本文提出 SpatialReward,一种专为评估和提升文本生成图像(T2I)中精细空间一致性的可验证奖励模型。该方法通过并将 Prompt 分解与专家检测器、多模态大模型(VLM)的思维链(CoT)逻辑推理结合,在 SD3.5 和 FLUX 模型上实现了显著的空间布局优化。
TL;DR
尽管当前的文本生成图像(T2I)模型(如 FLUX, SD3.5)在画质上已达巅峰,但在处理“A 在 B 左边、且 C 的表面刻有特定文字”这种精细空间布局时仍频繁翻车。阿里巴巴、浙大与复旦团队联合推出的 SpatialReward 提出了一种创新的“解耦再推理”方案:通过专家模型检测事实 + VLM 逻辑推理,构建了一个物理意义上可验证的奖励模型,通过 RL 训练让模型真正理解什么是“空间一致性”。
痛点深挖:为何模型总是“画得好,摆得烂”?
在 T2I 领域,RLHF 或强化学习(RL)已成为刷榜标配。然而,现有的奖励模型(Reward Model)存在两大短板:
- Prompt-side 僵硬:传统结构化方法只能理解“一个苹果”这种简单句,遇到复杂的自然语言描述就失效。
- Vision-side 幻觉:基于 CLIP 的全局评分虽然觉得图像“看起来很美”,但无法察觉物体位置的细微错位或遮挡关系的逻辑性,导致所谓的“视觉欺骗”。
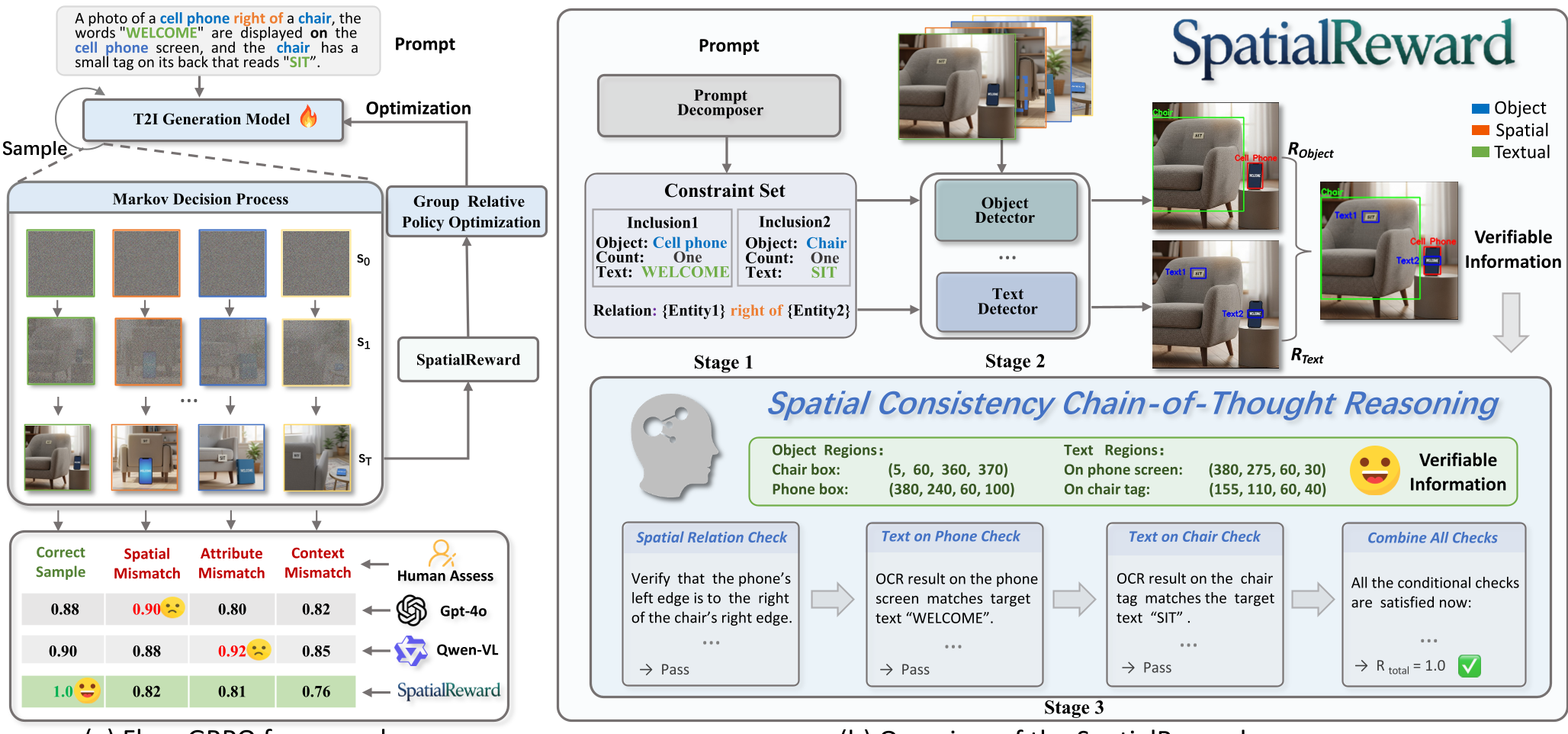
核心方案:SpatialReward 的“三步走”战略
作者认为,要解决空间幻觉,必须给 AI 一个能“算清楚”的裁判。
1. 结构化解构 (Prompt Decomposition)
利用微调过的 Qwen2.5-VL 将 free-form 的自然语言拆解。例如把“洗手池左边第二个刻有 Clean”拆解为:(实体: 槽, 数量: 4, 关系: 在...之间, 文字: Clean)。
2. 事实性验证 (Verifiable Grounding)
不再让 VLM 盲猜,而是引入专业的“专家模型”:
