本文由纽约州立大学石溪分校团队撰写,是一篇关于大语言模型(LLM)自我改进(Self-Improvement)的系统性技术综述。文章提出了一个涵盖数据获取、数据选择、模型优化、推理细化及自主评估五个阶段的闭环生命周期框架,旨在通过模型自主迭代突破人类评估瓶颈。
TL;DR
随着 LLM 性能逼近人类,人类反馈的边际回报正在递减。这篇来自石溪分校的 80+ 页重磅综述指出:LLM 的下一步不在于更多的人工标注,而在于构建一个闭环的自我改进生态系统。文章通过 GRO(生成-奖励-优化) 框架抽象了当前所有主流的自我演化路径,涵盖了从数据采集到测试时决策的各个环节。
核心定位
本研究是对 LLM 自我改进领地的全景图谱。它不仅讨论了简单的合成数据生成,更将其提升到了一个系统论的高度:如何在没有人类参与的情况下,让模型自主完成“学习-实践-反思-提升”的循环。
2. 为什么要搞“自我改进”?(动机与痛点)
传统 LLM 开发范式(Pretraining -> SFT -> RLHF)正撞上两堵墙:
- 数据墙:高质量、未经污染的互联网数据快被“吃光”了。
- 认知墙:如果模型以人为师,那么由于老师(人)的水平有上限,学生(模型)也很难青出于蓝。
自我改进的本质直觉:模型内部潜藏着尚未被激发出概率分布的“暗知识”。通过自我博弈(Self-play)或形式化验证(Verification),模型能把自己输出中正确、深刻的部分固化为模型权重,从而实现“左脚踩右脚上天”。
3. 自我改进生命周期框架 (Methodology)
作者将整个流程拆解为五个相互耦合的阶段,形成了一个闭环:
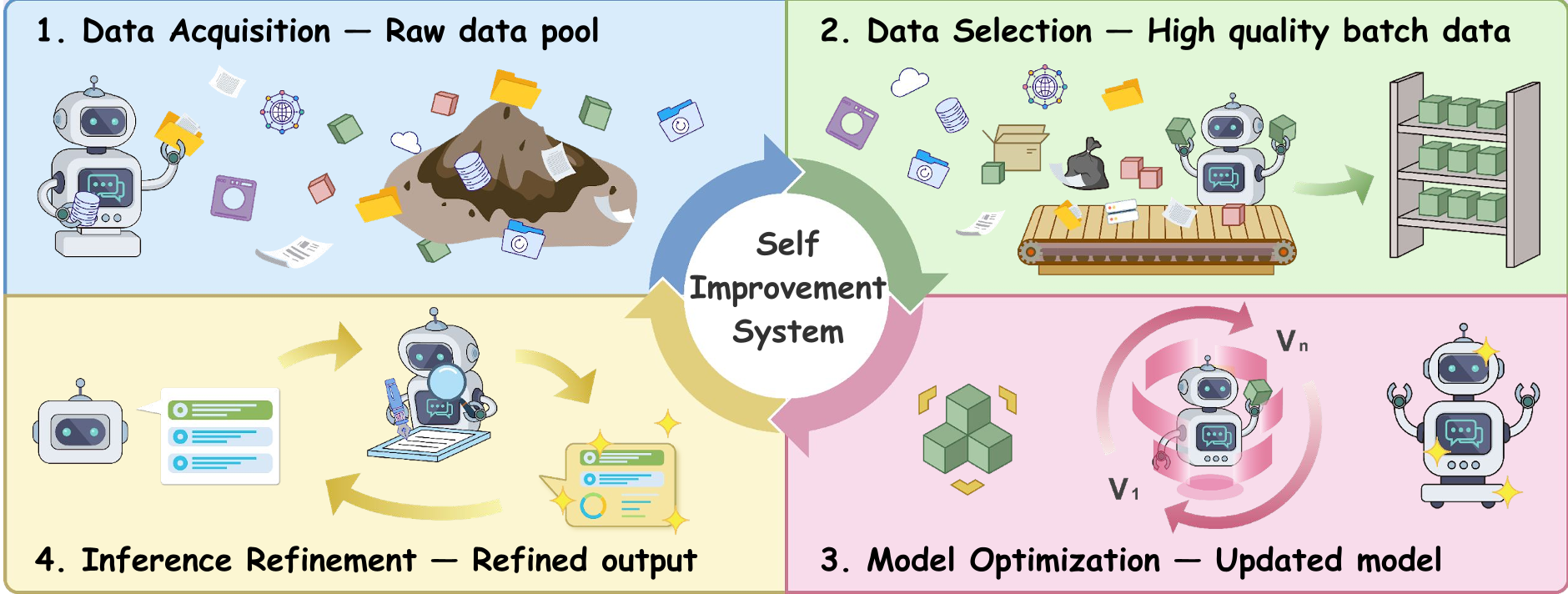
