The paper introduces SWE-QA-Pro, a novel repository-level code understanding benchmark and a scalable training recipe (SFT+RLAIF). It focuses on long-tail repositories and emphasizes agentic exploration over simple knowledge retrieval, where a tuned Qwen3-8B outperforms GPT-4o by 2.3 points after reinforcement learning.
TL;DR
SWE-QA-Pro is a new benchmark and training framework designed to force LLMs to actually read and navigate codebases rather than reciting memorized knowledge. By filtering out "easy" questions and applying a specialized SFT → RLAIF training recipe, the researchers enabled a Qwen3-8B model to surpass GPT-4o in complex, repository-wide software engineering tasks.
The "Cheating" Problem in Code Benchmarks
In the world of AI software engineering, many benchmarks are "contaminated." Because models like GPT-4 are trained on the entirety of GitHub, they don't actually need to explore a popular repository to answer a question about its architecture—they've already "read" it during pre-training.
The SWE-QA-Pro Insight: To fix this, the authors did two things:
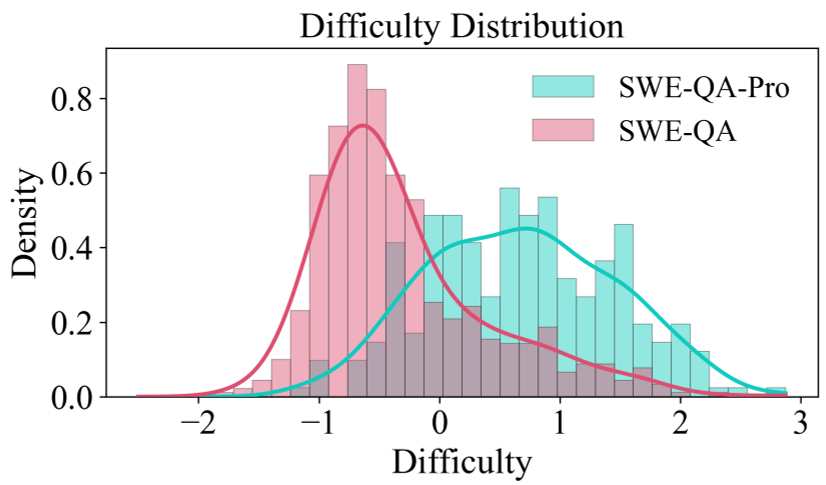