- Open-set Detectors (YOLO-World/G-DINO) 定位物体。
- OCR 模型 强制核对文字内容与位置。
- 深度估计模型 判断物体的 3D 前后层次。 这种引入物理信号的方式,为奖励提供了Inductive Bias。
3. 思维链推理 (CoT Reasoning)
将第一步的约束和第二步的检测坐标全部喂给 Qwen2.5-VL,让它像做几何题一样给出理由:“因为物体 A 的中心点坐标 (x1,y1) 小于物体 B 的 (x2,y2),所以‘左边’这一关系成立。”
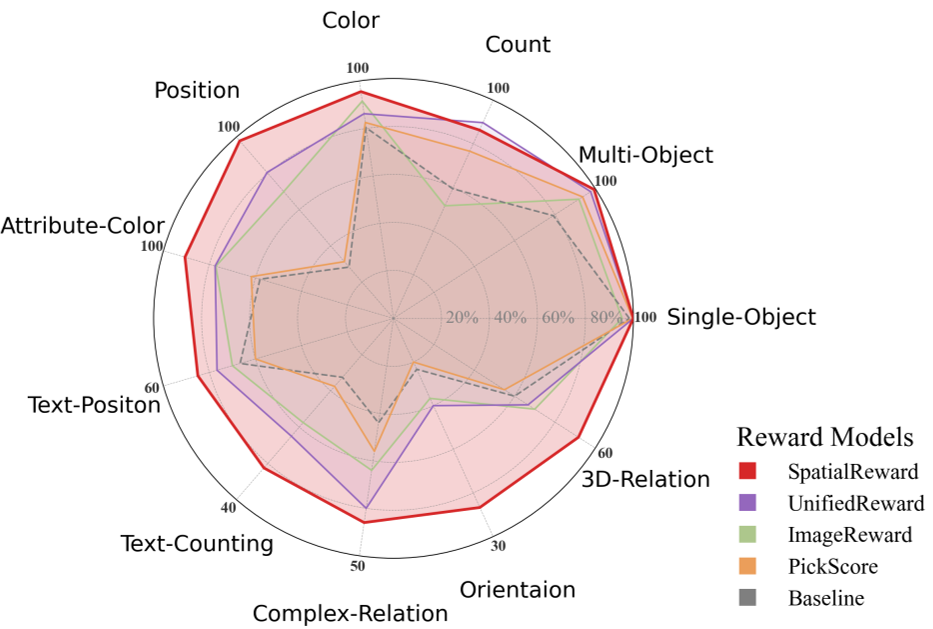
实验战绩:全方位的空间觉醒
在作者提出的更严苛的基准测试 SpatRelBench(包含 3D 关系、物体朝向、文字精确位置等)中,SpatialReward 表现惊人:
- 精度爆炸:在 SD3.5 上,位置准确度(Pos.)从原生模型的 0.28 飙升至 0.98。
- 复杂文本渲染:在“物体特定位置渲染特定文字”这一地狱级任务中,性能提升了近 3 倍。
- 人类对齐:其评分与人类真实感受的相关性(Spearman ρ)达到了 0.63,远超 CLIPScore (0.42)。

深度洞察
SpatialReward 的成功本质上是视觉推理的符号化(Symbolic)回归。纯内生(End-to-end)的模型往往在统计规律中迷失,而通过专家检测器引入的外生知识,充当了 RL 过程中的“物理常识锚点”。
局限性与未来展望: 尽管在静态图像上表现卓越,但对于极其复杂的遮挡(如透明材质后的物体定位)仍依赖于感知模型的极限。未来的产线可能会将此框架扩展到视频流生成中,解决视频中物体前后帧空间不一致(Spatial-Temporal Inconsistency)的顽疾。
结论
SpatialReward 不仅仅是一个更好的评分工具,它提供了一种**“可解释生成”**的新思路:通过强化学习,强制让黑盒扩散模型去对合物理世界的几何规则。对于追求精准控图的设计师和开发者来说,这无疑是迈向工业级应用的重要一步。