SG-VLA is a specialized Vision-Language-Action model designed for mobile manipulation in complex household environments. By integrating multi-view RGB-D inputs and a suite of auxiliary decoders, it achieves a 73% success rate on the ManiSkill-HAB benchmark, significantly outperforming standard imitation learning baselines.
TL;DR
SG-VLA tackles the "embodiment gap" in Vision-Language-Action models. While models like OpenVLA excel at understanding what an object is, they often struggle with where it is in a 3D mobile context. By introducing multi-view RGB-D perception and a progressive auxiliary co-training scheme, SG-VLA transforms a standard VLM into a spatially-aware controller capable of complex household rearrangement with a 13-DoF mobile platform.
The "Spatial Blindness" of Standard VLAs
Most current VLA models are "tabletop champions." They operate in constrained spaces where the camera is fixed and the action space is limited to a single arm. When moved to a mobile robot in a house (like the ManiSkill-HAB environment), these models face three critical failures:
- Partial Observability: A single head camera cannot see the "hand-object" interaction point and the global layout simultaneously.
- Dimension Explosion: Controlling base motion, torso height, arm joints, and grippers (13 dimensions) simultaneously is too complex for simple imitation.
- Weak Supervision: Directly regressing actions from pixels is a "sparse" signal. The model doesn't inherently learn the robot's kinematics or object geometry.
Methodology: Spatially-Grounded Architecture
SG-VLA re-engineers the VLA pipeline by focusing on Representation Quality.
1. Multi-Modal Sensory Fusion
The model doesn't just look; it perceives depth. By fusing DINOv2 (spatial features) and SigLIP (semantic features) across both Head and Hand cameras, the model gains a stereoscopic-like understanding of the scene.
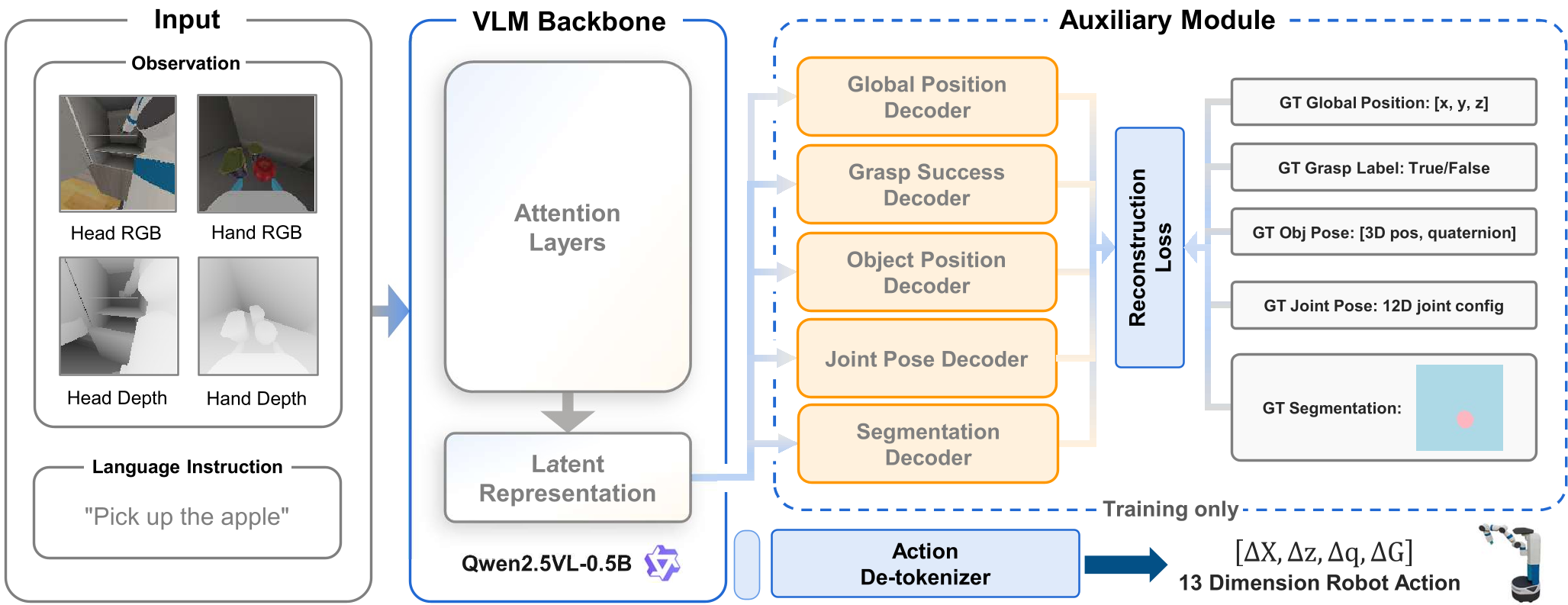
2. The Auxiliary Decoder Suite
To force the LLM backbone (Qwen2.5-0.5B) to "understand" physics, researchers attached five specialized decoders that reconstruct:
- Global Position: Where is the robot in the house? (Navigation awareness)
- Joint Configuration (qpos): What is the current arm state? (Kinematic awareness)
- Segmentation Masks: Which pixels belong to the target? (Object grounding)
- Object Pose & Grasp State: Is the object held correctly? (Manipulation awareness)
3. Progressive Training: Solving the "Gradient Noise" Problem
A key insight of the paper is that naive co-training fails. Randomly initialized decoders send "garbage" gradients to the pre-trained VLM, destroying its semantic knowledge. SG-VLA uses a Two-Stage approach:
- Stage 1: Freeze the VLM backbone; let decoders learn to "read" the existing features.
