The paper introduces P-STMAE (Physics Spatiotemporal Masked Autoencoder), a novel framework for forecasting high-dimensional dynamical systems with irregular time steps. It combines Convolutional Autoencoders (CAE) for spatial compression with Masked Transformers to reconstruct and predict entire physical sequences in a single non-autoregressive pass, achieving SOTA performance on fluids and climate data.
TL;DR
Predicting the future of physical systems (like ocean currents or fluid flow) is notoriously difficult when your data is "holy"—full of gaps due to sensor failure or irregular sampling. P-STMAE solves this by ditching the traditional step-by-step recurrent prediction (RNN/LSTM). Instead, it uses a Masked Transformer in a compressed latent space to "reconstruct" the future. It treats forecasting as a completion task, resulting in higher accuracy, zero error accumulation, and massive robustness to missing data.
Context: The "Regularity" Trap
In the world of Deep Learning for physics, most SOTA models like ConvLSTM assume time is a metronome—ticking at perfectly equal intervals. But real-world science is messy:
- Sensors fail intermittently.
- Satellites only pass over specific regions at irregular orbits.
- Adaptive PDE solvers change their time-step size based on local complexity.
When we force this "broken" data into a regular grid via interpolation, we introduce "hallucinated" artifacts. P-STMAE argues that we should stop trying to fix the data and start fixing the architecture.
Methodology: Spatiotemporal Compression + Masked Inference
The P-STMAE architecture operates in two distinct phases:
1. Spatial Dimension Reduction (The CAE)
High-dimensional physical fields (e.g., 128x128 grids) are too heavy for Transformers. P-STMAE uses a Convolutional Autoencoder (CAE) to squash these grids into a 128-dimensional latent vector. This ensures the Transformer only manages the "essence" of the dynamics.
2. Temporal Reconstruction (The Masked Transformer)
Instead of predicting $t+1$ from $t$, the model takes a sequence where some steps are Observed and others (including the future) are Placeholders.
- The Encoder only looks at the observed steps.
- The Decoder takes the refined observed features + the empty placeholders (and their time-stamps) to reconstruct the full sequence.
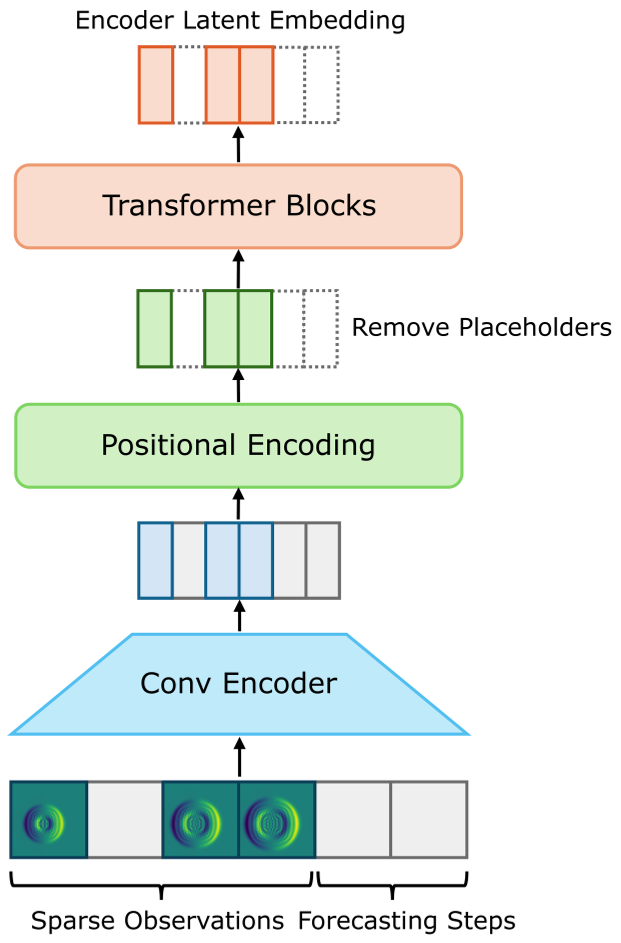 Figure 1: Comparison between traditional Sequential (RNN) forecasting and P-STMAE’s Element-wise Reconstruction.
Figure 1: Comparison between traditional Sequential (RNN) forecasting and P-STMAE’s Element-wise Reconstruction.
Why it Works: The Physics Intuition
By using Self-Attention, a point at $t=10$ can look back at $t=1$ and $t=5$ simultaneously. In a fluid system, where a vortex might take time to travel across a domain, this global "contextual" view is much more physically grounded than the "short-term memory" of an LSTM.
The inclusion of Sine-Cosine Positional Embeddings allows the model to understand exactly how much time has passed between irregular steps, allowing it to learn the underlying "flow map" of the system rather than just a sequence of frames.
Experimental Showdown
The authors tested the model against ConvRAE and ConvLSTM on three challenging scenarios: Shallow Water equations, Diffusion-Reaction patterns, and NOAA Sea Surface Temperature (SST).
Performance Highlights:
- Stability: As the "missing ratio" increased to 6 out of 10 steps, P-STMAE’s error remained flat, while ConvLSTM’s error exploded.
- Precision: In the Shallow Water test, P-STMAE achieved a PSNR of 43.90 dB, indicating extremely high-fidelity reconstruction of fluid heights and velocities.
 Figure 2: Visualizing the error. P-STMAE (bottom left) maintains nearly zero error compared to the widespread artifacts in ConvLSTM.
Figure 2: Visualizing the error. P-STMAE (bottom left) maintains nearly zero error compared to the widespread artifacts in ConvLSTM.
Critical Insight: Real-World Generalization
The most impressive result is on the NOAA SST dataset. Real ocean data is inherently noisy and influenced by global climate patterns (like El Niño). P-STMAE's ability to capture these long-range dependencies while ignoring sensor noise demonstrates that latent-space masking is a powerful regularizer for scientific data.
Conclusion & Future Outlook
P-STMAE proves that Transformers aren't just for LLMs—they are fundamentally suited for the "irregularity" of the physical world.
Limitations: The quadratic complexity of attention still limits the length of the sequences. However, by moving towards Linear Attention or State-Space Models (SSMs) like Mamba in future iterations, this framework could potentially model decadal climate shifts at a minute-by-minute resolution.
The Takeaway: If your data is sparse and your system is nonlinear, stop interpolating. Start masking.