SKILLRET is a large-scale benchmark for skill retrieval in LLM agents, featuring over 17,810 public agent skills and 63,000+ samples. The authors propose a taxonomy-driven evaluation and introduce the SkillRet model family, which achieves a SOTA NDCG@10 of 83.5, significantly outperforming general-purpose retrievers.
TL;DR
As LLM agents move from "toy apps" to complex ecosystems, they face a massive scaling bottleneck: how to find the right script or prompt (a "skill") among thousands of candidates. This paper introduces SKILLRET, the largest benchmark for agent skill retrieval to date. The key finding? General-purpose retrievers (even those topping MTEB) are surprisingly bad at this. By fine-tuning specialized models, the authors achieved an NDCG@10 of 83.5, a massive leap over existing standards.
Background: The Invisible Bottleneck
Modern agents don't just "talk"; they execute. They use "skills"—reusable modules like CI/CD scripts, data analysis workflows, or specialized prompts.
- The Scale Problem: You can't fit 17,000 skill descriptions into a Claude or GPT-4 prompt.
- The Retrieval Gap: Standard search engines look for keywords. LLM tasks require "intent matching"—understanding that a user asking about "scaling my cloud cluster" needs a specific Kubernetes skill, even if the words don't match exactly.
The SKILLRET Benchmark: 17k Skills, 63k Samples
The authors didn't just crawl GitHub; they built a structured ecosystem.
- Filtering: They pruned 22,000+ raw entries down to 17,810 high-quality skills.
- Taxonomy: They categorized skills into 6 Major domains (e.g., Software Engineering, AI Agents, Data & ML).
- Complex Queries: Using Claude and Qwen, they generated queries that require multiple skills simultaneously, mimicking complex real-world requests.
 Figure 1: The data generation pipeline involving seed queries, LLM synthesis, and human validation.
Figure 1: The data generation pipeline involving seed queries, LLM synthesis, and human validation.
Why Off-the-Shelf Models Fail
The paper reveals a "Pre-training vs. Task-Specific" paradox. Models like NV-Embed-v1 (7B parameters), which dominate general leaderboards, were outperformed by the much smaller Harrier-OSS (0.6B) in the skill domain.
The authors argue that skill retrieval is a long-document matching problem. A skill's documentation (the Markdown body) contains the "how-to," but a user's query is often buried in "noise" (e.g., "Hi, I'm working on a project and I noticed that... could you help me with X?").
Methodology: Focus through Fine-Tuning
The authors fine-tuned the Qwen3-Embedding family. The "Secret Sauce" wasn't just more data, but a focus on Intent Isolation.
Through a technique called Sentence Erasure, they proved that fine-tuned models learn to ignore the "fluff" in a user's query and zero in on the exact sentence that demands a skill.
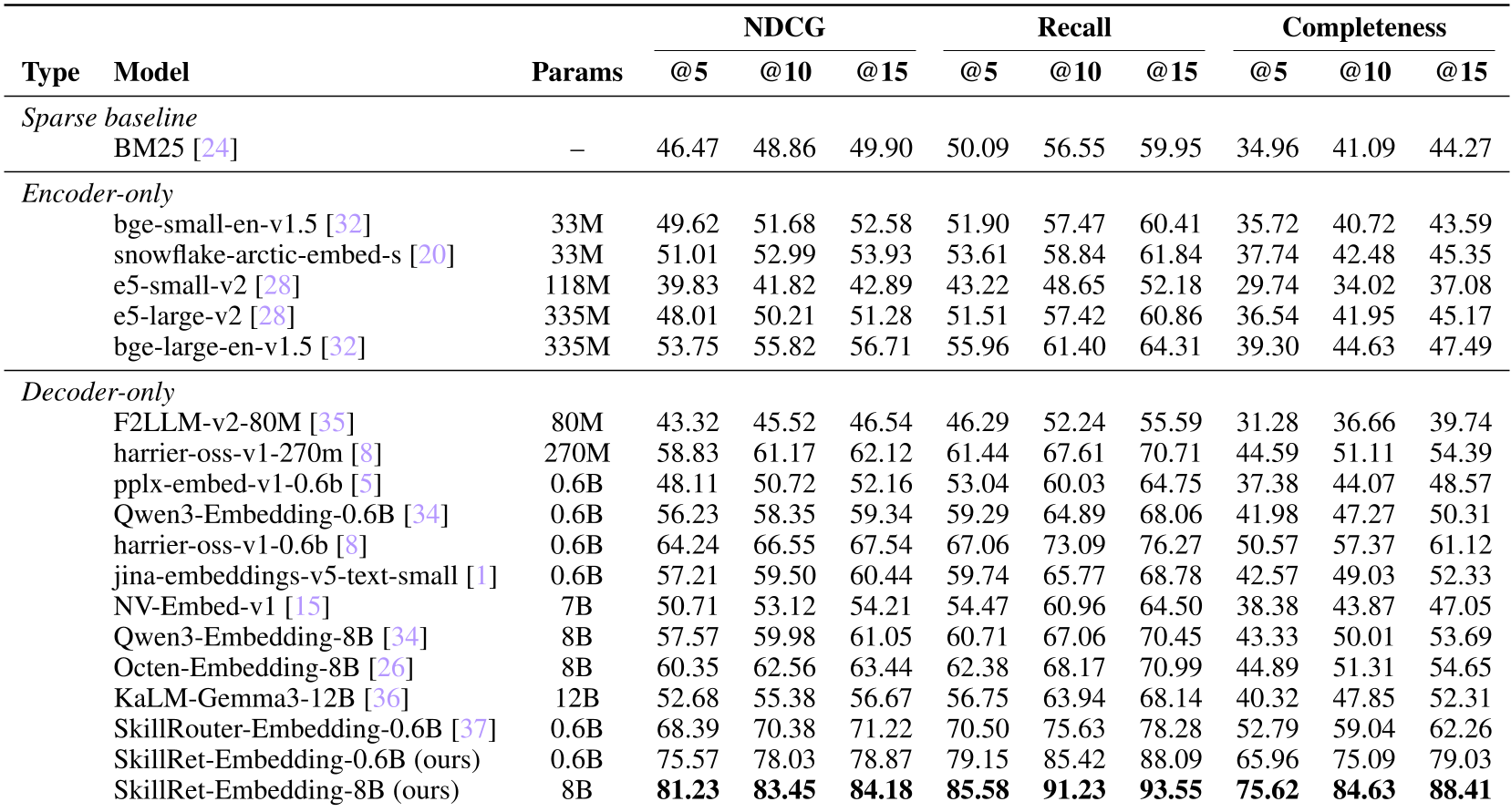 Table 1: Comparison of embedding models. Note the massive jump from off-the-shelf (50-60 NDCG) to SkillRet-trained models (78-83 NDCG).