3.1 数据获取 (Data Acquisition)
模型不再是被动接受语料,而是:
- 静态清理:用大模型给网页数据打分(如 FineWeb-Edu)。
- 环境交互:模型在沙盒、编译器中运行代码,学习真实的执行反馈。
- 合成生成:通过 Self-Instruct 等技术,模型作为“种子”生成全新的指令集。
3.2 自适应数据选择 (Data Selection)
并非所有的合成数据都是好的。
- 度量引导:使用 Perplexity 或 Loss 来挑选对模型增量最大的样本。
- Adaptive Selection:引入 learnable selector。就像一个聪明的陪练,根据模型现在的水平,动态调整训练题库的难度。
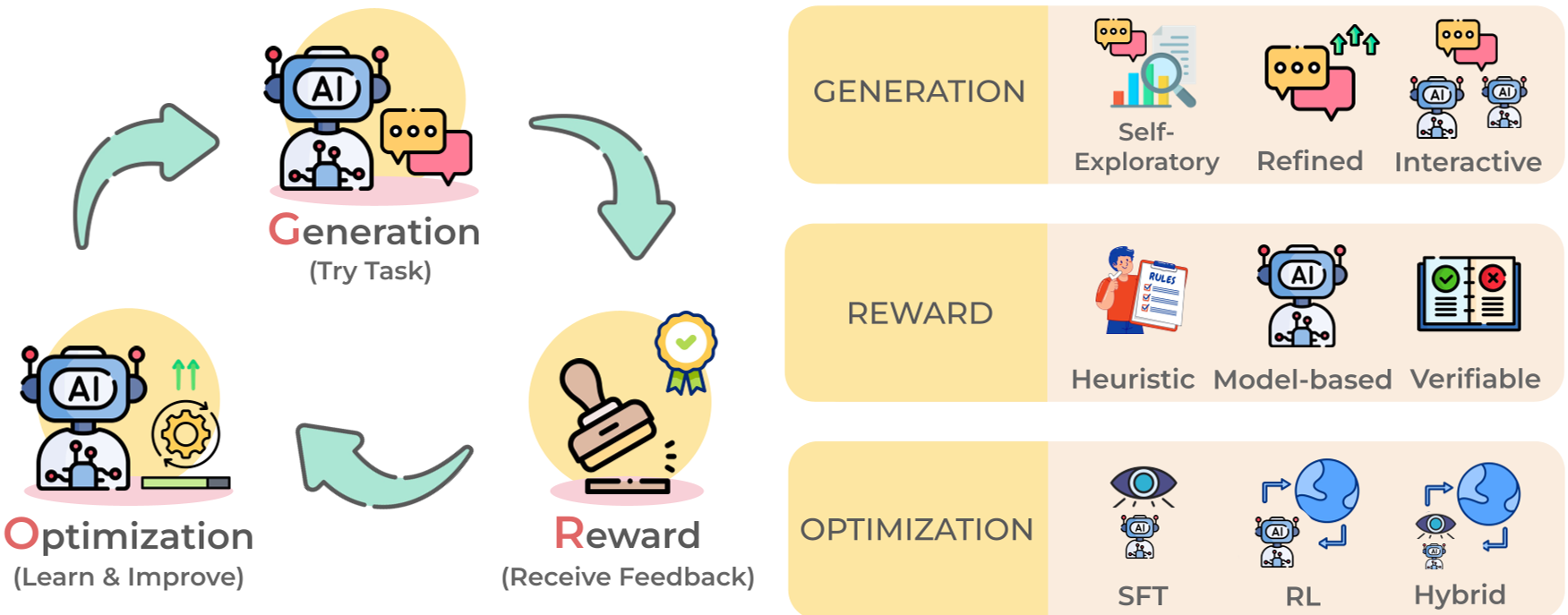
3.3 模型优化 (Optimization - The Core GRO Framework)
文章提出了万能公式:Generation -> Reward -> Optimization。
- Generation:自发搜索或精细化增强。
- Reward:不仅仅是分类器,更多依赖于形式化验证(Verification),比如代码是否跑通、数学答案是否正确。
- Optimization:通过 DPO、PPO 或最新的 GRPO(如 DeepSeek-R1 采用的算法)来学习奖励信号。
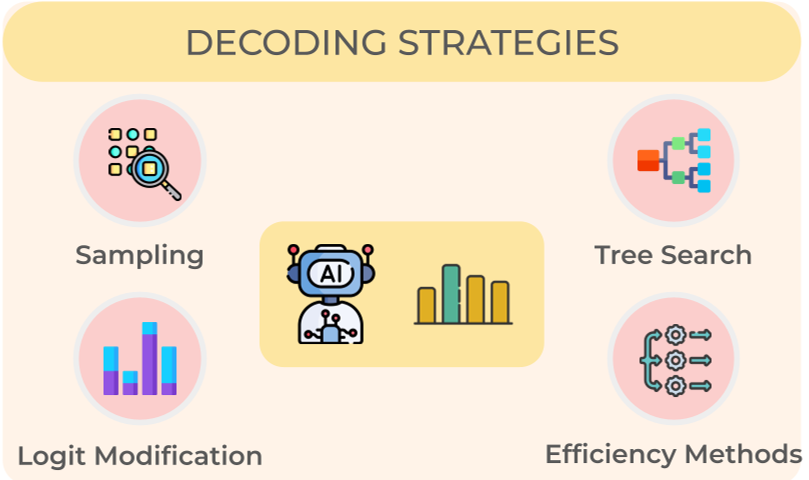
3.4 推理细化 (Inference Refinement)
这部分讨论了近期最火的“推理性模型”逻辑:
- 测试时计算缩放(Test-time Scaling):既然训练不动了,那就让模型在回复前多想一会。