- Long-tail Repositories: They used 26 less-known repos to ensure the models couldn't cheat using memory.
- Difficulty Calibration: They tested questions against a suite of top-tier models (GPT-4o, Claude 4.5, Gemini 2.5). If a model could answer correctly without looking at the code, the question was deleted.
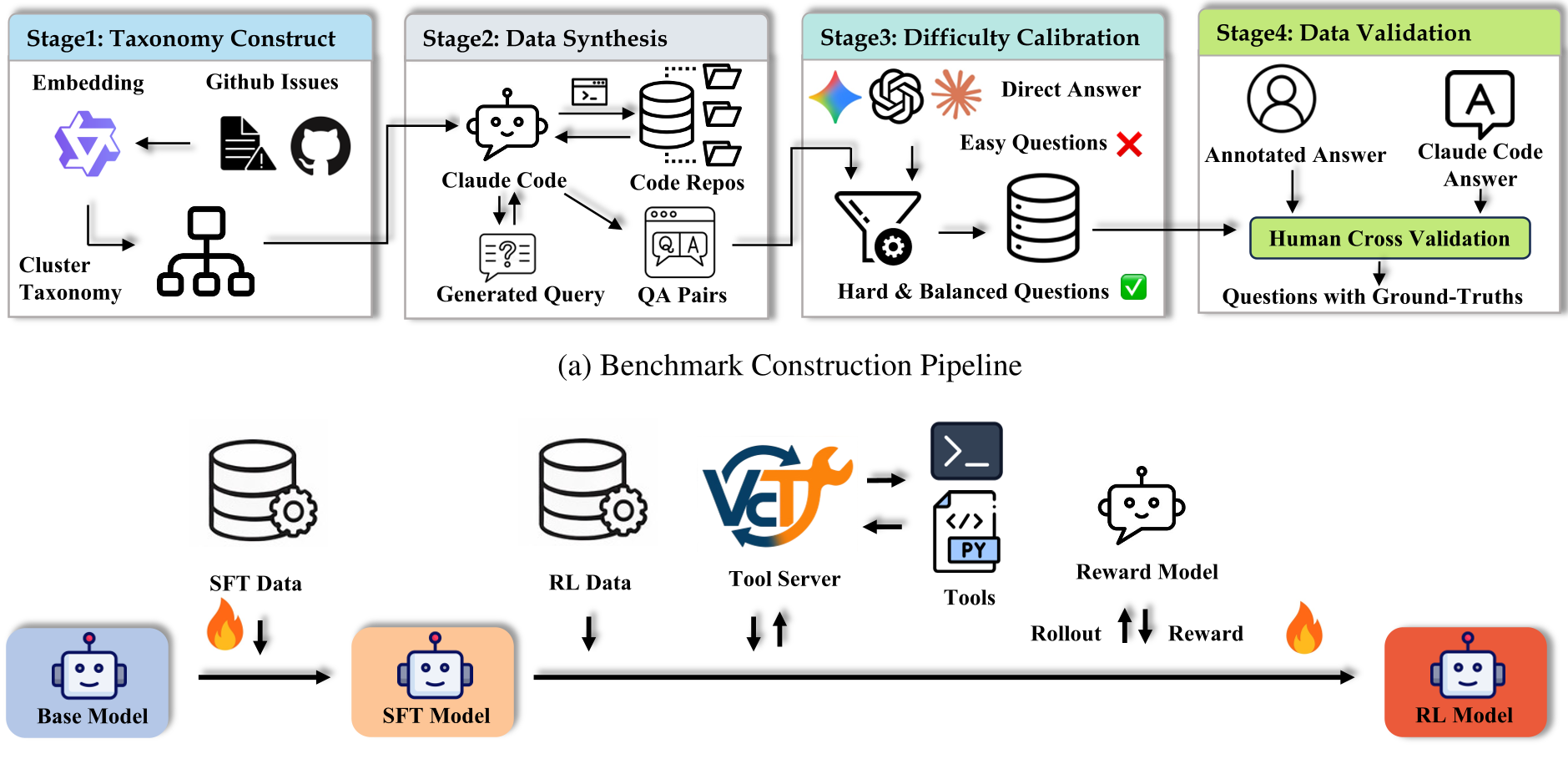
Methodology: The ReAct Agent & RLAIF Recipe
The SWE-QA-Pro Agent moves away from standard Retrieval Augmented Generation (RAG). Instead of searching for snippets, it uses a ReAct loop (Reasoning + Acting) to perform:
- Semantic Search: Locating files by intent.
- ViewCodebase: Scoped inspection of symbols and directories.
- CommandLine: Lightweight analysis (grep, symbols).
The Two-Stage Training
To make an 8B model proficient, the authors used:
- Stage 1 (SFT): 1,000 trajectories teaching the model the "syntax" of calling tools.
- Stage 2 (RLAIF): Using Group Relative Policy Optimization (GRPO). The reward was based on 5 dimensions: Correctness, Completeness, Relevance, Clarity, and Reasoning. Crucially, the model was rewarded for citing specific file paths and line numbers.
