SOD (Step-wise On-policy Distillation) is a post-training framework designed to stabilize Tool-Integrated Reasoning (TIR) in Small Language Models (SLMs). By adaptively reweighting token-level distillation signals based on step-level student-teacher divergence, SOD achieves a 20.86% improvement over competitive baselines on math, science, and code benchmarks, notably enabling a 0.6B model to score 26.13% on AIME 2025.
TL;DR
Training small language models (SLMs) to act as reliable agents is notoriously difficult. Reinforcement Learning (RL) suffers from sparse rewards, while On-policy Distillation (OPD) falls apart when the student model makes a mistake that confuses the teacher. SOD (Step-wise On-policy Distillation) solves this by dynamically lowering the "volume" of the teacher's advice whenever the student wanders into a state it doesn't understand, preventing the model from learning from its own hallucinations.
The Problem: The Discontinuous Drift in Tool Use
In normal text generation, if a model makes a minor mistake, the distribution shift is usually progressive. However, in Tool-Integrated Reasoning (TIR), a single incorrect character in a Python call or an API request triggers an "erroneous observation" from the environment.
This creates a cascading failure. As the paper formalizes in Proposition 1, these errors compound super-linearly. The teacher model, which was never trained on such nonsensical prefixes, provides high-variance, unreliable gradients. When the student is "lost," the teacher's dense supervision becomes noise, leading to Gradient SNR collapse.
 Figure 1: Comparison showing how tool errors cause divergence to explode compared to text-only reasoning.
Figure 1: Comparison showing how tool errors cause divergence to explode compared to text-only reasoning.
Methodology: Adaptive Trust
The core innovation of SOD is the Step-level Divergence Score (). Instead of treating the entire trajectory as one block of advice, SOD breaks it down by tool interactions.
- Divergence Detection: For each step, it calculates the gap between the student’s log-probability and the teacher’s.
- Adaptive Weighting: If the divergence increases (), it means the student has likely made a tool error and the teacher's advice is now suspect. SOD suppresses the distillation weight ().
- The Recovery Pattern: Uniquely, if a student makes an error but eventually self-corrects in a later step, SOD detects the decrease in divergence and increases the weight, allowing the model to learn from its successful recovery.
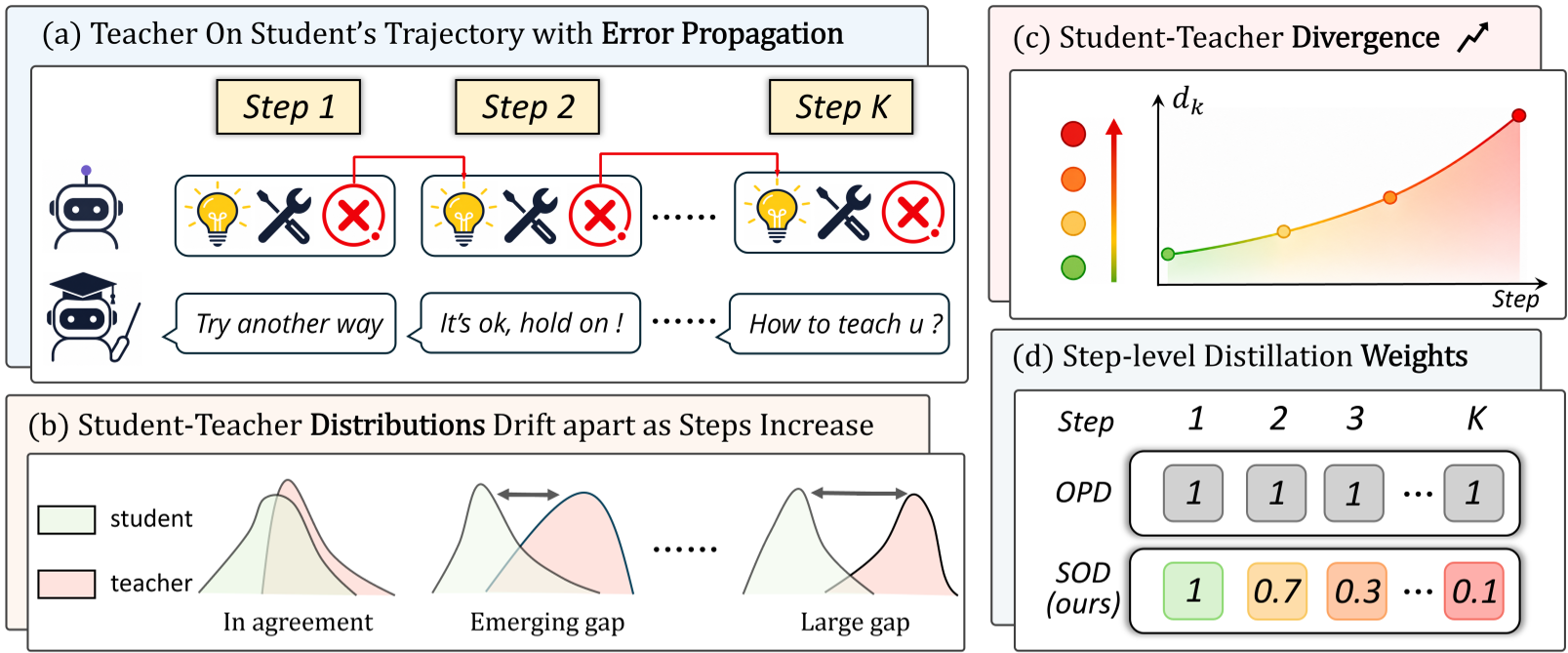 Figure 2: The SOD framework—measuring drift and reweighting distillation.
