本文提出了 SSP-SAM,这是一个将语义-空间提示(SSP)编码器集成到 Segment Anything Model (SAM) 中的单阶段 Referring Expression Segmentation (RES) 框架。通过结合 CLIP 的视觉-语言对齐能力与 SAM 的强大分割性能,SSP-SAM 在 RES 和 Generalized RES (GRES) 任务中均取得了 SOTA 战绩。
TL;DR
尽管 Segment Anything Model (SAM) 在分割领域封神,但它面对“左边那个拿着咖啡杯的男人”这类复杂的自然语言指令时,往往表现得像个“听不懂人话”的顶级画师。本文提出的 SSP-SAM 方案,通过一个轻量级的 Semantic-Spatial Prompt (SSP) 编码器,成功架起了 CLIP 与 SAM 之间的桥梁。它不仅在经典 RES 任务上刷新了 SOTA,更在 Generalized RES(多目标/无目标)场景下展现了极强的鲁棒性,且推理速度惊人。
1. 痛点:SAM 的“失语症”
SAM 虽然拥有强大的掩码生成能力,但其设计的初衷是通过点、框或粗略掩码进行交互。当任务变为 Referring Expression Segmentation (RES) 时,SAM 对自由文本的理解能力捉襟见肘。
- Pre-SAM 模式:先用检测器找框,再喂给 SAM。流程繁琐,容易在第一步出错。
- Post-SAM 模式:先生成一堆候选掩码,再用 CLIP 排序。计算开销大,且掩码生成阶段缺乏语言引导。
- 问题所在:如何以一种更廉价、更直接的方式,将文本中的“语义(What)”和“空间(Where)”信息转化为 SAM 能懂的语言?
2. 核心机制:语义-空间提示编码器 (SSP)
SSP-SAM 的核心在于其精心设计的双路径适配器(Attention Adapter),它将来自 CLIP 的冷冰冰的特征向量,转化为具有空间定位感的“软提示”。
2.1 视觉与语言的深度交织
- 视觉注意力适配器 (Visual Attention Adapter):不仅做句子级的全局粗滤,更引入了单词级的精细校准。通过 Gaussian-like Mapping 机制,模型能像人类扫描图片一样,自动在特征图中“点亮”那些与文本名词匹配的显著对象。
- 语言注意力适配器 (Linguistic Attention Adapter):识别文本中的“重心”。比如在“那个大的”中,“大”这个形容词比其他词更具有区分度。该模块利用 Bi-GRU 捕捉上下文,自动调高这些关键描述词的权重。
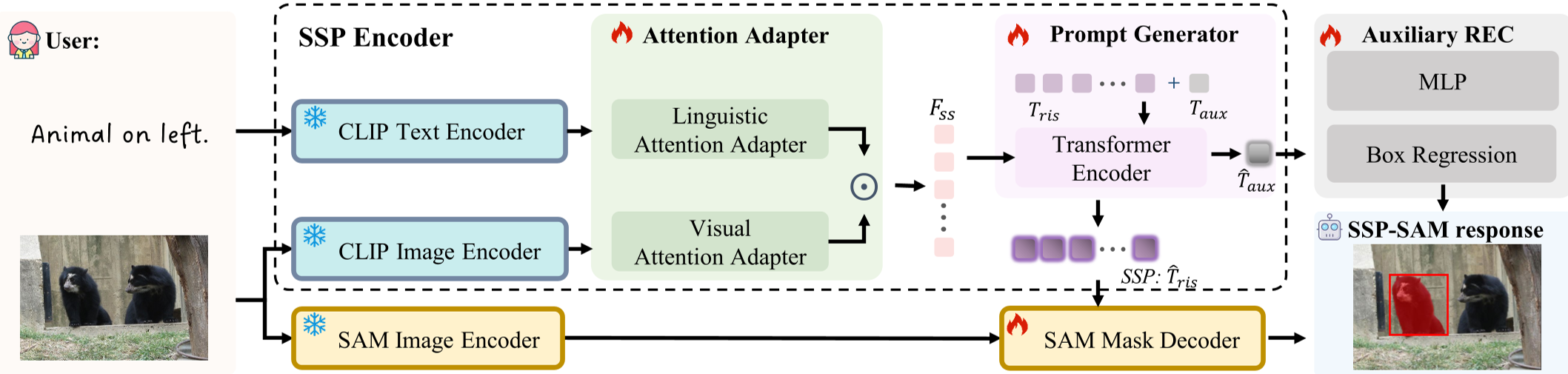 图 3:SSP-SAM 整体架构示意图
图 3:SSP-SAM 整体架构示意图
 图 4:Attention Adapter 内部细节
图 4:Attention Adapter 内部细节
3. 实验战绩:高精度与高效率的并存
SSP-SAM 的表现可以用“快、准、狠”来形容:
- 高阈值下的统治力:在非常苛刻的 Pr@0.9(即预测掩码与真值重叠度需达到 90% 以上才算对)指标下,SSP-SAM 超出了此前最强基线 CGFormer 多达 9%。这说明它生成的边界极其精准,而非模棱两可。
- 通杀 GRES 场景:在包含“无目标”和“多目标”的 gRefCOCO 上,SSP-SAM 无需针对性改动,便自然取得了最佳性能,其 N-acc(无目标识别准确率)显著增强。
- 工程化友好:其可训练参数仅为 18.37M。相比动辄几十亿参数的 MLLM 方案(如 LISA),它在单张 A100 上的推理耗时仅 26.68ms,这意味着它完全可以在实时交互系统中使用。
 表 2:在 RefCOCO 系列数据集上的性能对比
表 2:在 RefCOCO 系列数据集上的性能对比
4. 深度洞察:为什么 SSP 这么灵?
作者通过可视化发现,视觉适配器确实起到了“定位器”的作用(如图 8 所示,马和象在热力图中被精准点亮),而语言适配器则捕捉到了“Left”、“Larger”等判别词(图 9)。这种将语义与空间解耦后再融合的设计,恰恰补齐了 Transformer 架构在局部细节感知上的盲区。
此外,作者引入了 Referring Expression Comprehension (REC) 作为辅助任务。这种多任务联合训练让模型不仅要学会“怎么割”,还得先学会“在哪找”,利用现成的边界框标注数据大幅增强了 Prompt 的质量。
5. 局限与未来
尽管 SSP-SAM 在强空间提示的任务上表现极其卓越,但在 RefCOCO+(移除了方位词,纯靠外观描述)这种数据集上,由于它对空间词的依赖,提升幅度相对温和。
总结 (Takeaway):SSP-SAM 证明了在 CVPR/IEEE 级别的顶尖工作中,精妙的轻量级模块设计(Prompt Engineering 的物理化实现)往往比单纯堆砌算力和模型规模更具优雅色彩和工业价值。
关键词:SAM, CLIP, RES, GRES, Prompt Learning, 轻量级模型