SIMART is a unified Multimodal Large Language Model (MLLM) designed to decompose monolithic 3D meshes into simulation-ready articulated assets. It integrates a novel Sparse 3D VQ-VAE with the Qwen3-VL backbone to jointly perform part-level segmentation and kinematic parameter prediction (URDF generation), achieving state-of-the-art results on the PartNet-Mobility and the newly proposed SIMART-Bench.
Executive Summary
TL;DR: SIMART is a breakthrough framework that takes a "dumb" static 3D mesh and "breathes life" into it by automatically identifying its moving parts and kinematic logic. By utilizing a Sparse 3D VQ-VAE, it circumvents the memory bottlenecks of dense 3D grids, reducing token overhead by 70% while achieving SOTA precision in URDF (Unified Robotics Description Format) generation.
Background Positioning: In the landscape of 3D vision, we are moving from static "looking" to functional "interacting." SIMART sits at the frontier of Embodied AI, acting as the bridge that converts raw AIGC-generated meshes into interactive assets ready for physics engines like NVIDIA Isaac Sim.
Problem & Motivation: The "Token Tax" of 3D Space
The industry has reached a point where generating a high-quality static mesh is relatively easy (e.g., Hunyuan3D). However, these meshes are monolithic blobs. To make them "sim-ready," you need to know: What is the door? Where is the hinge? What is the rotation limit?
Prior works faced a "dual-trap":
- Multi-stage Failure: Decoupling segmentation from joint estimation leads to "kinematic drift"—where the predicted joint doesn't match the actual geometry.
- Voxel Inefficiency: Representing 3D space with dense voxels (as in ShapeLLM) scales at $O(N^3)$. Most of a 3D bounding box is empty air, yet dense models waste thousands of tokens processing this "nothingness," leading to Out-of-Memory (OOM) errors for complex objects.
Methodology: The Core Architecture
The genius of SIMART lies in its efficiency-first approach to 3D geometry.
1. Sparse 3D VQ-VAE
Instead of encoding the entire $64^3$ grid, SIMART's encoder only quantizes occupied surface voxels. It introduces a reserved Zero Token ($e_{zero}$) for empty space.
- Mechanism: Each occupied voxel is serialized as a triplet:
