This paper introduces a theoretical and empirical framework to evaluate whether Sparse Autoencoders (SAEs) capture nonlinearly curved global structures called "concept manifolds." By analyzing Llama 3.1-8B representations, the authors demonstrate that SAEs typically recover these structures through "dilution"—a fragmented tiling of the manifold across many localized features—rather than compact linear directions.
TL;DR
The "Linear Representation Hypothesis"—the idea that AI models store concepts as neat, straight lines—might be an oversimplification. This paper proves that LLMs actually represent concepts as curved, multi-dimensional manifolds. While Sparse Autoencoders (SAEs) can see these structures, they don't capture them as unified objects; instead, they "tile" them into a fragmented mosaic of local detectors, a phenomenon the authors call Dilution.
Background: The Limits of the Straight Line
For years, mechanistic interpretability has relied on the assumption that if you find the right direction in an LLM's activation space, you’ve found a "concept" (e.g., "Paris" or "Sentiment"). However, if you look at how a model represents the "Days of the Week," it doesn't look like seven separate sticks. It looks like a circle. Colors look like a paraboloid.
If our tools (SAEs) assume concepts are linear but the reality is curved, we get interventional brittleness: trying to steer a model by a single feature direction often fails because you're pushing the representation off the curved surface it lives on.
Methodology: The Three Regimes of SAE Capture
The authors propose that SAEs represent these curved manifolds in one of three ways:
- Subspace Capture: A few atoms perfectly span the subspace containing the manifold.
- Shattering: Features become hyper-specialized, with each atom covering a tiny, non-overlapping patch (like "Tuesday at 4 PM" instead of "Tuesday").