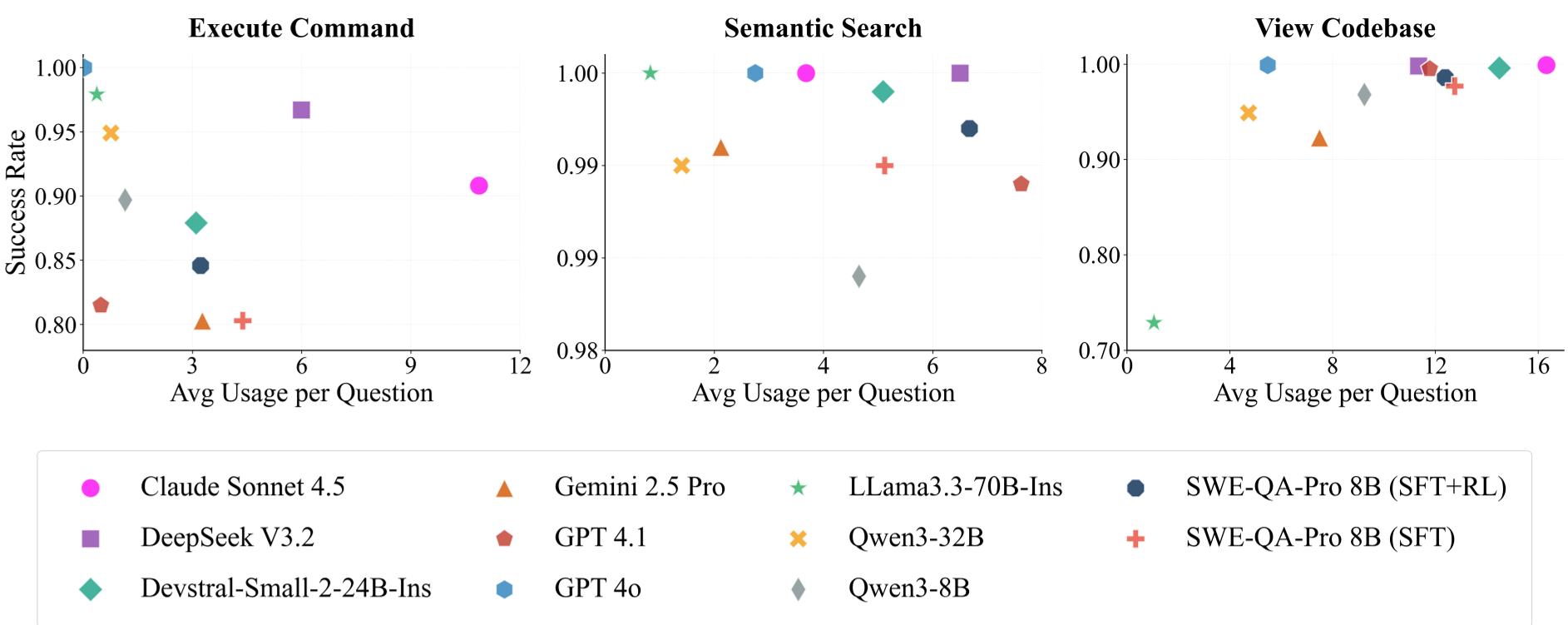
Experimental Showdown
The results confirm that agentic behavior is the "X-factor" for code understanding.
- The Gap: Without agents, models scored poorly (~26-28). With the agentic workflow, Claude Sonnet 4.5 jumped to 40.67.
- Open-Source Triumph: The SWE-QA-Pro-8B (SFT+RL) model hit 35.39, beating the standard GPT-4o Agent (33.08).

Critical Insight: Tool Usage vs. Reasoning
Interestingly, more tool calls don't always mean better results. Gemini 2.5 Pro achieved high scores with fewer tool calls, suggesting superior internal "planning." On the other hand, the RL stage for the 8B model specifically improved its ability to be "judicious"—it learned when to stop searching and start synthesizing.
Conclusion & Future Outlook
SWE-QA-Pro proves that we don't necessarily need a 400B parameter model to navigate a codebase. By training specifically for agentic interaction and rewarding grounded evidence, small models can behave like senior developers.
Limitations: The benchmark is currently focused on Python. Future work will need to expand to C++ and Rust to test the model's cross-language logic.