SelfTTS is a VITS-based end-to-end text-to-speech framework designed for cross-speaker style transfer that achieves emotional expressivity in neutral speakers without external pre-trained encoders. It introduces Multi Positive Contrastive Learning (MPCL) and a cosine-based Gradient Reversal Layer (GRL) for explicit disentanglement, reaching state-of-the-art emotional naturalness (eMOS 2.85).
TL;DR
Achieving high-fidelity emotional speech for a speaker who only provided neutral recordings (Cross-Speaker Style Transfer) is a holy grail in TTS. SelfTTS breaks new ground by eliminating the need for external pre-trained encoders. By using a novel Multi Positive Contrastive Learning (MPCL) loss and Explicit Embedding Disentanglement, it creates a purer separation between "who is speaking" and "how they feel," resulting in SOTA emotional naturalness.
Background: The "Speaker Leakage" Dilemma
In traditional style transfer, we extract a "style embedding" from a reference audio and inject it into a target speaker's voice. However, the model often gets confused: it accidentally grabs the reference speaker’s voice pitch or timbre along with the emotion. This is Speaker Leakage.
Previous attempts used Gradient Reversal Layers (GRL) to "forget" the speaker identity, but if your dataset only has one person who sounds "angry," the model can't distinguish between the "angry" label and that person's specific voice.
Methodology: Engineering the Perfect Latent Space
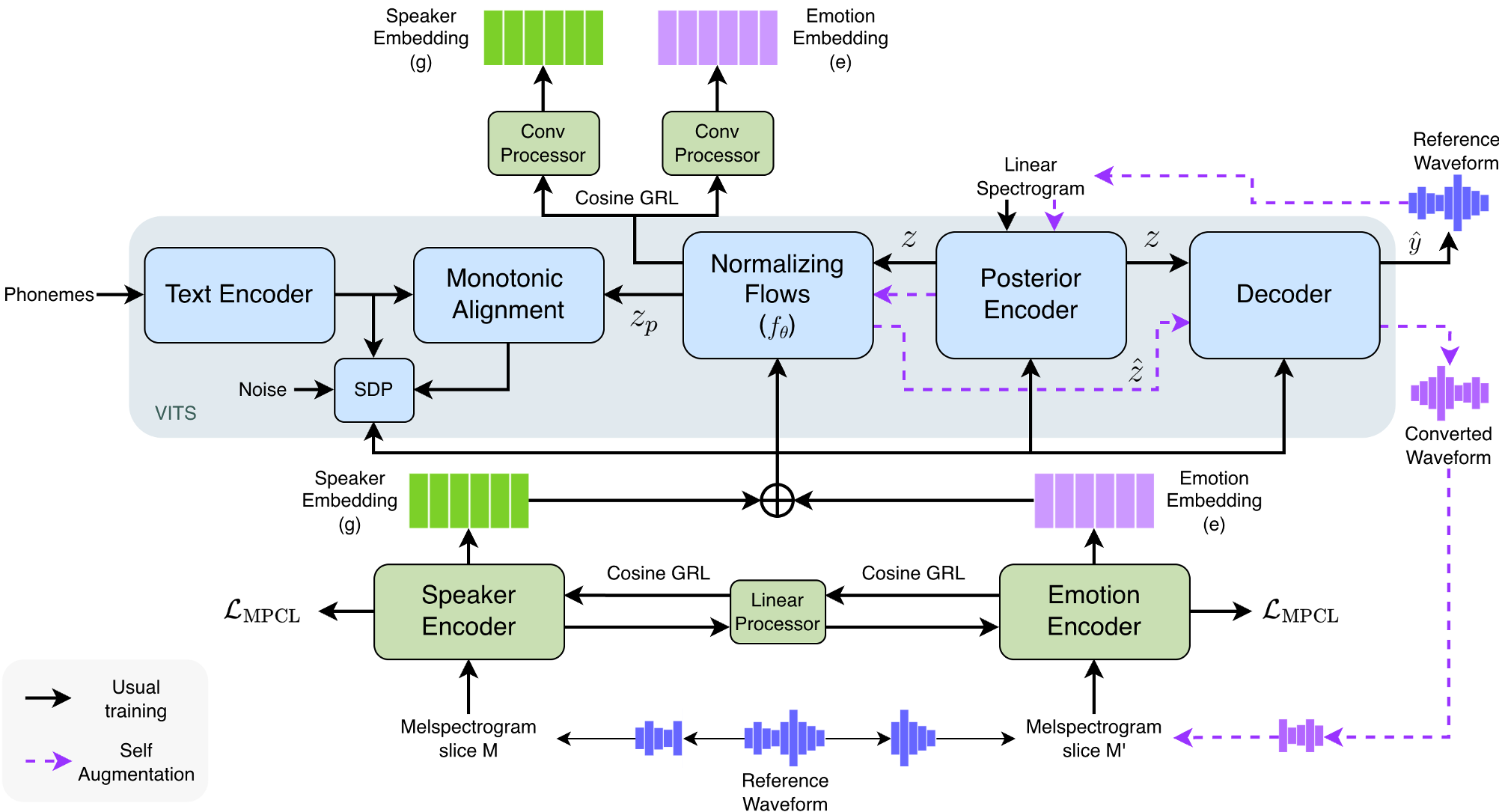
SelfTTS is built on the VITS architecture but introduces three critical innovations:
1. Multi Positive Contrastive Learning (MPCL)
Instead of simple classification, SelfTTS uses MPCL to pull embeddings of the same emotion closer together and push different emotions further apart in the latent space. This creates distinct "clusters" of emotions that are easier for the model to navigate during inference.
2. Explicit Embedding Disentanglement
This is the "secret sauce." Instead of using a standard classifier with GRL, the authors apply a cosine similarity loss between the emotion and speaker embeddings through a GRL.
- The Intuition: If the cosine similarity is high, the embeddings are "looking" in the same direction—meaning they are entangled. By reversing this gradient, the model is forced to make the vectors orthogonal (independent), ensuring the emotion encoder only captures emotion.
