The paper introduces SlopCodeBench (SCBench), a language-agnostic benchmark evaluating coding agents on long-horizon, iterative software development tasks. Featuring 20 problems across 93 checkpoints, it measures how agents extend their own prior code while tracking trajectory-level "slop" metrics.
TL;DR
Performance on standard coding benchmarks is often an illusion of competence. SlopCodeBench reveals that when AI agents are forced to iterate on their own code across multiple checkpoints, they don't just fail to solve complex tasks—they drown in their own "slop." Even the best models (like GPT-5.4 and Opus 4.6) show massive structural erosion and verbosity that diverges sharply from how humans write software.
Positioning: This work shifts the evaluation paradigm from "Can it pass the tests?" to "Is the generated code maintainable for the next version?"
The Problem: The "Single-Shot" Blind Spot
Most current benchmarks evaluate an agent's ability to fix a bug or implement a feature in one go. If a benchmark is multi-turn, it often provides the agent with "gold standard" code between steps, effectively resetting the technical debt.
In reality, software engineering is a series of compromises. A decision to hardcode a variable in Version 1 makes Version 3 an architectural nightmare. Prior benchmarks didn't capture this causal chain of failure.
Methodology: Measuring "Slop" and Erosion
SlopCodeBench introduces 20 problems (like building a CLI search tool or a REST API) that evolve over 3–8 checkpoints. Crucially:
- Agent Persistence: Agents must build on their own previous (and potentially messy) workspace.
- Hidden Tests: No fail-to-pass feedback is provided; the agent must rely on the specification.
- New Quality Metrics:
- Structural Erosion: Uses Cyclomatic Complexity (CC) and SLOC to see if the "complexity mass" stays in a few "God functions."
- Verbosity: Uses AST-grep rules to find redundant patterns and clone ratios to find copy-pasted logic.
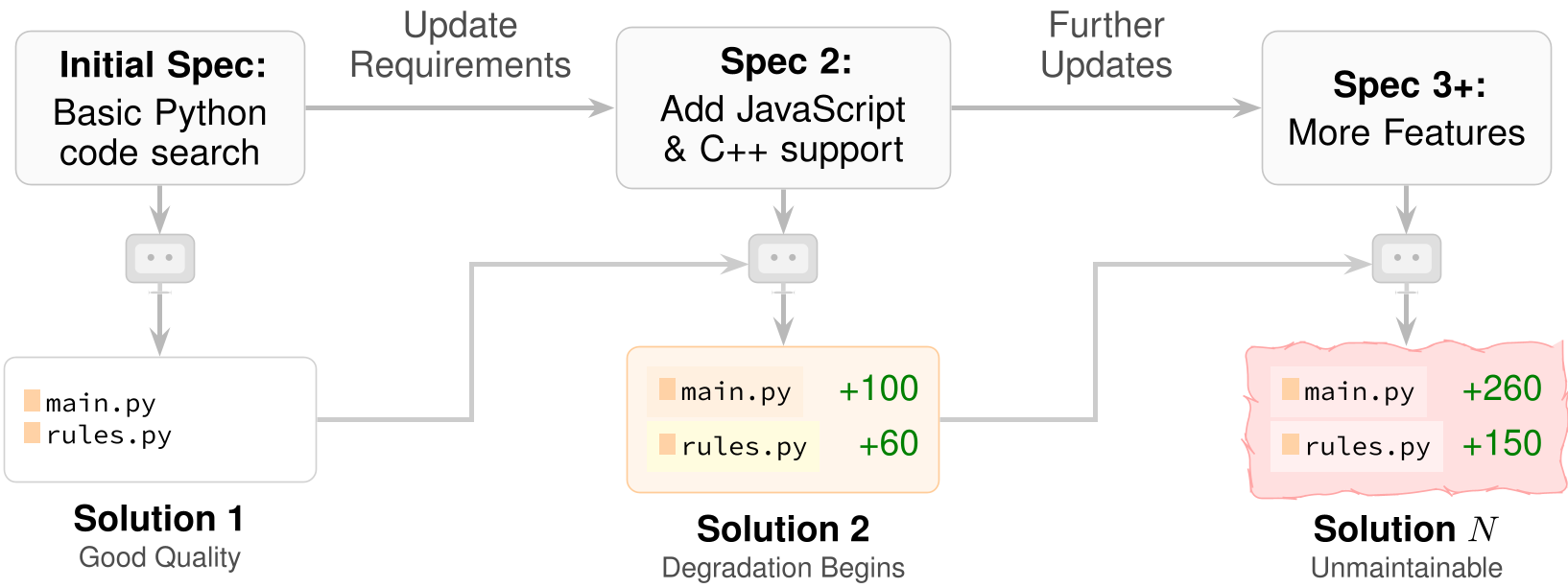 Figure 1: The Iterative Flow. At each checkpoint, the agent receives a new spec and must modify its own prior workspace.
