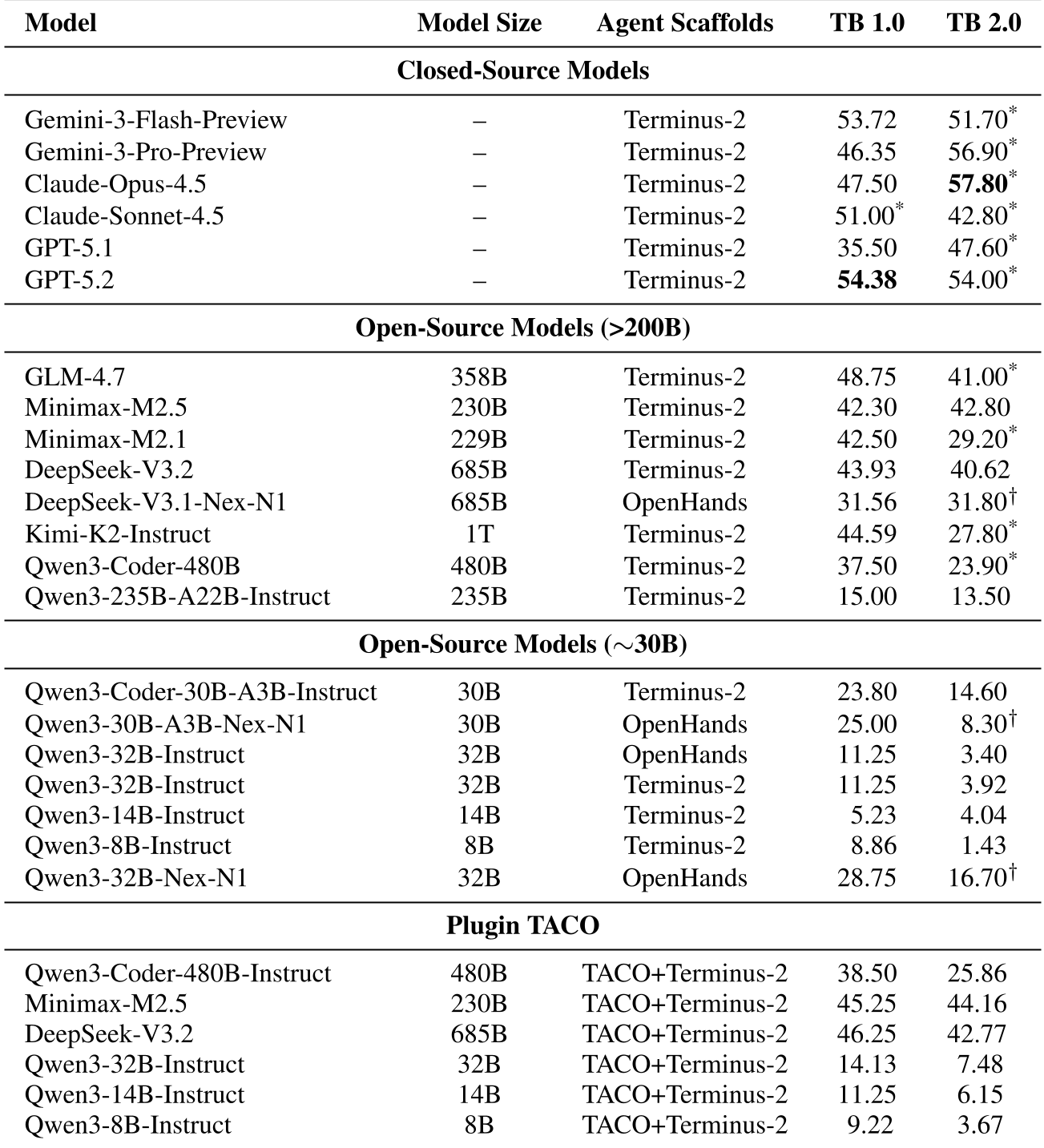 Table 1: Performance gains across various closed-source and open-source models.
Table 1: Performance gains across various closed-source and open-source models.
Visualizing the "Before & After"
A key example in the paper shows a 10,000-character apt-get log being compressed to just 73 characters. Crucially, the rule preserves the "Signal" (the final status of the installation) while discarding the repetitive "Unpacking..." lines.
