The paper introduces SSP-SAM, a high-precision framework for Referring Expression Segmentation (RES) that bridges the Segment Anything Model (SAM) with CLIP. By incorporating a Semantic-Spatial Prompt encoder, it achieves SOTA results on RES and Generalized RES (GRES) benchmarks, notably outperforming existing methods at strict overlap thresholds (Pr@0.9).
TL;DR
SSP-SAM is a lightweight, one-stage framework that transforms the Segment Anything Model (SAM) into a powerful Referring Expression Segmentation (RES) engine. By introducing a Semantic-Spatial Prompt (SSP) encoder, the model bridges the gap between CLIP's linguistic intelligence and SAM's mask-generating prowess. It delivers SOTA results on RefCOCO and GRES (Generalized RES) benchmarks, offering 2x the speed of DIT and 50x the speed of MLLM-based solutions like LISA.
Motivation: Why SAM Fails at "Language"
Despite SAM's revolutionary zero-shot segmentation ability, it is "language-blind." When a user says "the animal on the left," SAM might segment every animal in the image because it treats the scene as a collection of parts rather than a context-aware environment.
Existing solutions typically use Pre-SAM (detecting a box first) or Post-SAM (ranking mask proposals) strategies. These are often slow and lack fine-grained alignment. The authors of SSP-SAM argue that the key to unlocking SAM's potential lies in end-to-end prompt learning that integrates both semantic meaning (what it is) and spatial context (where it is).
Methodology: The Architecture of SSP
The core innovation is the Semantic-Spatial Prompt (SSP) Encoder. Instead of passing raw text, it refines "prompts" through two specialized adapters:
- Visual Attention Adapter: Uses CLIP image features to generate sentence-level and word-level attention maps. It applies a Gaussian-like mapping to sharpen the focus on salient objects mentioned in the text.
- Linguistic Attention Adapter: Analyzes the query to find discriminative words. For example, in "the larger zebra," it assigns higher weights to "larger" to help the visual branch distinguish between similar instances.
- Prompt Generator: A transformer-based module that takes the fused semantic-spatial features and converts them into 128 learnable tokens compatible with SAM’s mask decoder.
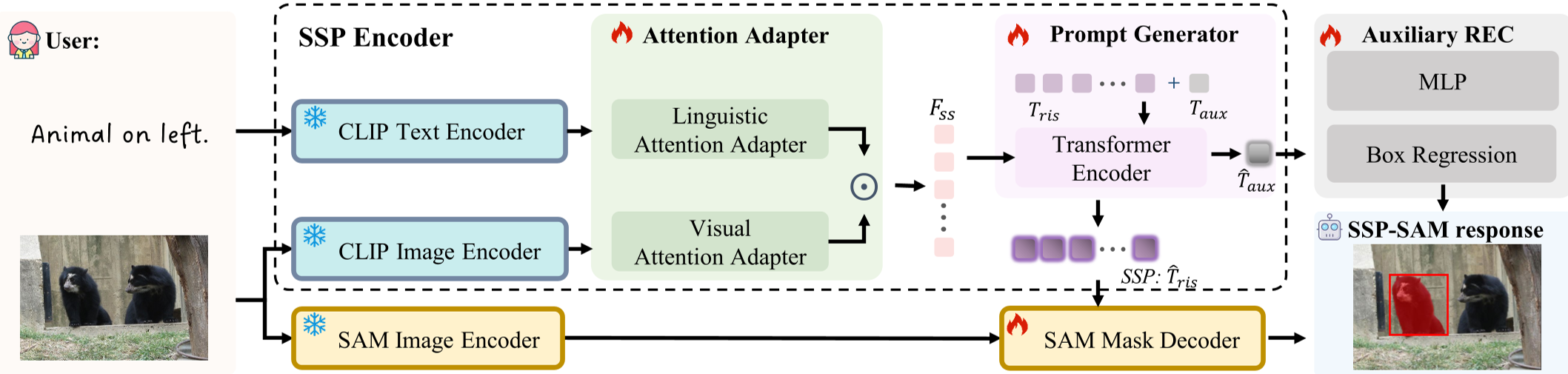 Fig 1: The architecture showing the flow from CLIP features through Attention Adapters to SAM.
Fig 1: The architecture showing the flow from CLIP features through Attention Adapters to SAM.
The "How-it-Works" Intuition
The refined language features undergo an element-wise product with visual features, acting as a soft semantic mask. This ensures that the spatial information (extracted from the image) and the semantic requirements (extracted from the text) are locked together before they ever reach SAM.
Experimental Breakthroughs
SSP-SAM doesn't just "hit" the target; it hits the target with extreme precision.
- High-Overlap Dominance: On the RefCOCO val split, SSP-SAM-336 achieves a Pr@0.9 (Precision at 90% IoU) of 47.77%, nearly 9 points higher than previous SOTA models like CGFormer. This proves it produces masks with significantly sharper boundaries.
- Generalized RES (GRES): In scenarios with multiple targets or "no target" (expressions that refer to nothing in the image), SSP-SAM naturally generalizes, achieving a high N-acc (No-Target Accuracy) without specialized redesign.
 Table 1: Competitive results across RefCOCO splits against both SAM-based and Non-SAM models.
Table 1: Competitive results across RefCOCO splits against both SAM-based and Non-SAM models.
Qualitative Evidence
The visual results are striking. In many cases, SSP-SAM's predictions are more accurate than the ground truth annotations, capturing fine details like a coffee cup handle or an elephant's tail that were roughly labeled in the original dataset.
 Fig 2: Visualizing successful segmentation in complex, multi-target GRES scenarios.
Fig 2: Visualizing successful segmentation in complex, multi-target GRES scenarios.
Conclusion & Key Takeaways
SSP-SAM proves that we don't always need massive 7B-parameter MLLMs for complex vision-language tasks. By smartly adapting existing "Foundation Models" (CLIP + SAM) via lightweight bottleneck adapters, we can achieve:
- Efficiency: Inference in ~26ms on a single GPU.
- Precision: Superior mask quality at strict thresholds.
- Scalability: Easy adaptation to open-vocabulary and generalized RES settings.
This work sets a new benchmark for how we construct "one-stage" multimodal models, emphasizing the importance of spatial-semantic alignment over raw model size.