Stream-T1 是一种专门为分块(Streaming)视频生成设计的测试时缩放(Test-Time Scaling, TTS)框架。它通过在推理阶段动态优化潜空间噪声和 KV-cache 内存,在无需额外训练的情况下,显著提升了 5s 至 30s 长视频生成的时空一致性与运动平滑度。
TL;DR
传统的视频生成模型在追求“更长、更稳”的道路上正面临训练成本指数级增长的困境。来自中国科学技术大学等机构的研究团队提出了 Stream-T1,这是首个专为流式视频生成定制的测试时缩放(Test-Time Scaling, TTS)框架。它通过“边搜边生成”的策略,在推理侧动态优化生成轨迹,使 30 秒长视频的时空一致性、运动平滑度和细节质量达到了新的高度,而无需重新训练模型。
背景定位:为何传统的 TTS 在视频上“跑不动”?
在 LLM 领域,像 OpenAI o1 或 DeepSeek-R1 已经证明了“推理时计算”可以换取更强的逻辑能力。但在视频扩散领域,简单移植 TTS 会遇到巨大阻碍:
- 维度爆炸:一次性去噪几十帧视频的搜索空间太大。
- 缺乏纠错机制:如果第 10 帧崩了,传统方法只能重画整个视频,极其低效。
Stream-T1 的核心直觉在于:利用流式生成(Chunk-by-chunk)天然的自回归特性。每次只处理一个小块(Chunk),去噪步数少(仅需 4 步左右),这为推理时的候选搜索和动态修复提供了完美的切入点。
核心方法论:主动优化的三大支柱
1. 流式噪声传播 (Stream-Scaled Noise Propagation)
作者发现,与其用纯随机的高斯噪声开始每一块的生成,不如利用“历史经验”。通过球面插值(Spherical Interpolation),将前一块高质量候选分支的噪声先验传递给当前块。这种做法不仅缩小了搜索空间,更在潜空间(Latent Space)层面锚定了时序的连续性。
2. 长短期联合奖励剪枝 (Stream-Scaled Reward Pruning)
为了选出最好的候选分支,Stream-T1 设计了一个双重导航系统:
- 短期得分:使用 ImageReward 评估单帧的审美(解决“画得好不好”)。
- 长期得分:在滑动窗口内使用视频奖励模型评估语义对齐和运动连贯性(解决“动得对不对”)。 通过动态权重融合这两者,模型能有效避免由于过分关注细节而导致的“画面停滞”(Frame Stagnation)现象。