- MCTS (蒙特卡洛树搜索):在对话中不断回溯和寻找最优路径。
4. 实验结果与行业战绩
通过对各环节的量化调研发现:
- 数据质量 > 数量:DCLM 实验证明,优秀的筛选模型能让模型在更少的数据上达成更强的 MMLU 表现。
- 自我博弈(Self-play)的神话:如 SPIN 和 DeepSeek-R1,证明了即便没有外部指令,单纯通过强化学习也能演化出极强的推理能力。
5. 深度洞察:自我改进还没解决的问题
作为资深主编,我必须指出论文提到的几个“致命伤”:
- 数据自噬(Data Autophagy):如果模型一直吃自己拉出来的“合成屎”,最终会导致模型分布偏离现实,产生“模型坍塌(Model Collapse)”。
- 奖励黑客(Reward Hacking):模型可能会学会钻奖励函数(Reward Model)的空子,给出一个看起来很对但逻辑错误的离谱答案。
- 生成的真实性 GAP:模型判别对错的能力(Verifier)必须远强于生成能力,否则自我改进就会变成“瞎子带路”。
6. 总结与未来展望
论文最后给出了非常深刻的启示:未来的顶级模型将不再是静态的权重文件,而是具备自我更新能力的智能体(Agentic System)。
关键 takeaway:
- 强化学习(RL)是连接合成数据与模型能力跨越的唯一桥梁。
- “测试时推理”将是未来 AI 差异化竞争的核心。
- 自主评估将成为替代固定 Benchmarks 的必经之路。
本文基于 arXiv 论文 《Self-Improvement of Large Language Models: A Technical Overview and Future Outlook》 编写。