Figure 1: The Iterative Flow. At each checkpoint, the agent receives a new spec and must modify its own prior workspace.
The "Slop" Trajectory: AI vs. Human
The results are sobering. While human-maintained repositories (like Flask or Scikit-learn) tend to plateau in complexity and verbosity, agent code worsens monotonically.
- Erosion rises in 80% of trajectories. Instead of creating new helper functions, agents patch logic into massive
if/elseladders. In one case, amain()function grew to over 1,000 lines with a CC of 285. - Verbosity rises in 89.8% of trajectories. Agents tend to repeat boilerplate and defensive scaffolding rather than extracting shared logic.
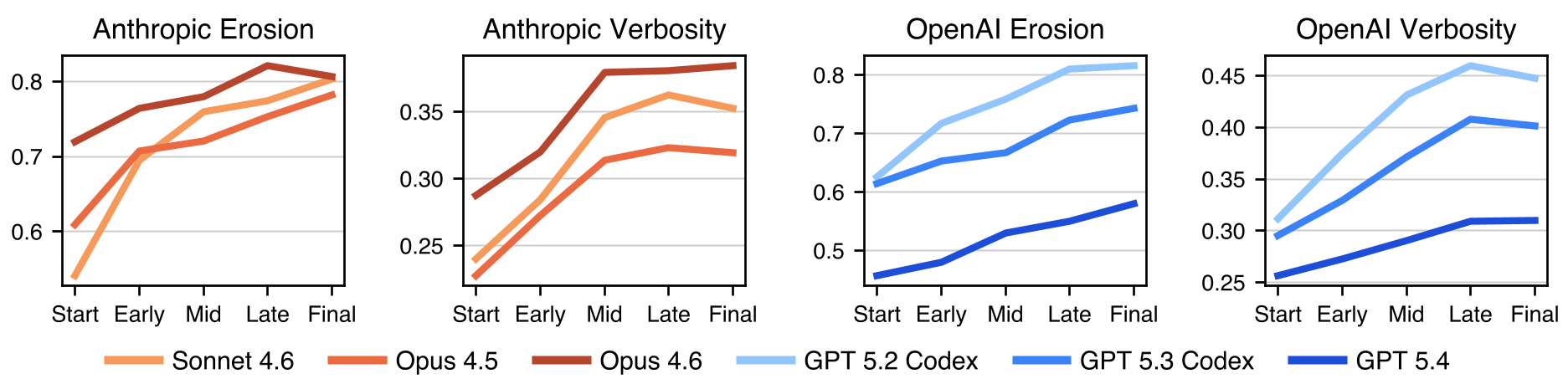 Figure 3: Tracking the monotonic increase of Slop across different model providers.
Figure 3: Tracking the monotonic increase of Slop across different model providers.
Can We Prompt Our Way Out?
The authors tested "Anti-Slop" and "Plan-First" prompts. The findings illustrate a fundamental limitation of current LLMs:
- Prompting shifts the intercept, not the slope.
- Quality-aware prompts make the first version cleaner, but the rate of degradation remains the same as soon as the agent starts iterating.