Figure 2: The SOD framework—measuring drift and reweighting distillation.
Experiments: SLMs punching above their weight
The researchers tested SOD on the Qwen3 series (0.6B to 1.7B). The results are startling:
- AIME 2025: The 0.6B student (less than a billion parameters!) achieved 26.13%, a record for models of this size.
- Ablation Success: Removing the adaptive weighting (Uniform Weighting) caused an average performance drop from 42.98% to 34.70%, proving that "trusting the teacher" only when the student is sane is the key.
- Efficiency: SOD actually trained faster in some cases because the model learned to produce shorter, more efficient reasoning paths rather than getting stuck in loops of failed tool calls.
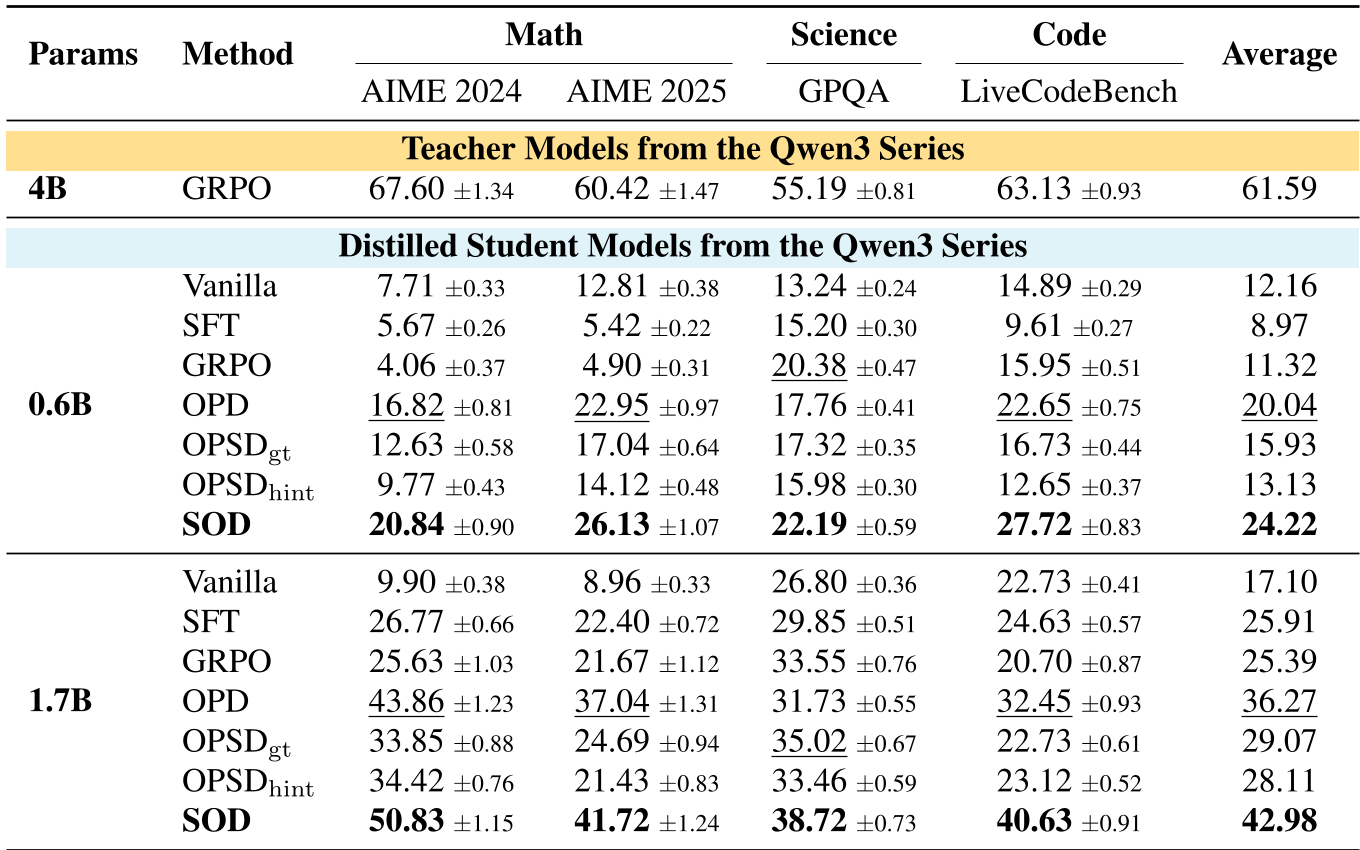 Table 1: SOD consistently outperforms GRPO and standard OPD across math, science, and coding benchmarks.
Table 1: SOD consistently outperforms GRPO and standard OPD across math, science, and coding benchmarks.
Critical Analysis: Why This Matters
For years, the industry trend has been "bigger is better." SOD suggests that for agentic tasks, the quality of the distillation loop is more important than raw parameter count.
By grounding the distillation signal in the reality of tool-induced state drift, SOD allows 1.7B models to capture nearly 70% of the capability of a 4B teacher. The main limitation remains the reliance on a code interpreter for "clean" states, but the principle of Step-wise Divergence is a general-purpose fix for any agentic training system.
Conclusion
SOD demonstrates that Small Language Models can be highly capable agents if we stop forcing them to learn from corrupted states. By modulating teacher supervision with student-teacher divergence, we can build lightweight, on-device agents that reason effectively without the stable-collapsing issues of pure RL.