- Dilution: Many redundant features overlap to cover the same geometry. This is where current SAEs (TopK, JumpReLU, etc.) actually live.
The Ising Pipeline for Discovery
Because individual features are fragmented, the authors used an Ising Model (borrowed from statistical physics) to find "feature communities." Instead of asking "do these features point in the same direction?", they ask "do these features fire together or inhibit each other predictably?"
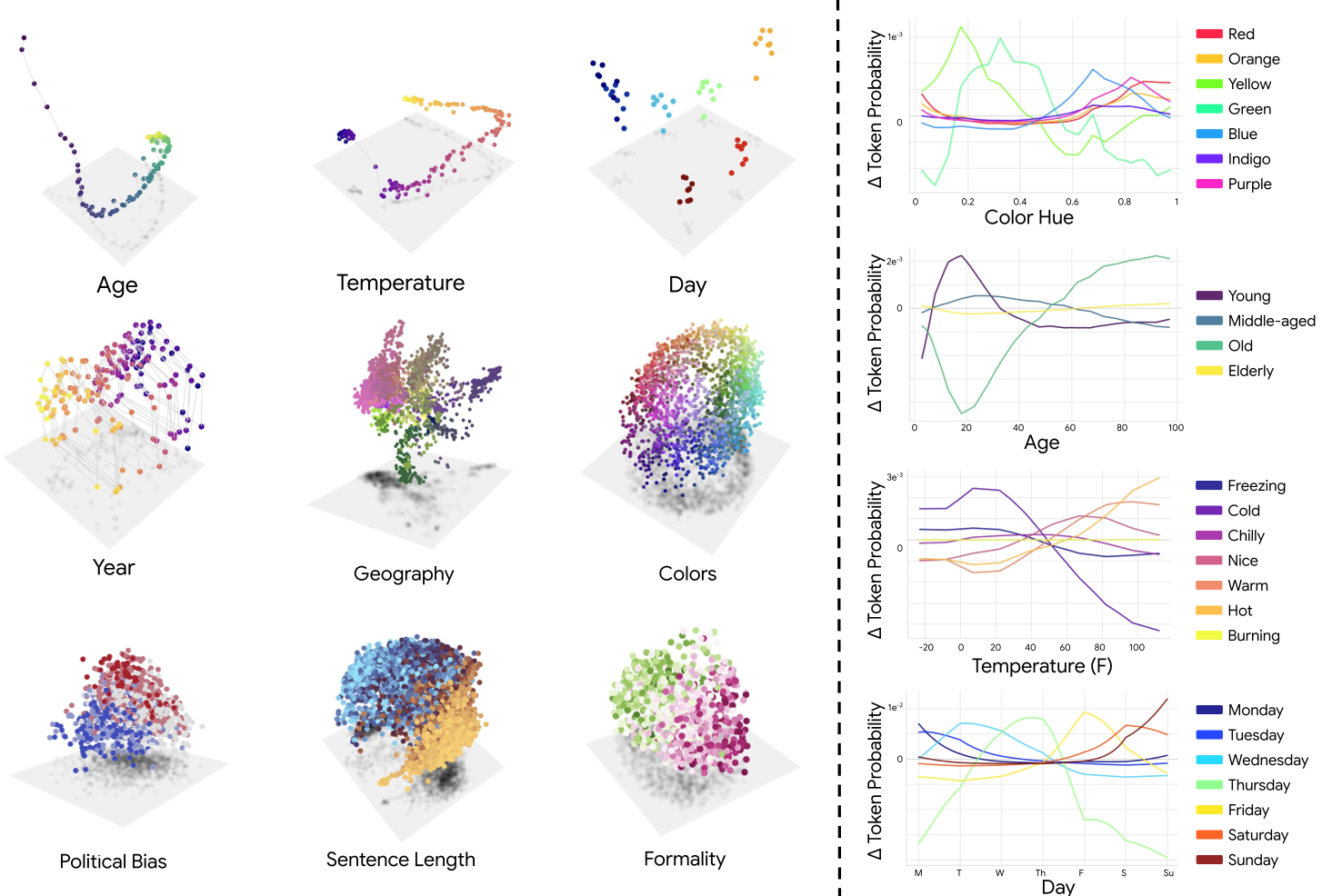 Figure 1: PCA projections of Llama 3.1-8B show that concepts like Color and Temperature are organized as smooth geometric manifolds, while steering interventions show these structures are causally functional.
Figure 1: PCA projections of Llama 3.1-8B show that concepts like Color and Temperature are organized as smooth geometric manifolds, while steering interventions show these structures are causally functional.
Experiments and Results: The Dilution Reality
The authors tested five different SAE architectures on Llama 3.1-8B. They found that to reconstruct a manifold with an ambient dimension of, say, 2, an SAE often used dozens of features.
- Tuning Curves: Features displayed "population coding" similar to biological neurons. A single "Year" feature might fire every 10 years (detecting the 'ones' digit), tiling the temporal manifold.
- Unsupervised Success: The Ising-based discovery tool didn't just find known manifolds; it discovered a new one for "epistemic uncertainty" in scientific text—grouping features that detect measurement error and imprecision.
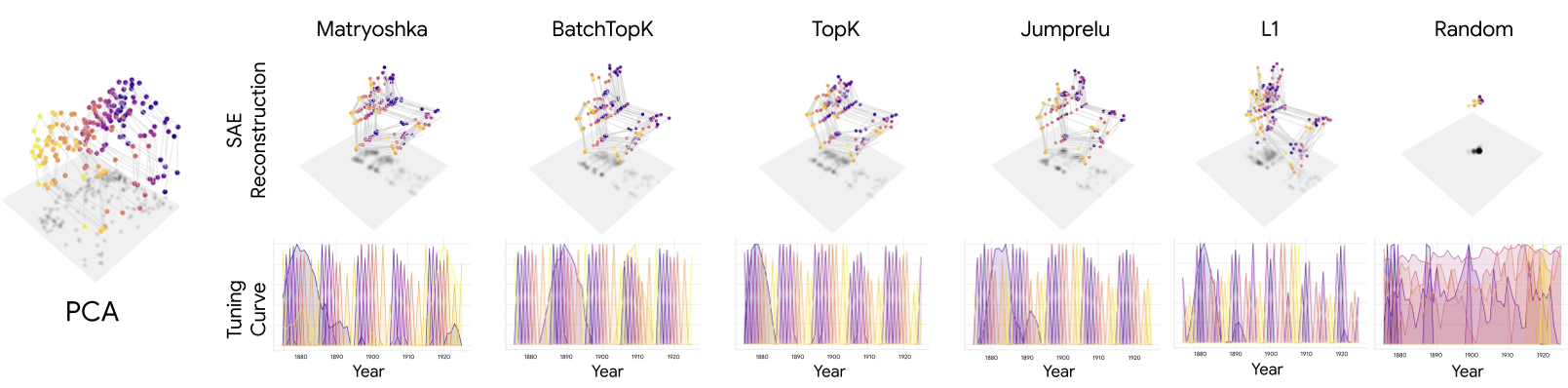 Figure 2: Turning curves in SAEs. Note how features tile the "years" manifold with localized, periodic activation profiles resembling neural population codes.