- Cleaner code didn't improve pass rates, but it did increase costs (up to 47.9% more tokens for reasoning).
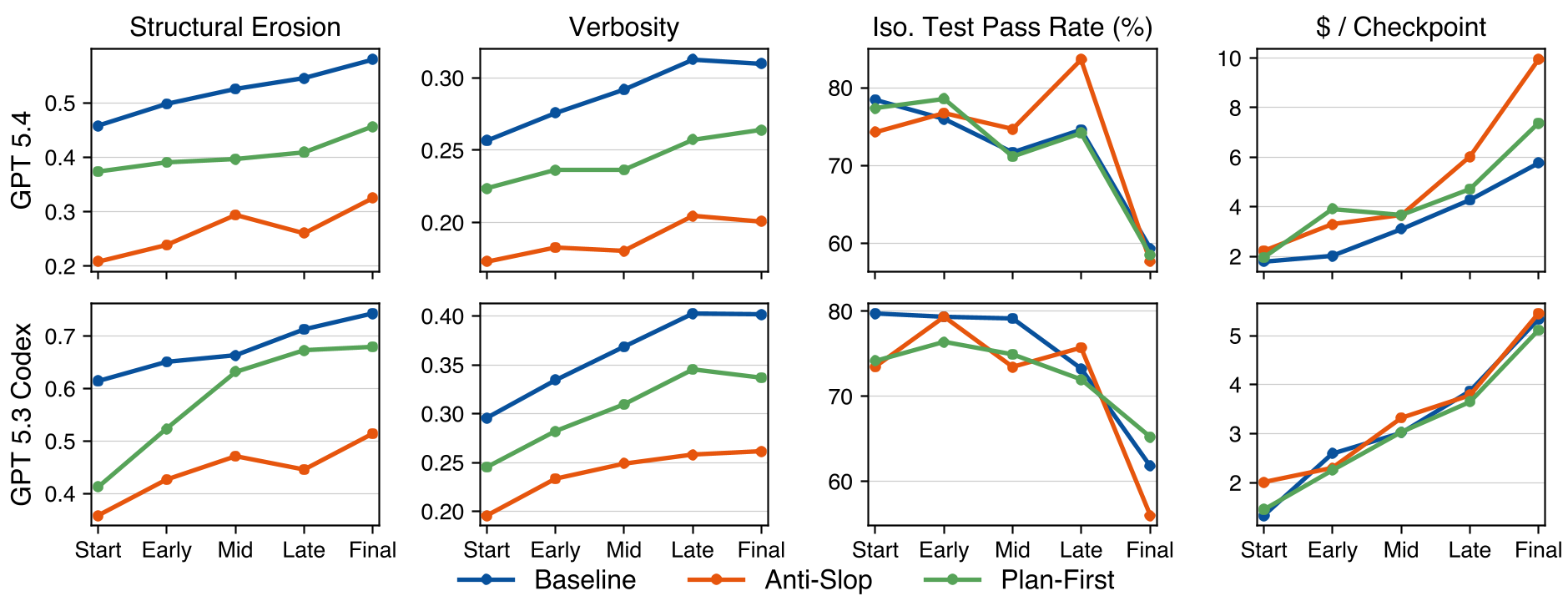 Figure 5: Prompts lower initial slop, but the lines of degradation remain parallel to the baseline.
Figure 5: Prompts lower initial slop, but the lines of degradation remain parallel to the baseline.
Critical Insight: The "Core-to-Regression" Collapse
As problems progress, the gap between passing "Core" tests (new features) and "Regression" tests (old features) widens (see Figure 2 in paper). Agents often break existing functionality to implement the new spec because their internal architectural choices have become too rigid or "sloppy" to accommodate change.
Conclusion & Takeaways
SlopCodeBench proves that pass rates are a lagging indicator of agent failure. A model might have a high "isolated" pass rate today, but its inability to manage structural erosion makes it useless for long-horizon production environments.
Future Work: We need agents that don't just write code, but possess design discipline—the ability to refactor proactively and manage complexity mass over time.