本文通过解析高维两层 ReLU 神经网络的群体损失(Population Loss)景观,提出了一种基于统计量(Summary Statistics)的精确低维表征方法。研究揭示了局部极小值如何随网络宽度的增加(从恰好参数化到过参数化)从孤立点演变为连续流形,并揭示了过参数化消除由于对称性破缺产生的“伪解”的几何机制。
TL;DR
神经网络的训练就像在崎岖的山脉中寻找低谷。长期以来,我们知道增加网络宽度能让训练变容易,但其内部几何原理一直像个黑盒。本文通过一套基于统计物理的数学工具,精准刻画了两层 ReLU 网络的“损失景观地图”。研究发现:过参数化(Overparameterization)会触发景观的“拓扑相变”——曾经死锁的孤立陷阱(Local Minima)会在多余维度的作用下融化、连接,最终形成通往全局最优的平坦高速公路。
背景定位:从“均值场”到“真实宽度”
过去几年的主流理论(如 Mean-field 理论)主要处理“无限宽”的情况。虽然它们证明了无限宽时优化是凸的,但在工程实践中,我们更关心有限宽网络的变化。早在 2018 年,Safran 等人就通过实验指出局部极小值广泛存在,但这些陷阱长什么样?为什么稍微加宽一点,它们就“消失”了?本文正是要通过“宏观表征”来回答这个微观问题。
痛点深挖:被对称性诅咒的“伪解”
在两层 ReLU 网络中,由于神经元的排列组合对称性(Permutation Symmetry),理论上存在无数个等价的解。
- 恰好参数化(Well-specified):当学生神经元数量 等于教师数量 时,这些对称解是互相孤立的。如果你不幸掉进了一个“反向对齐”的神经元组合(Anti-aligned),你就被困在了一个高损失的“孤立岛屿”上。
- 研究直觉:作者认为,局部极小值其实是一种“补偿机制”。当某些神经元学歪了,剩下的神经元会努力调整大小来抵消错误。这种互相牵制的平衡状态,就是那个让我们头疼的“局部极小值”。
核心方法:统计量的宏观规约
作者没有直接去数数百万维的权重空间,而是提取了三个核心序参数(Summary Statistics):
- 矩阵:学生神经元之间的重合度。
- 矩阵:学生与教师(目标)神经元之间的重合度。
- 矩阵:教师神经元自身的结构。
通过这组低维表征,作者推导出了高维景观的运动方程。
