ShotStream is a novel causal multi-shot video generation architecture designed for interactive storytelling, enabling the synthesis of long narrative videos shot-by-shot. By reformulating video generation as an autoregressive next-shot task, it achieves high-fidelity results with a throughput of 16 FPS on a single GPU, significantly outperforming previous bidirectional SOTA models in latency.
TL;DR
Generating long-form, multi-shot videos has traditionally been a choice between "high quality but slow" (bidirectional models) or "fast but inconsistent" (simple autoregressive rollouts). ShotStream changes the game by introducing a causal architecture that generates cinematic sequences shot-by-shot at 16 FPS. By using a dual-cache system and a clever two-stage distillation strategy, it allows users to "direct" a video in real-time using streaming prompts.
The Interactivity Bottleneck
Current SOTA models like HoloCine or LCT treat video as a single, bidirectional block. While this ensures the end of the video knows what happened at the beginning, it creates two massive problems:
- Zero Interactivity: You can't change your mind halfway through. If you want to change the third shot, you have to re-render the whole thing.
- Quadratic Latency: As the video gets longer, the attention mechanism slows down exponentially.
ShotStream’s core insight is to treat filmmaking as Next-Shot Prediction. By making the model "causal" (only looking at the past), we can input prompts on-the-fly, much like telling a story one sentence at a time.
Methodology: The Dual-Cache & Distillation Engine
To make a causal model work without losing its "memory" of the scene, the authors introduced a sophisticated architectural and training pipeline.
1. Dual-Cache Memory
How do you keep the characters consistent across cuts while keeping the movement smooth within a single shot?
- Global Context Cache: Stores a sparse selection of frames from all previous shots (inter-shot consistency).
- Local Context Cache: Stores the most recent frames of the current shot (intra-shot consistency).
- RoPE Discontinuity: To prevent the model from getting confused between the "history" and the "present," they inject a mathematical "jump" in the Rotary Positional Embeddings at every shot boundary.
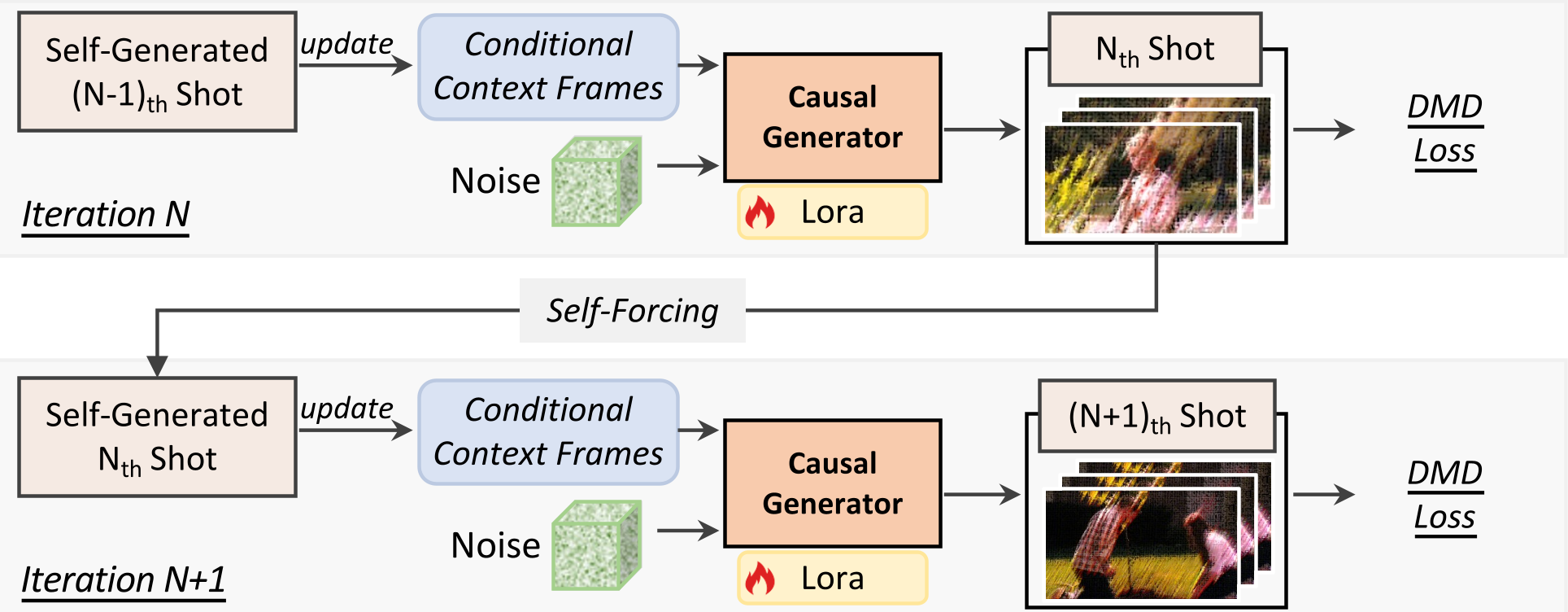 Figure: The Causal Architecture showing the Global/Local cache separation and the two-stage distillation pipeline.
