StreetForward is a pose-free and tracker-free feedforward framework for dynamic street reconstruction. It utilizes a novel Causal Masked Attention mechanism within a Transformer-based architecture to estimate 3D Gaussian Splatting (3DGS) representations and per-pixel velocities, achieving SOTA depth estimation and high-fidelity 4D novel view synthesis.
Executive Summary
TL;DR: StreetForward is a breakthrough in 4D autonomous driving simulation. It reconstructs complex, dynamic street scenes from unposed images in a single feedforward pass—eliminating the need for time-consuming per-scene optimization, camera poses, or external trackers. By introducing Causal Masked Attention, it captures precise motion vectors and high-fidelity geometry, setting new benchmarks on the Waymo Open Dataset.
Positioning: This work moves beyond the "static-first" bias of previous Visual Geometry Transformers (VGGT). It bridges the gap between fast feedforward inference and the high-precision requirements of dynamic urban environments, serving as a foundational architecture for high-fidelity simulators and world models.
The "Unordered" Problem in 4D Reconstruction
Prior feedforward methods like VGGT were designed for Structure-from-Motion (SfM) tasks where image order doesn't necessarily matter. However, in a driving sequence, time is a vector. Existing "Alternating Attention" (AA) mechanisms treat tokens from all frames equally. This global symmetry is a weakness: it fails to represent the directed flow of motion from to , leading to ghosting artifacts and "geometry degradation" where moving objects appear as translucent smears.
Methodology: Causal Dynamics & Gaussian Splatting
The core innovation of StreetForward lies in its Causal Dynamics Modeling. Instead of letting the Transformer look at every frame simultaneously, the authors inject a frame-structured binary mask into the attention heads.
1. Causal Masked Attention
The model restricts query-key pairs to specific source-target relations. This forces the latent representations to focus purely on the temporal delta between adjacent frames, making the features inherently "motion-aware."
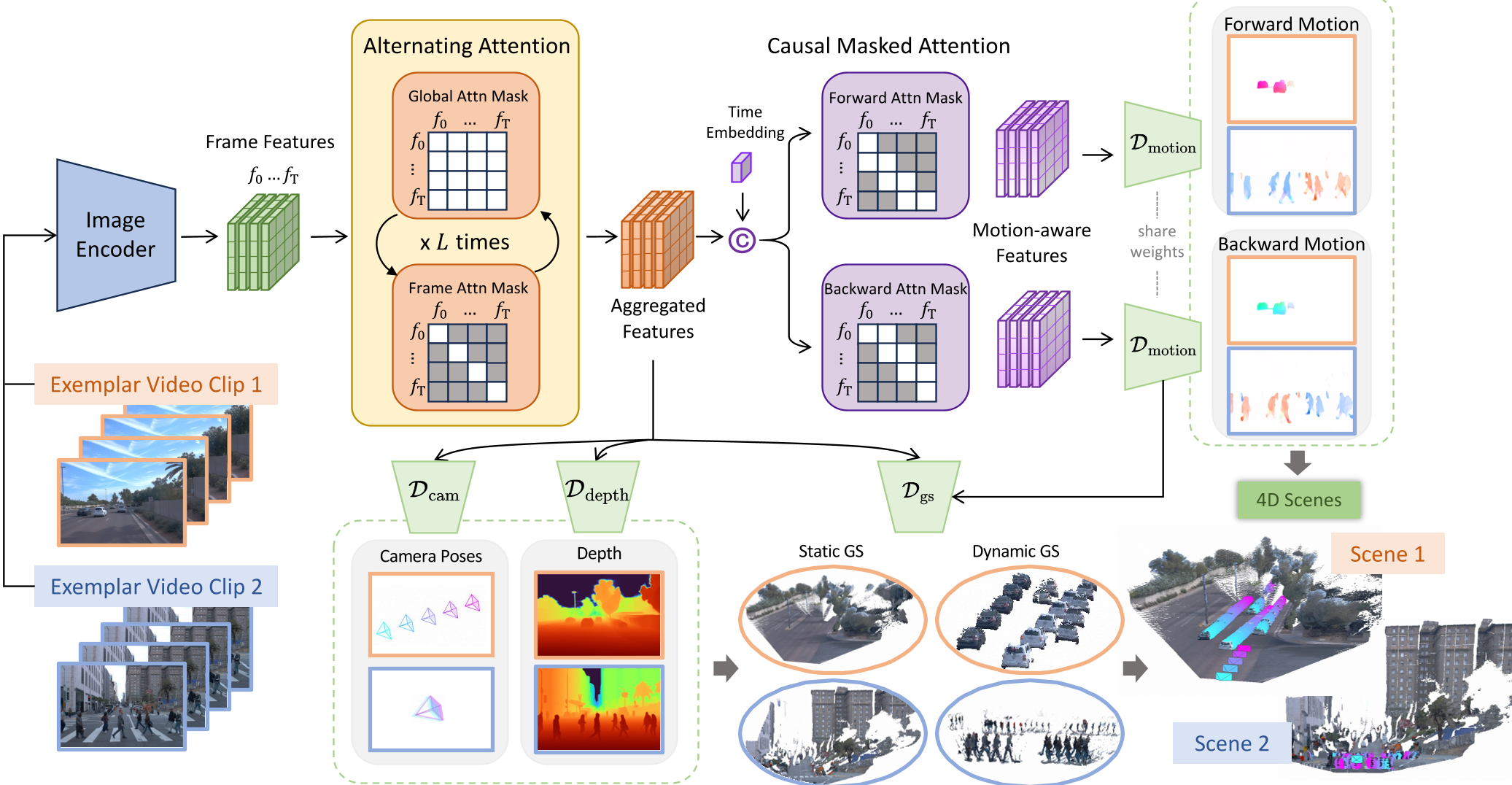 Figure 1: The StreetForward pipeline. Note the Causal Dynamics module that decodes per-pixel velocities ( and ) to warp dynamic Gaussians across time.