Table 1: Comparison of embedding models. Note the massive jump from off-the-shelf (50-60 NDCG) to SkillRet-trained models (78-83 NDCG).
Key Insights & Results
- MTEB is Not Enough: There is only a moderate correlation (ρ=0.71) between general retrieval ability and skill retrieval. You cannot trust general leaderboards for agentic systems.
- The Reranking Limit: Rerankers help, but only if the first-stage retriever is already decent. If your base model is "lost," the reranker often makes things worse by introducing domain mismatch.
- Hard Categories: "Information Retrieval" and "AI Agents" remain the hardest skills to retrieve, despite fine-tuning. This suggests that as agents get meta (agents helping agents), the language becomes increasingly abstract and hard to index.
Deep Insight: "Actionable Signaling"
The most profound takeaway is the Sentence Erasure Analysis. When the authors "masked" the most important sentence in a query:
- Base models saw a 23% drop in performance.
- Fine-tuned models saw a 29% drop.
This means the fine-tuned model has a "higher peak"—it relies more heavily on the specific capability signal. It has learned the "language of action."
Conclusion
SKILLRET proves that if we want "agents at scale," we need to treat the retrieval layer as a first-class citizen, not a solved problem. The release of their 0.6B and 8B checkpoints provides a powerful new foundation for anyone building multi-tool or multi-skill agents.
Takeaway for Developers: Stop relying on generic vector search for your agent's tools. Fine-tune your embedding layer on your specific skill library—the performance gains (up to 16.9 points) are too large to ignore.
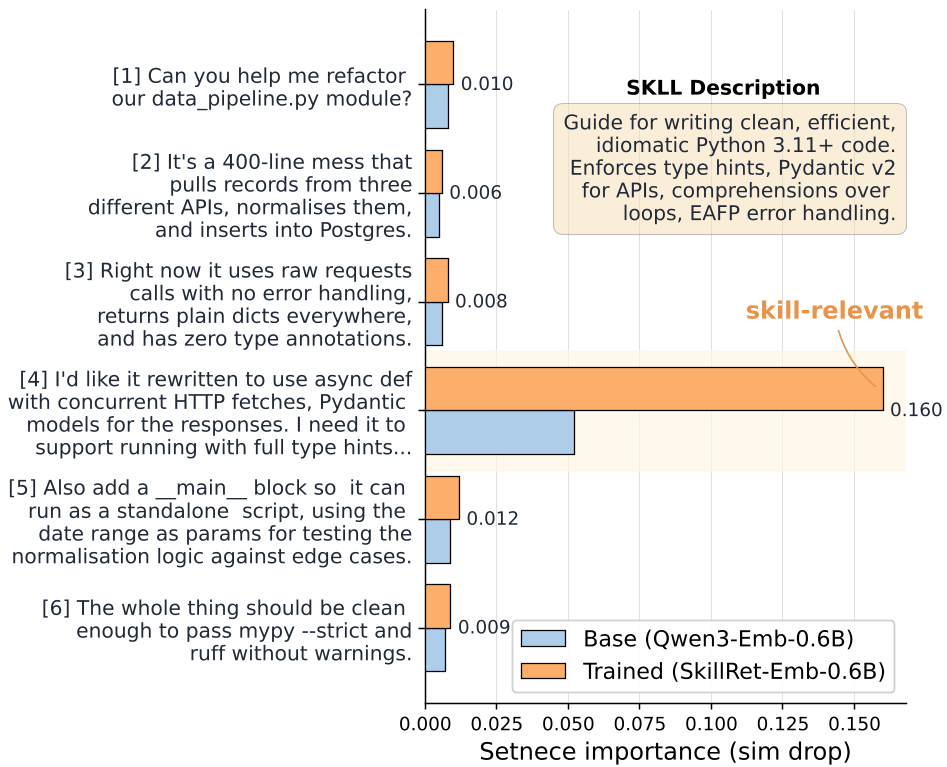 Figure 2: Importance heatmaps showing how fine-tuned models (Trained) concentrate on relevant signals compared to Base models.
Figure 2: Importance heatmaps showing how fine-tuned models (Trained) concentrate on relevant signals compared to Base models.