本文提出了 StepPO,一种针对智能体(Agent)强化学习的步级策略优化框架。该方法将传统的 token 级 MDP 提升为 step 级 MDP,并结合步级信用分配(Step-level Credit Assignment),在 HotpotQA 等多步交互任务中显著超越了传统的 PPO 基线。
TL;DR
随着 Claude Code 和 OpenClaw 等通用智能体的崛起,LLM 的核心能力正从“单轮对话”向“多轮交互决策”演进。然而,传统的强化学习(RL)框架仍停留在 Token 层面。本文提出的 StepPO 明确指出:Step(步)才是智能体决策的最低有效单位,而非 Token。通过步级 MDP 建模和信用分配,StepPO 在复杂推理任务中显著提升了训练效率与最终性能。
痛点深挖:Token 级的迷思与重分词的陷阱
在传统的 RLHF 或 RLVR(如 DeepSeek 引发的 R1 热潮)中,模型通常一次性生成长段推理。但在 Agent 场景下,模型需要:观察 -> 思考 -> 调用工具 -> 接收反馈 -> 再次决策。
现有的方法往往面临两个致命问题:
- 粒度错配:Token 级 PPO 过于琐碎,无法理解“调用搜索工具”这一宏观决策的价值;而轨迹级(Trajectory-level)奖励(如 GRPO)又太笼统,很难告诉模型是第 3 步还是第 5 步做得好。
- Retokenization Drift(重分词漂移):当 Agent 交互记录为了存储被转为文本,训练时再次 Tokenize 会产生位置偏移,导致预测概率(log-probs)和掩码(masks)失效,训练瞬间崩溃。
Methodology:步级对齐的艺术
1. 从 Token-level 到 Step-level MDP
StepPO 将 MDP 的状态转移从 重新定义为步级转移。每一次 都是一个完整的动作块(可能包含思考、Action 和环境返回的 Observation)。
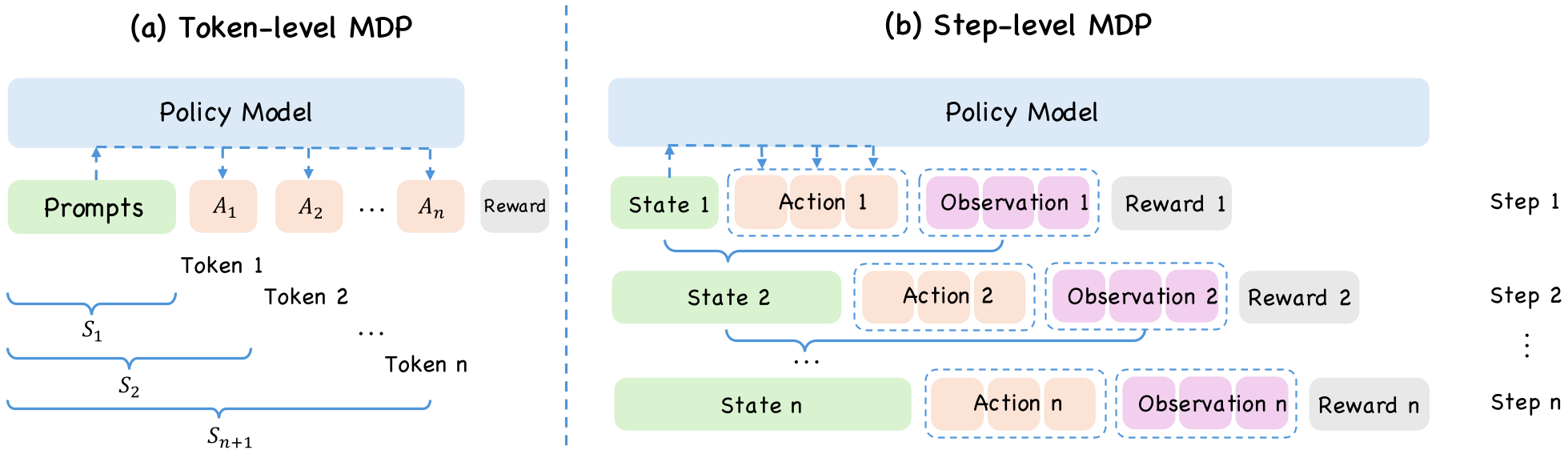 图 1:Token 级与 Step 级 MDP 的本质区别:关注点从字符序列转向了交互回路。
图 1:Token 级与 Step 级 MDP 的本质区别:关注点从字符序列转向了交互回路。