- Stage 2: Unfreeze and jointly refine, allowing the auxiliary tasks to fine-tune the backbone for spatial tasks.
Experimental Breakthroughs
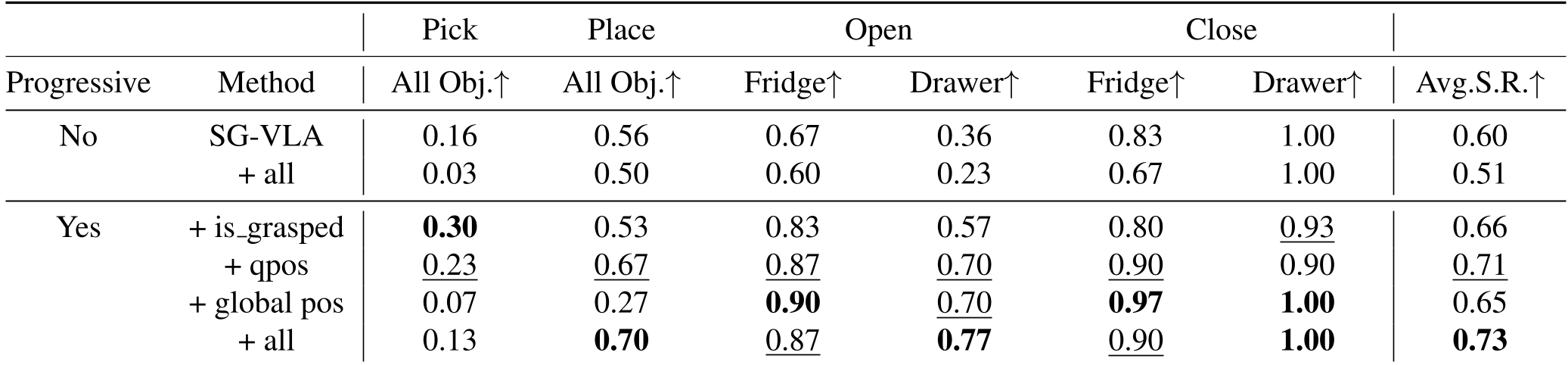
The results on the ManiSkill-HAB benchmark highlight a clear hierarchy of needs for mobile robots:
- Perception is King: Moving from single-view RGB to multi-view RGB-D improved the success rate of the OpenVLA baseline from a dismal 4% to 32%.
- Auxiliary Tasks Work: Adding the full suite of decoders pushed the final success rate to 73%.
- Kinematics Matter: Reconstructing the
qpos(joint angles) was the most impactful individual auxiliary task, especially for precision maneuvers like opening drawers.
Discrete vs. Continuous: The Action Head Debate
The authors also experimented with a Flow Matching Action Expert (similar to $\pi_0$). Interestingly, while the continuous expert doubled success in Pick tasks (0.13 $\rightarrow$ 0.27), it actually hindered Opening tasks. This suggests that complex navigation/manipulation hybrids might benefit from task-adaptive control—switching between "decisive" discrete tokens and "precise" continuous flows.
Critical Insight & Conclusion
SG-VLA proves that the "Action" in VLA isn't just a linguistic output; it is a physical manifestation that requires dense spatial grounding. By "forcing" the model to perform auxiliary perception tasks, the latent space becomes structured by the laws of geometry rather than just the statistics of text.
Future Outlook: The next frontier will be moving this "Spatially-Grounded" approach from simulation into real-world unstructured homes, where depth sensors are noisier and "Segmentation" is not a free ground-truth label.