Figure 2: Turning curves in SAEs. Note how features tile the "years" manifold with localized, periodic activation profiles resembling neural population codes.
Critical Analysis: Why This Matters for the Future
The current state of interpretability suffers from a "mismatch between featurizers and geometry." We are using 1D probes to analyze 3D (or ND) shapes.
Key Takeaways:
- Steering: We should stop steering single features and start steering "feature groups" or "subspaces."
- Stability: The "instability" of SAEs (learning different features across runs) is actually a feature, not a bug—there are many ways to tile the same manifold.
- New Architectures: We need next-generation SAEs that reward the recovery of geometric objects, not just sparse directions.
Conclusion
This work marks a shift from a "dictionary of words" view of LLMs to a "geometry of thought." If we want to truly understand how models reason, we must start thinking in manifolds, not just vectors.
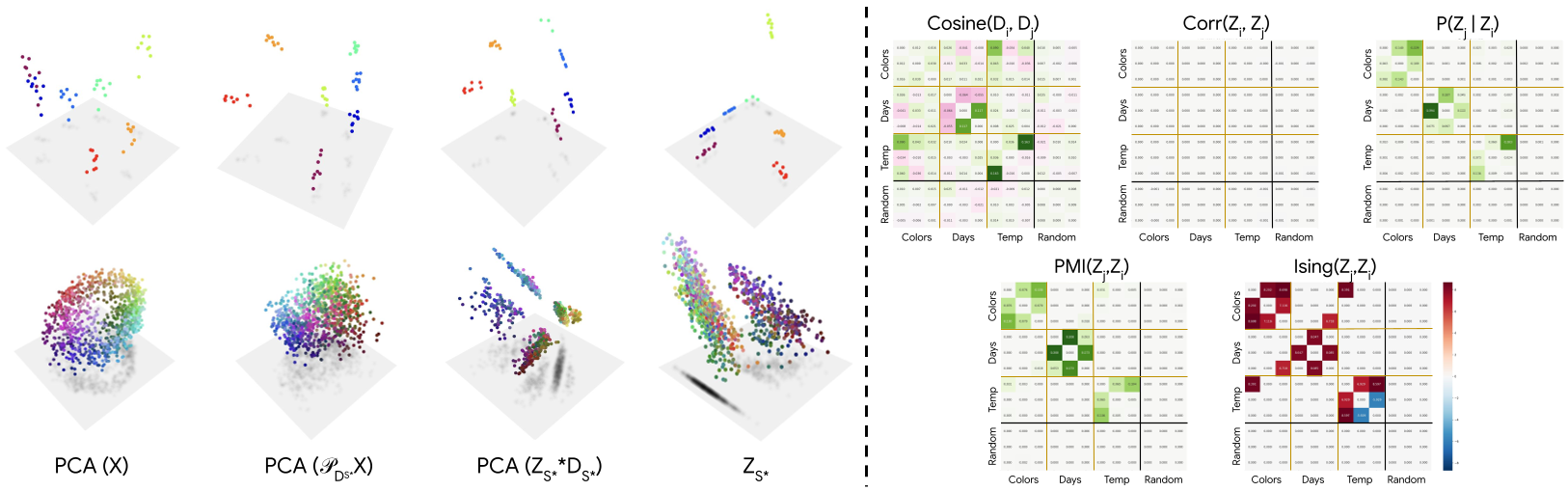 Figure 3: Contrast between decoder similarity (which fails to group related concepts) and the Ising/Conditional Co-activation metrics which reveal clear manifold clusters.
Figure 3: Contrast between decoder similarity (which fails to group related concepts) and the Ising/Conditional Co-activation metrics which reveal clear manifold clusters.