Figure: The Causal Architecture showing the Global/Local cache separation and the two-stage distillation pipeline.
2. Two-Stage Distillation
Training a fast model (4 steps) to behave like a slow, high-quality teacher (50 steps) is hard. ShotStream uses Distribution Matching Distillation (DMD) with a twist:
- Stage 1 (Intra-shot): The model learns to generate the current shot piece-by-piece using perfect "ground-truth" history.
- Stage 2 (Inter-shot): The "Training-Inference Gap" is closed by forcing the model to generate new shots based on its own (potentially imperfect) previous generations. This builds robustness against error accumulation.
Experimental Performance: SOTA Results
ShotStream was tested against heavyweights like Mask2DiT and Rolling Forcing. The results are decisive:
- Efficiency: 15.95 FPS vs. 0.149 FPS (Mask2DiT). That is a 100x+ speedup over some bidirectional models.
- Consistency: Despite being faster, it scored higher in Subject and Background consistency (0.825 and 0.819 respectively) than any other baseline.
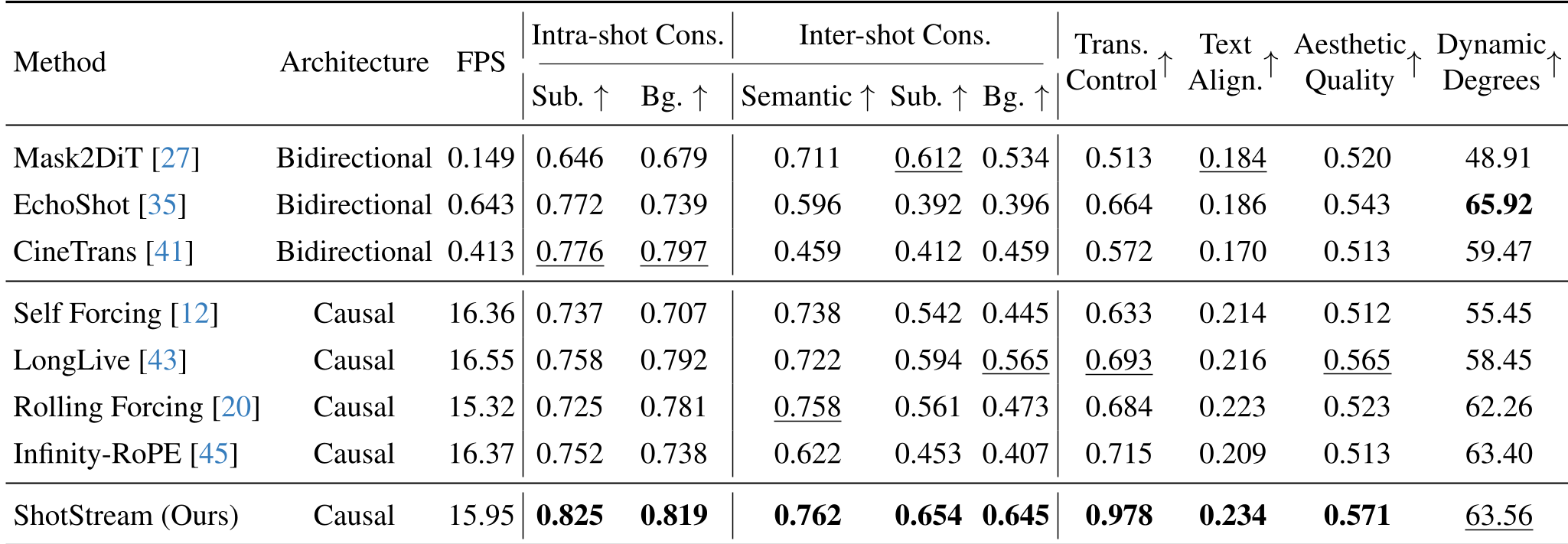 Table: ShotStream dominates across consistency, alignment, and speed metrics.
Table: ShotStream dominates across consistency, alignment, and speed metrics.
Visual Evidence
The model demonstrates an uncanny ability to maintain character identity across radical camera angle changes—a feat typically reserved for much heavier, non-interactive models.
 Figure: A 5-shot sequence showing stable narrative and visual style across 405 frames.
Figure: A 5-shot sequence showing stable narrative and visual style across 405 frames.
Critical Analysis & Future Outlook
While ShotStream is a breakthrough for real-time applications, it isn't perfect. The authors admit to artifacts when prompts become extremely complex, likely due to the 1.3B parameter base model size. Scaling this to a 10B+ parameter model (like Sora-scale) could potentially eliminate these glitches.
The Takeaway: ShotStream proves that "streaming" video is the future. By moving away from "monolithic" generation and adopting "causal" generation, we pave the way for AI-driven video games and interactive cinema that reacts to user input in sub-second intervals.