2. 步级信用分配 (Step-level Credit Assignment)
这是 StepPO 的数学核心。为了让模型在早期就能学到关键决策(如决定搜索而非瞎猜),StepPO 引入了步级 GAE(Generalized Advantage Estimation): 这里 是对当前步骤状态而非单个 Token 的价值估计。这种做法完美平衡了延迟奖励的传播与决策粒度的精准度。
3. 系统层的支撑:Agent-R1 与 Claw-R1
算法的落地离不开系统支持。论文提到了两条演进路径:
- Agent-R1:解决了 Token 空间的一致性,确保“所见即所练”。
- Claw-R1:引入了 Gateway(网关)和 DataPool(数据池)设计,支持异构 Agent 的异步数据采集,解决了训练等待 Rollout 的效率瓶颈。
实验胜出:HotpotQA 的有力证明
在 HotpotQA(一个需要多步检索和推理的复杂数据集)上,StepPO 展现出了压倒性的优势。
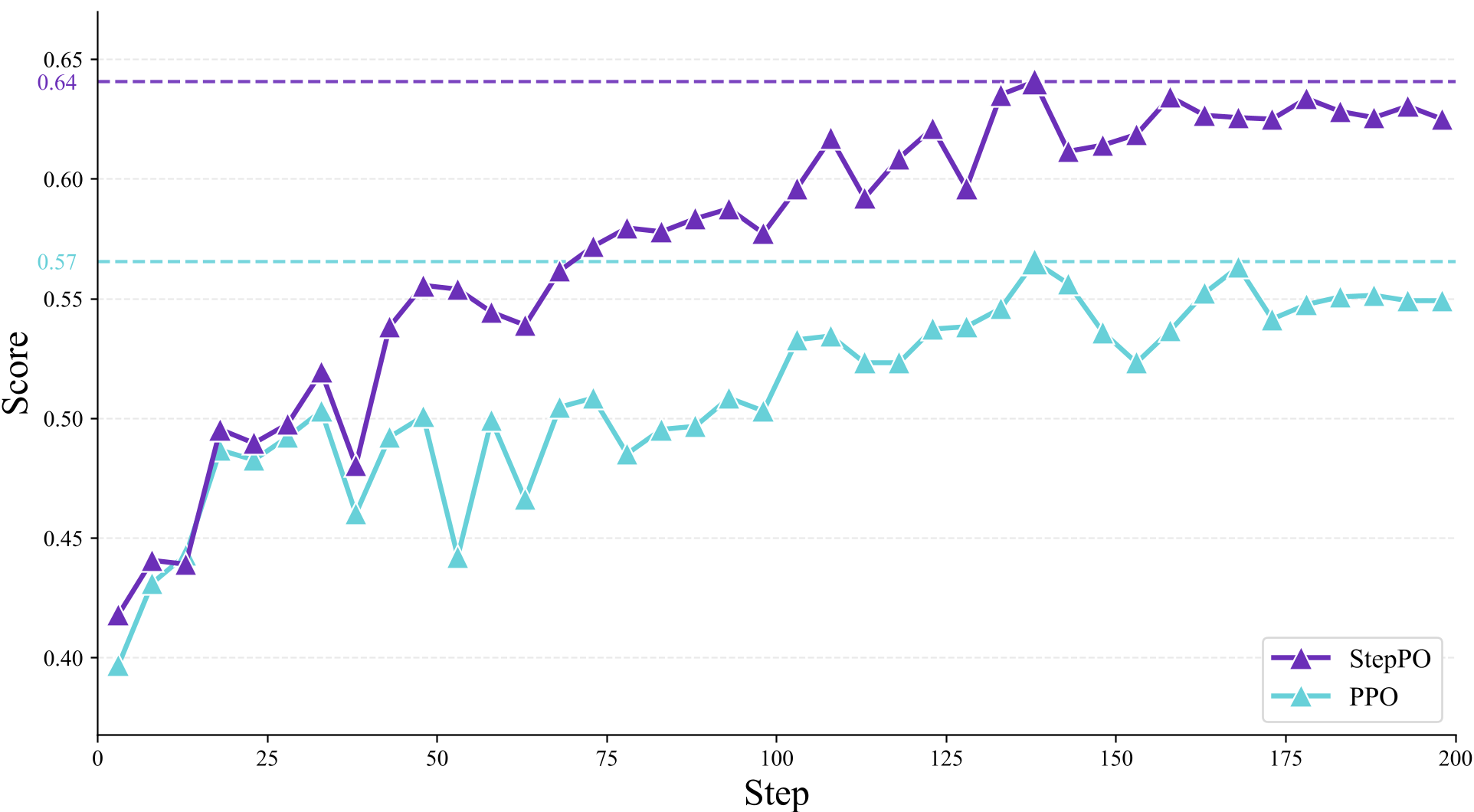 图 2:HotpotQA 训练曲线。可以看到 StepPO (蓝线) 在模型收敛速度和最高 Accuracy 上均显著优于传统的 Token-level PPO。
图 2:HotpotQA 训练曲线。可以看到 StepPO (蓝线) 在模型收敛速度和最高 Accuracy 上均显著优于传统的 Token-level PPO。
深度洞察:为什么这很重要?
StepPO 不仅仅是一个算法的改进,它代表了学术界对 Agentic RL 物理本质的重新认识:
- Inductive Bias(归纳偏置)的转变:将交互单元硬编码进优化目标。
- 工程与算法的合流:它承认了异步系统和结构化存储(Structured Representation)在现代 AI 训练中的核心地位。
总结与展望
StepPO 证明了:当 LLM 开始作为 Agent 与世界互动时,我们必须停止把它当作“概率续写机”,而要把它作为“决策路由器”。虽然在异构智能体处理、异步漂移等方面仍有挑战,但“步级对齐”无疑是通向通用人工智能(AGI)智能体能力的必经之路。
Takeaway: 优秀的 Agent 训练框架,必须在粒度上与人类的决策直觉对齐。StepPO 的成功,正是对这一原则的践行。