3. Self-Augmentation (Self-Refinement)
Since VITS is essentially a Voice Conversion (VC) engine, the authors used the model to "convert" its own expressive training data into different voices. They then re-fed this synthetic data back into the training loop. This "Self-Augmentation" helps the model see the same emotion across many different "fake" voices, significantly improving the naturalness of the final output.
Experimental Triumphs
The researchers compared SelfTTS against heavyweights like VECL and E3-VITS.
- Emotional Expressivity (eMOS): SelfTTS achieved 2.85, significantly higher than VECL (2.55) and E3-VITS (2.23).
- Disentanglement: Using Centered Kernel Alignment (CKA), they proved that their cosine-based GRL reduced entanglement to a near-zero score (0.0139), whereas standard methods were much higher.
- Visual Proof: UMAP projections show that SelfTTS creates much cleaner, disjoint emotional clusters compared to the overlapping "clouds" produced by baselines.
 Figure: The clear separation of emotions (Neutral, Happy, Angry, etc.) in the SelfTTS latent space.
Figure: The clear separation of emotions (Neutral, Happy, Angry, etc.) in the SelfTTS latent space.
Critical Insight & Future Outlook
The most fascinating takeaway is that Naturalness and Emotional Adherence often trade off. As shown in the ablation studies, when the model was forced to be extremely expressive, the perceived quality (UTMOS) sometimes dipped. However, by adding the Self-Augmentation stage, the authors managed to claw back that naturalness without losing the emotional "punch."
Limitations: The model still struggles with "Cross-Corpus" scenarios (e.g., training on one dataset and testing on audio recorded in a different room). Future iterations will likely need to address acoustic environment normalization to make this truly production-ready for zero-shot "in-the-wild" applications.
Conclusion
SelfTTS proves that you don't need massive, pre-trained "black box" encoders to achieve great style transfer. Mathematical rigor in disentanglement and clever use of a model's own generative capabilities (Self-Refinement) can outperform more complex, data-hungry baselines.