本文提出了 SpecKV,一种针对投机采样(Speculative Decoding)的轻量级自适应控制器。通过实时监控草稿模型(Draft Model)的信号,动态调整每步的投机长度 γ,在 Llama 3.2 系列模型上实现了比固定 γ=4 基线高出 56.0% 的单步预期 Token 产出。
TL;DR
投机采样(Speculative Decoding)已成为大模型推理加速的标配,但业界一直忽略了一个关键变量:投机长度 的固定化。本文提出的 SpecKV 揭示了模型压缩(如 4-bit 量化)与投机长度之间存在深层耦合。通过一个仅有 16 个神经元的超轻量 MLP 实时调整 ,SpecKV 在不损失精度的前提下,将单步预期生成的 Token 数提升了 56.0%,决策开销几乎可以忽略不计。
痛点深挖:消失的加速比
在典型的投机采样中,小模型(Draft Model)先盲猜 个 Token,大模型(Target Model)再一并验证。目前的 SOTA 框架(如 vLLM)通常将其固定为 4。
然而,作者通过详尽的 Profile 发现了两个被长期忽视的事实:
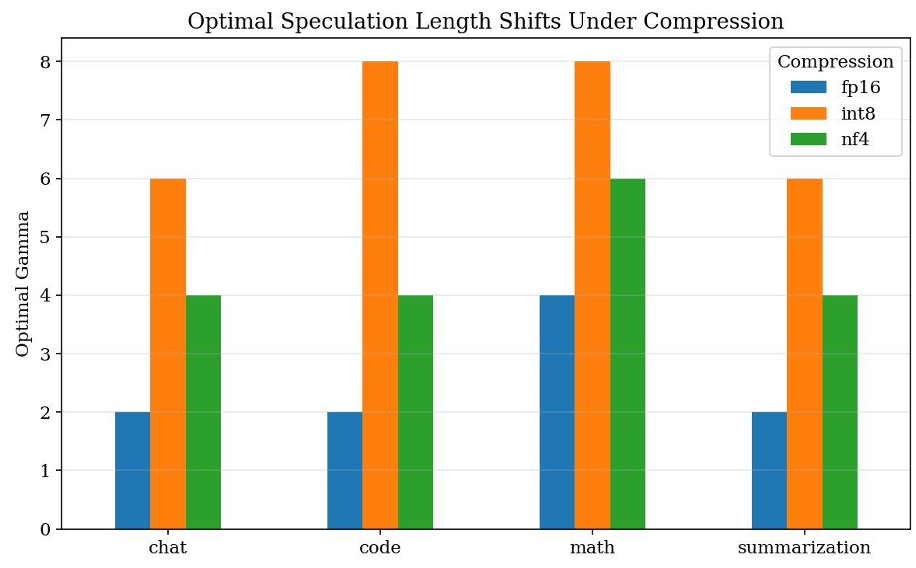
- 任务异质性:数学推理任务接受率高,适合大 ;而开放对话内容随机性强,小 效率更高。
- 压缩耦合性:当你对大模型进行 INT8 或 NF4 量化时,每步验证的计算密度发生了变化。例如,INT8 反量化带来的额外开销,使得系统更倾向于增加 来“均摊”单步启动成本。
核心直觉:草稿模型的“自我察觉”
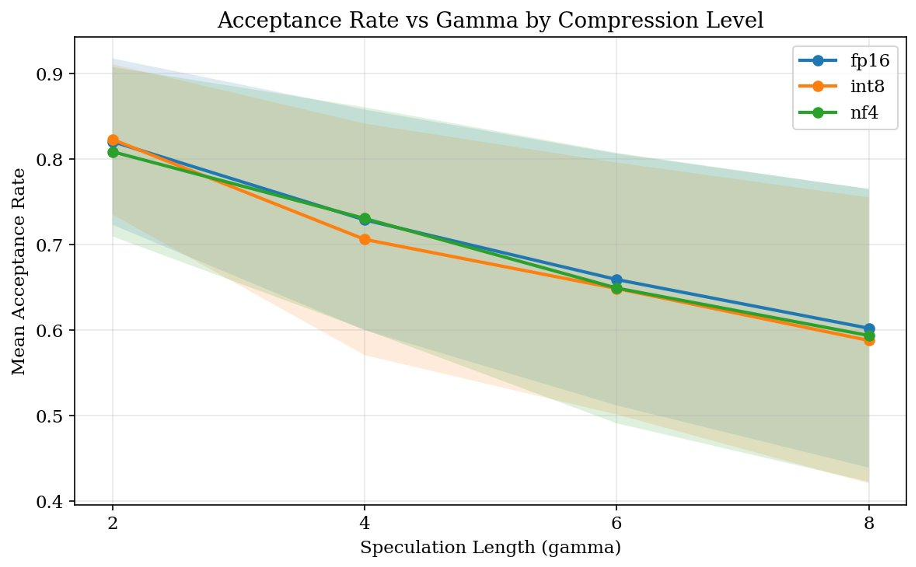
SpecKV 的核心假设是:草稿模型在生成备选 Token 时,其输出层分布的统计特性(熵和置信度)已经预示了这些 Token 被大模型接受的可能性。
作者提取了四个关键信号:
- 平均/最大草稿熵 (Entropy):反映预测的不确定性。
- 平均/最小置信度 (Confidence):反映草稿模型的“把握”程度。
实验证明,这些信号与实际接受率的相关性高达 0.56,且最重要的是,这种相关性在不同的压缩模式(FP16/INT8/NF4)下表现极其稳定。这意味着我们可以训练一个通用的、跨压缩水平的轻量级预测器。
方法论:SpecKV 的自适应架构
SpecKV 将 的选择建模为一个上下文决策问题。
- 信号提取:在草稿生成阶段,实时计算上述熵与置信度特征。
- 接受率预测:利用 MLP 模型预测不同 () 下的预期接受率 。
- 价值最大化:选择能使 最大化的 。
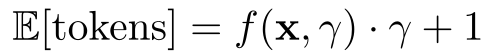
为了保证不拖累推理速度,作者对多种架构进行了 Pareto 边界分析。最终选定的 MLP-16 模型决策耗时仅为 0.34 ms,仅占一次推理步骤总耗时的不到 0.5%,实现了性能与开销的完美平衡。
实验结果:量化环境下的逆袭
在 Llama 3.2 1B/3B 组合及单张 RTX 3090 上的测试显示:
- 性能翻倍:相比于固定的 ,SpecKV 在所有任务组合下实现了 54.8% 到 56.9% 的单步产出提升。
- 压缩感知能力:在 INT8 量化下,系统自动倾向于选择更大的 (如 8),有效对冲了量化带来的算子开销。
深度洞察与总结
SpecKV 的价值在于它证明了推理系统的参数不是孤立的。传统上,AI 架构师负责量化,系统工程师负责投机采样,而 SpecKV 告诉我们:
- 模型越“瘦”(量化更狠),投机就得越“激进”( 调大)。
- 草稿模型的中间状态(熵、置信度)是极其廉价且高质量的控制信号。
局限性:目前研究主要集中在 1B/3B 这种较小的模型配对上,在 70B 及以上规模模型中,这种相关性是否会因为大模型更强的纠错能力而发生漂移,仍需进一步验证。此外,结合 KV Cache 压缩的动态调整将是下一个值得探索的领域。
总结:SpecKV 为工业级 LLM 推理框架(如 vLLM, TensorRT-LLM)提供了一个低成本、高回报的插件式方案。