本文对大语言模型在可验证奖励强化学习(RLVR)过程中的 Token 级分布变化进行了深度实证研究。通过对 Qwen2.5 等模型的分析,作者发现 RLVR 带来的性能提升并非源于对模型行为的全局改写,而是通过极少数(通常 < 10%)关键 Token 位置的精确重塑(Sparse and Targeted Refinement)来引导推理轨迹。
TL;DR
阿里 Qwen 团队的最新研究揭示了一个令人惊讶的事实:RLVR(基于可验证奖励的强化学习)对大模型的改造是极度“吝啬”且“精准”的。在推理任务中,RL 模型与 Base 模型在 90% 以上的位置行为几乎一致。然而,正是那不到 10% 的关键 Token 决策(Critical Decisions),像方向盘一样,将原本可能走偏的推理轨迹强行拉回了正确的路径。
1. 动机:RLVR 训练到底在改什么?
长期以来,我们知道 RLVR(如 DeepSeek 提出的 GRPO 或阿里自家的 DAPO)能显著提升模型的数学推理能力。但这种提升是全方位的性格重塑,还是局部的技能增强?
作者敏锐地发现,现有的评估(准确率、奖励值、KL 散度总和)太“糙”了。他们决定动用“手术刀”,在 Token 级探测分布偏移(Distributional Shift)。
2. 核心发现:极度稀疏的“手术刀式”微调
通过计算 Base 模型和 RL 模型在相同上下文下的 JS 散度,研究发现:
- 高度稀疏:在 SimpleRL 模式下,98% 的位置散度接近于 0。这意味着 RL 并没有教模型“重新做人”,大部分时候它只是在复读 Base 模型的预测。
- 位置集中:主要的分布改变集中在序列的开头(决定推理的大方向)和结尾(格式整理和确认答案)。
- 重分配而非创造:RL 很少给 Base 模型认为概率极低(<0.01)的 Token “翻案”。它所做的大多是在 Base 模型已经给出的前几个候选者(Top-k)中微调优先级。
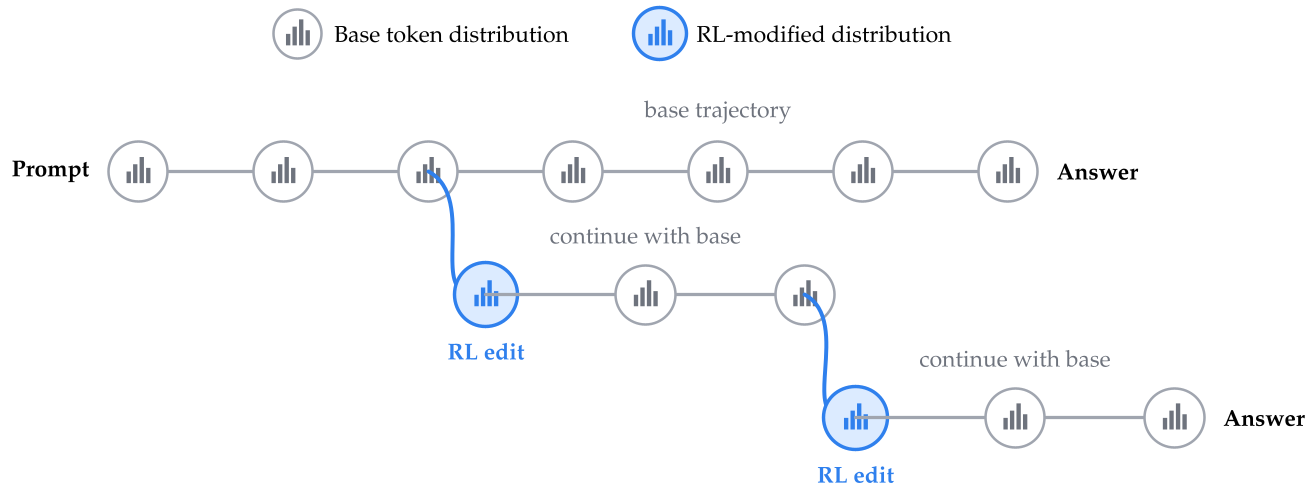 上图展示了 RLVR 如何作为一种稀疏的轨迹转向机制工作。
上图展示了 RLVR 如何作为一种稀疏的轨迹转向机制工作。
3. 交叉采样:1% Token 的生死时速
为了证明这极少数“异见” Token 的功能性,作者设计了一个极具启发性的实验——交叉采样 (Cross-sampling):
- 正向干预 (Forward):让 Base 模型自己去写,但在遇到高散度位置时,强制换成 RL 模型的选词。
- 结果:仅替换 1.5% - 3.8% 的词,Base 模型的准确率就从 5% 暴涨到 RL 级别的 25% 甚至更高。
- 反向干预 (Reverse):让 RL 模型去写,但在关键点强行塞入 Base 模型的原始选词。
- 结果:性能瞬间崩塌,直接跌回 Base 的水平。
 表 1 详细量化了替换少量 Token 后性能剧烈波动的现象。
表 1 详细量化了替换少量 Token 后性能剧烈波动的现象。
4. 深度洞察:RLVR 与 SFT 的本质区别
研究对比了监督微调(SFT)和 RLVR。结果发现 SFT 更像是一柄“重锤”,它会更全局、更大幅度地改变 Token 的分布;而 RLVR 则显示出一种天然的“感性理性结合”——它保留了 Base 模型的普适语言能力,仅在涉及逻辑存亡的关头才发力。
5. 局限性与未来展望
尽管论文揭示了这种稀疏性特征,但为何 RL 会自发选择这种稀疏更新?这种选择是否意味着我们目前的 KL 惩罚项过于死板?
作者尝试利用这一发现,通过 散度加权优势信号 (Divergence-Weighted Advantages) 来指导训练。初步结果显示,给那些分布变化较大的 Token 增加学习权重,能进一步提升 AIME 榜单表现。
核心结论 (Takeaway)
RLVR 对大模型的提升不是“量变”引起“质变”,而是通过在关键节点进行微小的“质变”,导向了全局的正向结果。未来的 RL 训练可能会更加关注于寻找并优化这些“稀疏但致命”的关键位置,而不是在全序列上漫无目的地学习。
本文由资深学术技术主编重构。