本文提出了 Prompt Steering Replacement (PSR) 框架,旨在通过模仿提示词工程(Prompting)对大模型内部激活的影响来提升激活转向(Activation Steering)的效果。该方法在大规模生成任务、指令遵循和 AxBench 评估中,均表现出优于传统常数转向方法的性能,部分指标超越了 Prompting 记录。
TL;DR
传统的激活转向(Activation Steering)往往给所有 Token 加上一个“死板”的固定向量,导致模型生成质量受损。本文提出了 Prompt Steering Replacement (PSR),通过学习提示词工程(Prompting)在模型内部留下的“激活指纹”,让干预系数随 Token 动态变化。实验证明,PSR 不仅比传统方法更连贯,甚至在多个基准测试中超越了原生提示词的效果。
痛点深挖:为什么目前的转向方法“不自然”?
在对 LLM 进行对齐或行为控制时,Prompting 是最直接的手段,但它会占用上下文窗口且易受攻击;激活转向(Activation Steering)虽然轻量,效果却总是不尽如人意。
作者发现了一个关键直觉:提示词对模型的影响并不是均匀分布的。如图 2 所示,当使用提示词引导模型变得“谄媚”时,某些关键 Token(如标点或特定动词)的激活变化剧烈,而其他 Token 几乎不受影响。现有的 Constant Steering 方法强行在每个位置施加同样的力,这本质上破坏了模型预测的自然流向(Manifold)。
方法论:从蒸馏提示词到动态干预
PSR 的核心逻辑是:既然提示词做得好,我们就学它的干预轨迹。
1. 架构解析
作者将转向公式从 改进为: 其中 是一个基于当前激活值计算的标量。这意味着模型会根据“当下的语境”决定减弱还是增强干预强度。
2. 模型架构图
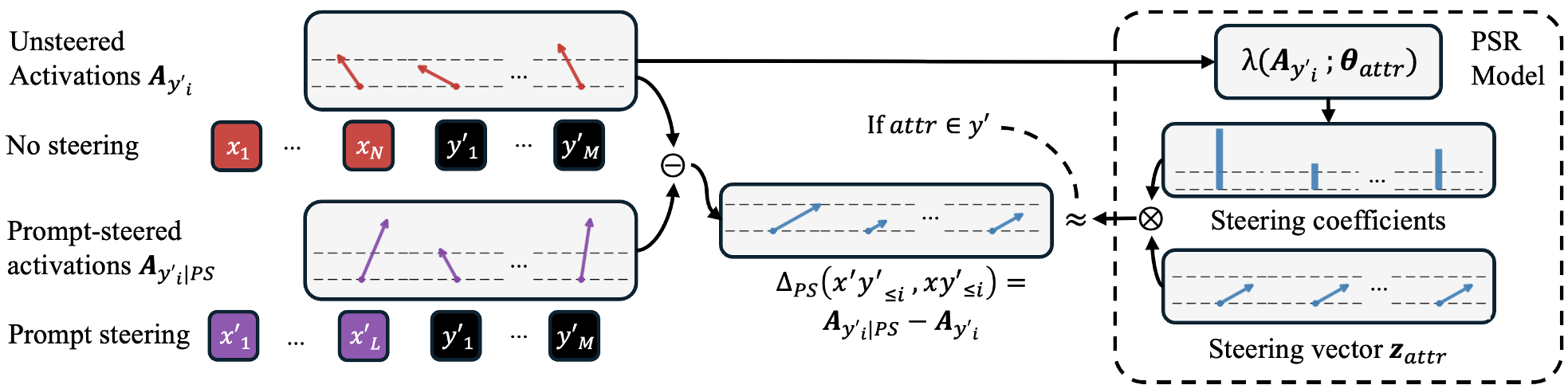 图 1:左侧记录提示词引导下的激活路径,右侧通过 PSR 模型最小化 MSE 或最大化对数似然(LL),从而在不使用提示词的情况下复现相同的转向效果。