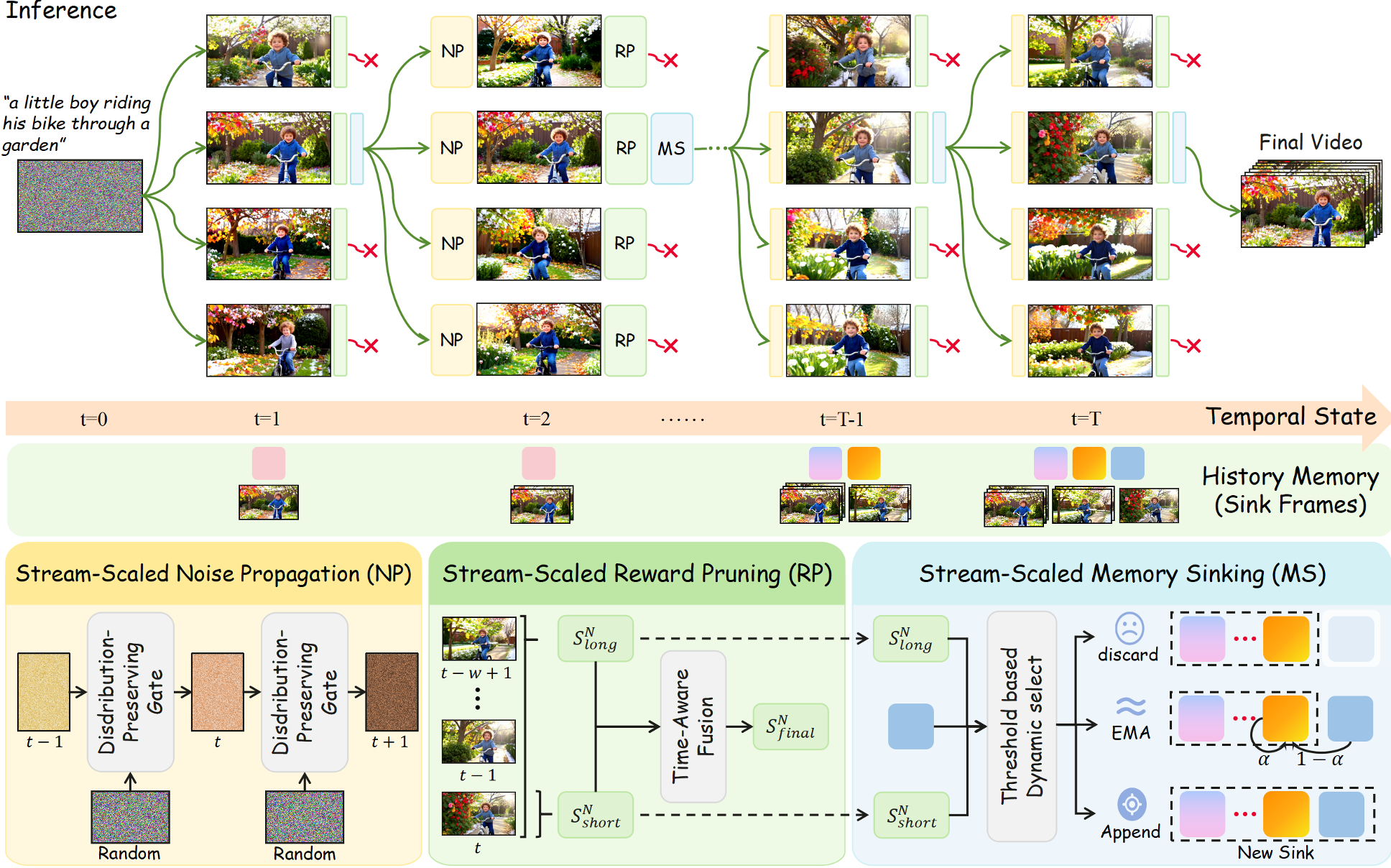 图 1: Stream-T1 整体管线,展示了从噪声传播到奖励剪枝,最后到内存下沉的循环流程。
图 1: Stream-T1 整体管线,展示了从噪声传播到奖励剪枝,最后到内存下沉的循环流程。
3. 动态内存下沉 (Stream-Scaled Memory Sinking)
这是本文最具启发性的创新。传统的 KV-cache 管理往往是粗暴的丢弃或固定的 EMA 融合,这会导致视频生成后期出现“语义漂移”。Stream-T1 引入了语义边界检测:
- Discard:质量差的分块直接丢弃,不污染由于后期参考。
- EMA-Sink:场景平滑时,将冗余信息融合进 Sink,节省显存。
- Append-Sink:检测到场景转换或剧烈运动时,将其作为新的“锚点”直接存入缓存,防止模型“忘本”。
实验战绩:全方位的 SOTA 提升
研究人员在 5s(VBench)和 30s(MovieGen prompts)基准上进行了严苛测试。实验结果显示,Stream-T1 在维持背景一致性和运动平滑度方面表现极其强悍。
 表 1: 在 30s 长视频生成上的量化对比。可以看到 Stream-T1 在各种一致性指标上全面超越了 LongLive 和 Self-forcing 等基线。
表 1: 在 30s 长视频生成上的量化对比。可以看到 Stream-T1 在各种一致性指标上全面超越了 LongLive 和 Self-forcing 等基线。
在定性测试中(如图 4 所示),Stream-T1 生成的视频在长时间跨度下依然能保持主体的形状不崩坏,且背景不再随摄像机移动而产生扭曲。
深度洞察与总结
Stream-T1 的核心价值在于变“被动采样”为“主动引导”。它不仅是视频生成领域的 SOTA 刷榜工具,更揭示了一个重要趋势:在大模型时代,推理侧的智能(Test-Time Compute)或许能够弥补训练数据或模型参数量的不足。
局限性:尽管优化了流程,但 Beam Search 带来的额外计算开销在实时场景下仍是不小的挑战。此外,奖励模型本身的偏好偏差(Reward Bias)也可能在极长视频生成中引入累积误差。
未来展望:这种“奖励引导内存”的思路极具普适性,未来有望应用在包括 3D 生成、长文本对话乃至在线强化学习等多个需要长程一致性的领域。