<voxel> [location] [geometry_code]. - Impact: Total sequence length drops from ~4000 tokens to ~500, enabling the MLLM to "see" multiple parts simultaneously without hitting context limits.
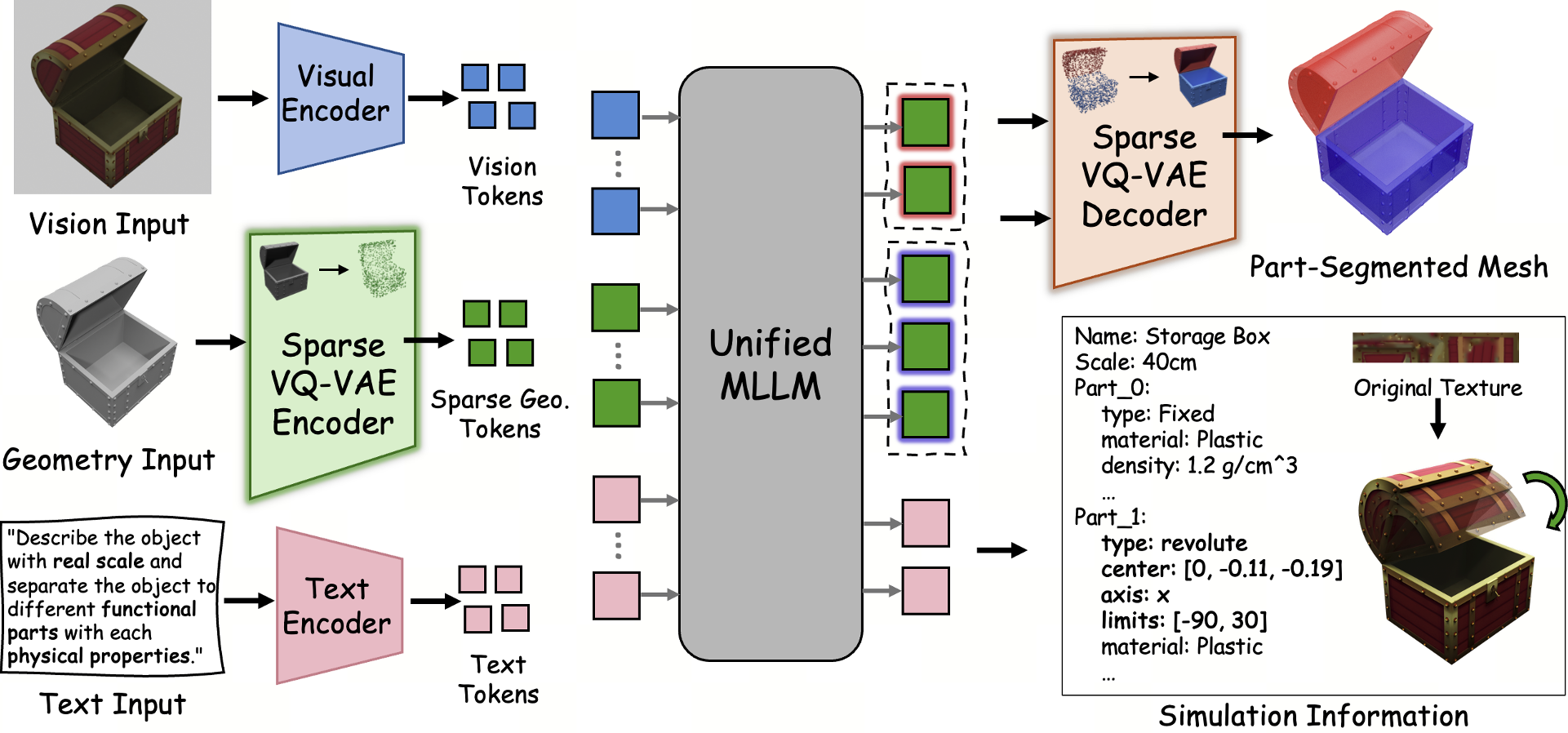
2. Unified Reasoning Backbone (Qwen3-VL)
By injecting these sparse geometry tokens alongside 2D rendered images and text instructions, the model performs Joint Spatial-Semantic Reasoning. It doesn't just segment based on shape; it uses its world knowledge (e.g., "drawers usually slide horizontally") to constrain its geometric predictions.
Experiments & Results: Precision meets Complexity
The authors validated SIMART on SIMART-Bench, a new benchmark featuring challenging, high-variance AI-generated objects.
SOTA Performance
In comparison with Articulate-Anything and PhysX-Anything, SIMART demonstrates a profound leap in Axis Error (reducing it by over 60%) and IoU (Intersection over Union).

Key Results Table Analysis:
- Type Accuracy: Hit 92.8% on known items.
- Inference Efficiency: The Sparse VQ-VAE is the "secret sauce" that allows training on 8x A100 GPUs where dense models would OOM.
Physics-Based Deployment
The output isn't just a colorful mesh; it's a complete URDF specification. The authors demonstrated the generated assets being manipulated by robotic arms in Isaac Sim, showing that the predicted "limits" and "friction" are physically plausible.
Critical Analysis & Conclusion
Takeaways
SIMART proves that 3D grounding is better handled within a unified MLLM than through separate modules. The move to sparse representation is not just an "optimization"—it is a necessity for the next generation of high-resolution 3D foundation models.
Limitations & Future Work
- Data Scarcity: The model is still tethered to the quality of PartNet-Mobility. If the training data contains "wrong" articulations, the model will inherit those biases.
- Complex Hierarchies: While it handles simple joints well, highly recursive kinematic chains (like a complex robotic exo-skeleton) remain an open challenge.
Conclusion: SIMART moves us one step closer to an autonomous "Real-to-Sim" pipeline, where a robot can look at a new object, understand its "usage," and simulate interactions within seconds.
Editor's Note: For researchers in Embodied AI, SIMART’s sparse tokenization strategy is the most significant takeaway, offering a template for how to scale 3D context in LLMs.