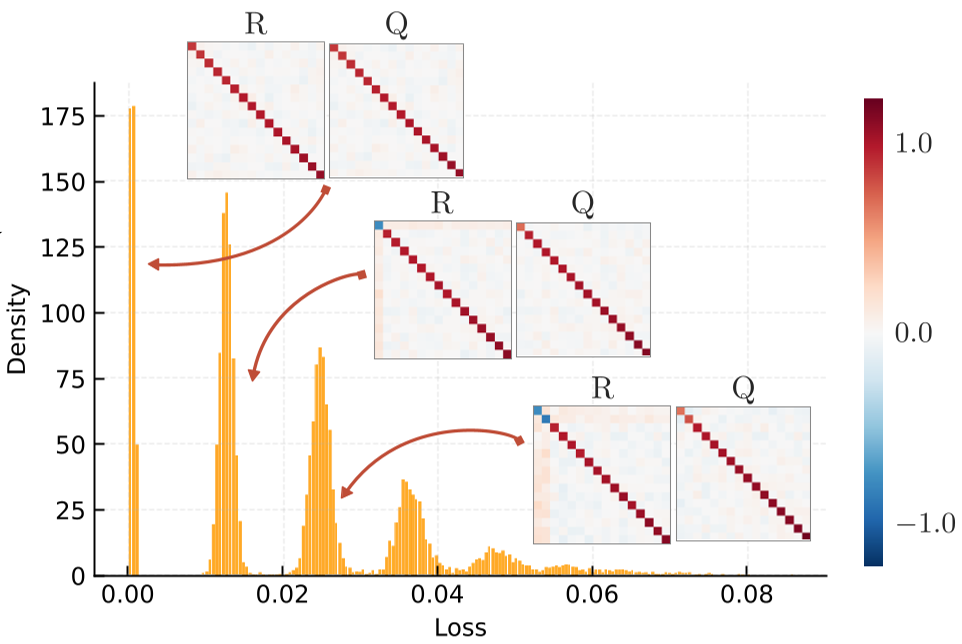 左图显示了恰好参数化时的孤立极小值,右图展示了过参数化如何将它们连成一片。
左图显示了恰好参数化时的孤立极小值,右图展示了过参数化如何将它们连成一片。
景观演化:从孤立点到平坦流形
这是本文最惊人的发现:
- 在 时,损失景观由一系列离散的“台阶”组成。你的最终损失值不是连续分布的,而是像量子能级一样,取决于你有几个神经元“反向对齐”了。
- 在 时,哪怕只多一个神经元(),就会引入额外的自由度(Neuron Splitting)。
作者使用了 String Method(弦方法) 来测试两个对称解之间的连通性。
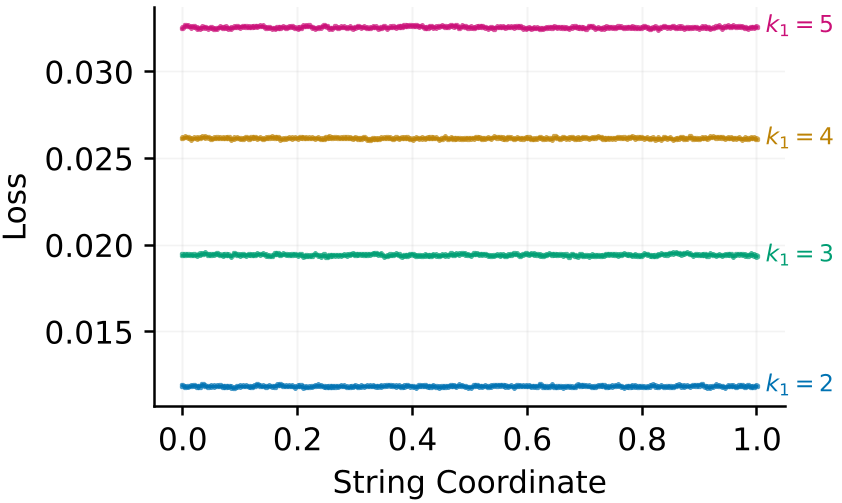 图中紫色的平坦曲线证明:在过参数化后,两个极小值之间的路径电位是完全平坦的,障碍消失了!
图中紫色的平坦曲线证明:在过参数化后,两个极小值之间的路径电位是完全平坦的,障碍消失了!
实验战绩:不仅仅是快一点
研究通过对 10,000 次随机初始化路径的追踪,验证了理论的准确性:
- 能级量子化:实验中观察到的损失值分布(Loss Histograms)与理论预测的离散能级完全一致。
- 过参数化效率:
- 当 时,只有约 13% 的初始化能找到全局最优。
- 当 时,几乎 100% 的轨迹都滑向了全局最优。
- 算法普适性:该理论不仅适用于简单的梯度下降(GD),通过修改 ODE 分量,还成功预测了带约束的梯度下降(nGD, onGD)为什么更容易失败——因为约束强制打破了由于平坦方向带来的连通性。
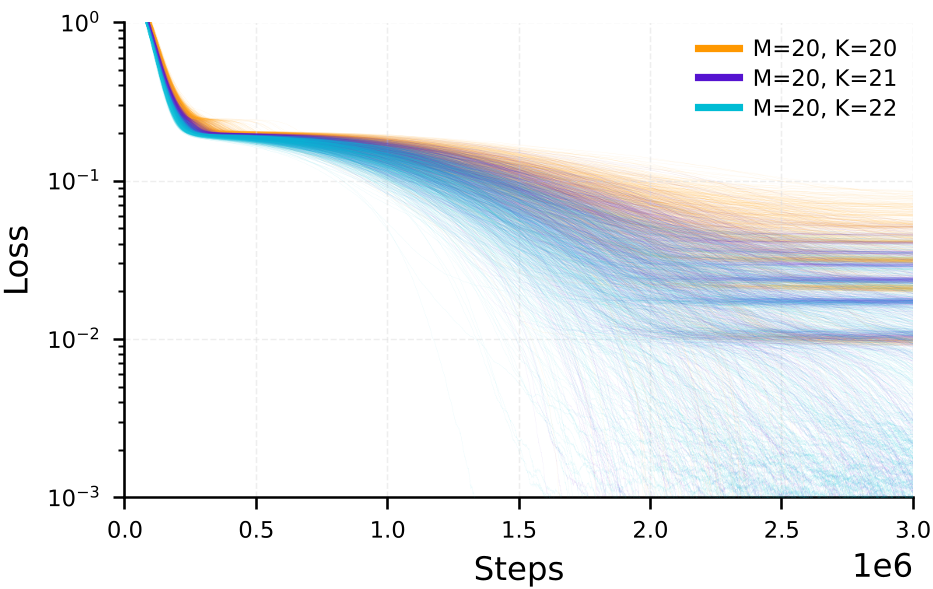 可以看到,随宽度增加,高能级的“平台”逐渐变得不稳定,系统像滑梯一样滑向底部。
可以看到,随宽度增加,高能级的“平台”逐渐变得不稳定,系统像滑梯一样滑向底部。
深度洞察:对未来的启示
这项工作的核心价值在于它用数学证明了:宽度(Width)不是简单的计算资源浪费,它是景观的“降解剂”。对于 ReLU 这种非光滑非线性的模型,微小的维度增加就能导致定性的景观突变。
局限性:目前分析主要基于两层结构和高斯输入。在真实的多层网络(Deep Networks)和高度结构化的非高斯数据中,这种“极小值融合”的阈值是多少,仍是待解之谜。
总结 (Takeaway):这篇论文提醒我们,与其追求复杂的初始化技巧,不如通过适度的过参数化来“改善地形”,让优化器自己找到出路。