图 1:左侧记录提示词引导下的激活路径,右侧通过 PSR 模型最小化 MSE 或最大化对数似然(LL),从而在不使用提示词的情况下复现相同的转向效果。
3. 两种训练目标
- MSE(均方误差):追求与提示词激活路径的高度一致(忠实性)。
- LL(对数似然):追求最终生成结果的准确性。在处理复杂格式逻辑(如 IFEval)时,LL 表现更佳,因为它允许模型寻找比原生提示词更优的内部表达。
实验与结果:全线突破
作者在 Llama 和 Qwen 系列模型上进行了广泛测试,涵盖了人格转向、指令遵循和 SAE 特征转向(AxBench)。
核心战绩:
- AxBench SOTA:A-PSR 在 Gemma-2-9B 上达到了 1.120 的转向得分,超过了提示词(1.075)和 HyperSteer 等强基线。
- 连贯性 vs. 强度:在图 13 的“强度-连贯性”曲线中,PSR 明显处于右上角,意味着在施加相同转向强度时,PSR 生成的内容更像人话。
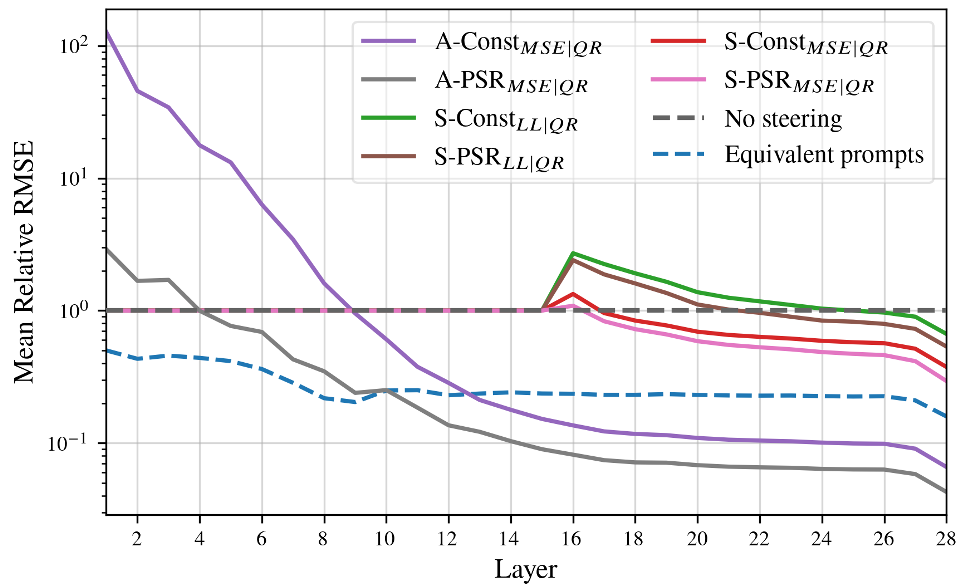 图 3:可以看到 A-PSR 的激活路径与提示词路径的 RMSE 极低,证明了其动态系数确实捕捉到了提示词工程的精髓。
图 3:可以看到 A-PSR 的激活路径与提示词路径的 RMSE 极低,证明了其动态系数确实捕捉到了提示词工程的精髓。
深度洞察:为什么 PSR 有效?
PSR 的成功揭示了 LLM 内部的计算冗余与敏感点。提示词工程实质上是在寻找模型内部的“分支点”,并在这些点上改变逻辑走向。PSR 通过学习这些敏感点(Branching Points),避免了在不重要的 Token 上添加噪声。
局限性
作者坦言,当前的 PSR 基于 Rank-1 假设(单方向转向)。在 IFEval 这种需要处理复杂参数(如“生成 3 个章节”)的任务中,单方向向量显得力不从心。这暗示了未来的研究方向:低秩(Low-rank)但多维的动态转向。
总结
PSR 告诉我们:最好的行为控制方法隐藏在模型自身的提示词处理机制中。通过将提示词工程“固化”为轻量的动态激活拦截器,我们既保留了 Prompting 的高质量,又获得了激活转向的高效率与鲁棒性。