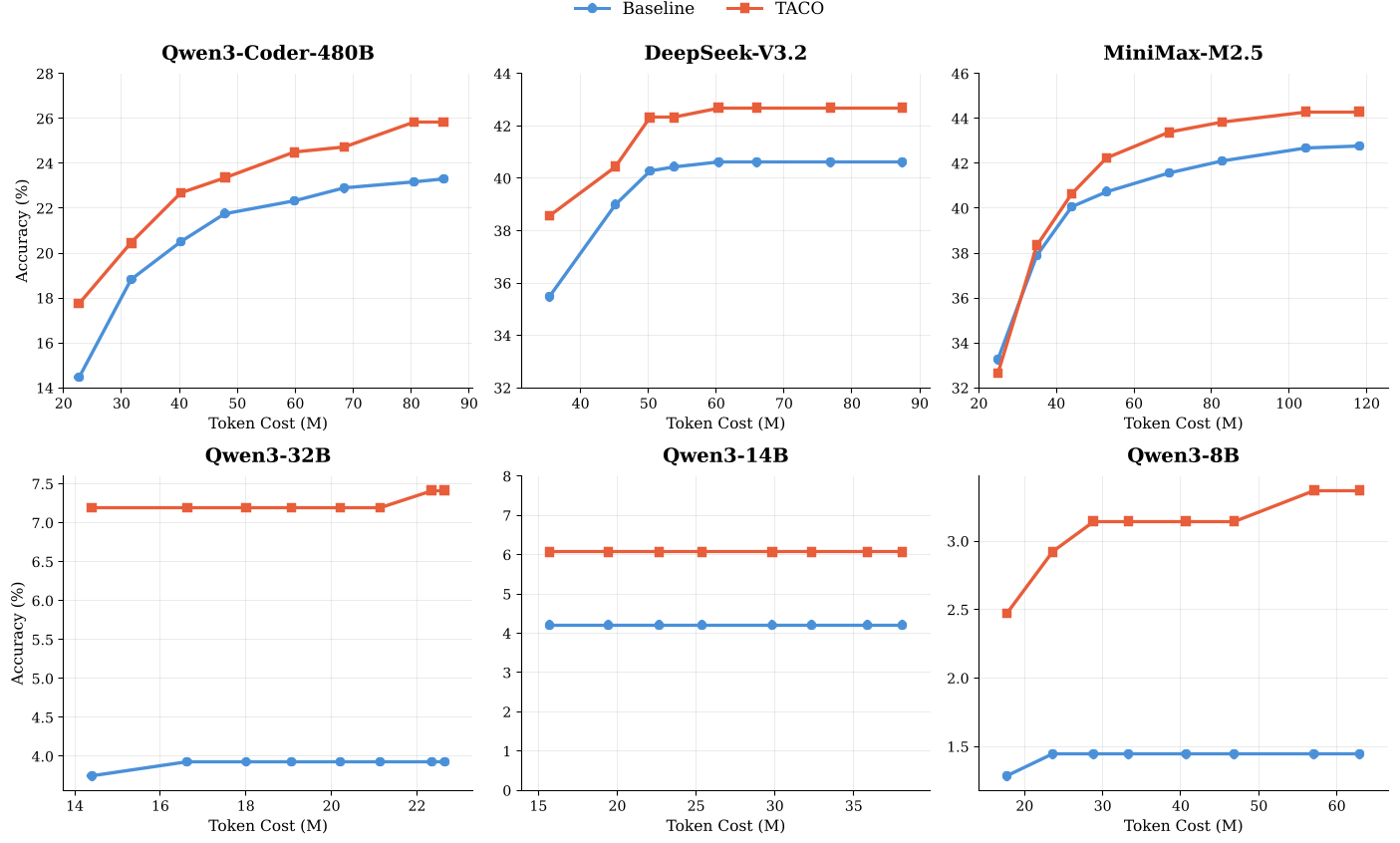 Figure 2: Accuracy vs. Token Budget. Under any fixed token budget, TACO-enabled agents outperform baseline agents.
Figure 2: Accuracy vs. Token Budget. Under any fixed token budget, TACO-enabled agents outperform baseline agents.
Critical Insight: Convergence and Stability
One of the most elegant parts of TACO is the Convergence Metric. By tracking the "Retention" of rules in the Top-K of the Global Pool, the system can determine when it has learned enough "wisdom" to handle a specific domain. The paper shows that once the rule frontier stabilizes, agent performance becomes significantly less volatile.
Conclusion & Future Work
TACO demonstrates that we don't necessarily need infinitely large context windows; we need smarter context management. By treating the terminal output as something that can be symbolically optimized through experience, TACO paves the way for persistent, lifelong-learning agents that get cheaper and smarter the more they interact with their environment.
Future research could extend this "observational compression" to GUI-based agents or multi-modal logs, where the "noise" is even more prevalent than in a text-based terminal.