Figure 1: The StreetForward pipeline. Note the Causal Dynamics module that decodes per-pixel velocities ( and ) to warp dynamic Gaussians across time.
2. Joint Static-Dynamic Optimization
StreetForward represents the world using 3D Gaussian Splatting (3DGS).
- Static Content: Primitives persist across the whole sequence.
- Dynamic Content: Primitives are transformed using the decoded per-pixel velocity field.
- No Supervision: Crucially, the model learns these velocities without 4D labels, relying instead on Spatio-temporal Consistency (rendering the current frame using warped Gaussians from adjacent frames).
Experimental Results: Precision and Generalization
The results on the Waymo Open Dataset are striking, particularly in geometric accuracy.
Superior Geometry
StreetForward achieves a Full Image Depth RMSE of 3.14m, significantly outperforming the previous state-of-the-art DGGT (4.08m) and STORM (5.48m). The improvement in dynamic regions is even more pronounced (RMSE 3.45m vs DGGT's 6.37m).
Novel View Synthesis
When it comes to "seeing around corners" (spatial extrapolation) or predicting future states (temporal extrapolation), StreetForward produces much cleaner results than tracking-based methods.
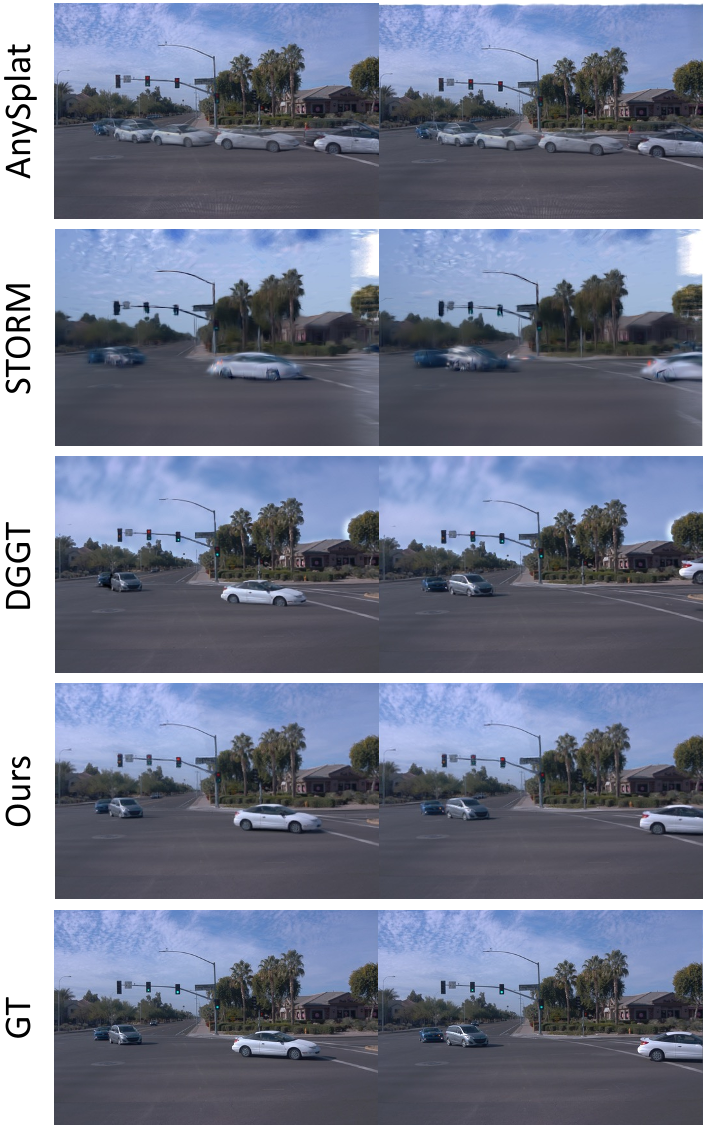 Figure 2: Qualitative comparison. Notice how StreetForward reconstructs sharp, complete vehicle geometries and thin structures like traffic poles, whereas DGGT or STORM suffer from "sky-drifting" or blurred boundaries.
Figure 2: Qualitative comparison. Notice how StreetForward reconstructs sharp, complete vehicle geometries and thin structures like traffic poles, whereas DGGT or STORM suffer from "sky-drifting" or blurred boundaries.
Zero-Shot Robustness
To test generalization, the authors ran the Waymo-trained model on CARLA data. StreetForward maintained its lead, proving that the causal motion priors it learns are physically grounded and not just overfitting to the Waymo sensor suite.
Critical Insight & Conclusion
The success of StreetForward highlights a pivotal shift: Inductive Bias Matters. While "General Transformers" are powerful, 4D reconstruction is a physical task governed by the arrow of time and the rigidity of objects. By baking these constraints into the attention mechanism (Causal Mask) and loss functions (Rigidity Regularization), StreetForward achieves what scaling alone could not.
Limitations: While the model handles rigid and deformable objects (like pedestrians), very high-speed motion across extreme frame drops might still challenge the constant-velocity assumption used in the temporal loss.
Future Outlook: StreetForward paves the way for "Instant Digital Twins" of any city street captured by a single pass of a camera-equipped vehicle, a holy grail for testing autonomous driving stacks in closed-loop simulations.