The paper introduces TAG (Target-Agnostic Guidance), a novel inference-time guidance mechanism designed to improve the robustness of Vision-Language-Action (VLA) models. By contrasting standard observations with "target-erased" counterfactuals, TAG effectively filters out distractor-induced biases, achieving state-of-the-art performance on benchmarks like LIBERO and VLABench (e.g., +26% SR on complex manipulation tasks).
Executive Summary
TL;DR: Even the most advanced Vision-Language-Action (VLA) models, such as π0, often fail at the finishing line—grasping a distractor instead of the target or landing just a few millimeters off. This paper identifies instance-level grounding as a core bottleneck and proposes Target-Agnostic Guidance (TAG). By contrasting real observations with "object-erased" counterfactuals, TAG provides a residual steering signal that effectively amplifies target evidence and filters out background clutter.
Academic Positioning: This work builds on the powerful foundations of Flow-Matching VLA models like π0/π0.5. It shifts the focus from better action tokenization or transformer scaling to specialized inference-time guidance to tackle the "last-mile" precision problem.
Problem & Motivation
The "Plausible Grasp" Paradox
Modern VLA policies (RT-2, OpenVLA, π0) are excellent at motion planning. They can reach the table, avoid collisions, and orient their grippers. However, in cluttered scenes—like a workspace filled with multiple poker cards—they often produce a perfect trajectory but land on the wrong card.
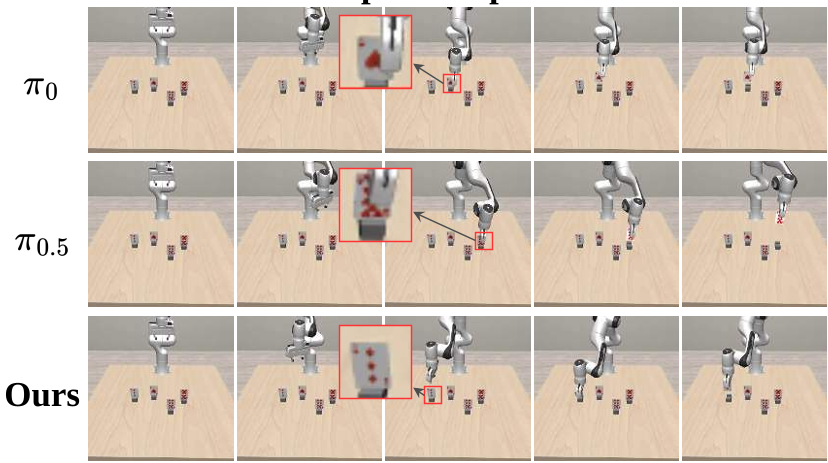
The authors identify that these failures stem from over-reliance on background appearance statistics. The model learns to act based on global context (the scene) but fails to isolate the target-specific "grounding" signal when multiple similar objects (distractors) are present.
Methodology: Target-Agnostic Guidance (TAG)
The Vision-Centric CFG
Inspired by Classifier-Free Guidance (CFG) in diffusion models, TAG proposes that a policy prediction should be steered by the difference between a target-present observation and a target-agnostic one.
Mathematically, given a velocity field $v_ heta$, TAG computes: $$v_{ ext{TAG}} = v_ heta(x_ au, I_{ ext{uncond}}) + w \cdot (v_ heta(x_ au, I_{ ext{cond}}) - v_ heta(x_ au, I_{ ext{uncond}}))$$
Where $I_{ ext{uncond}}$ is an "erased" version of the image. This subtraction effectively cancels out environmental noise and prior biases, leaving only the action component driven by the specific task target.
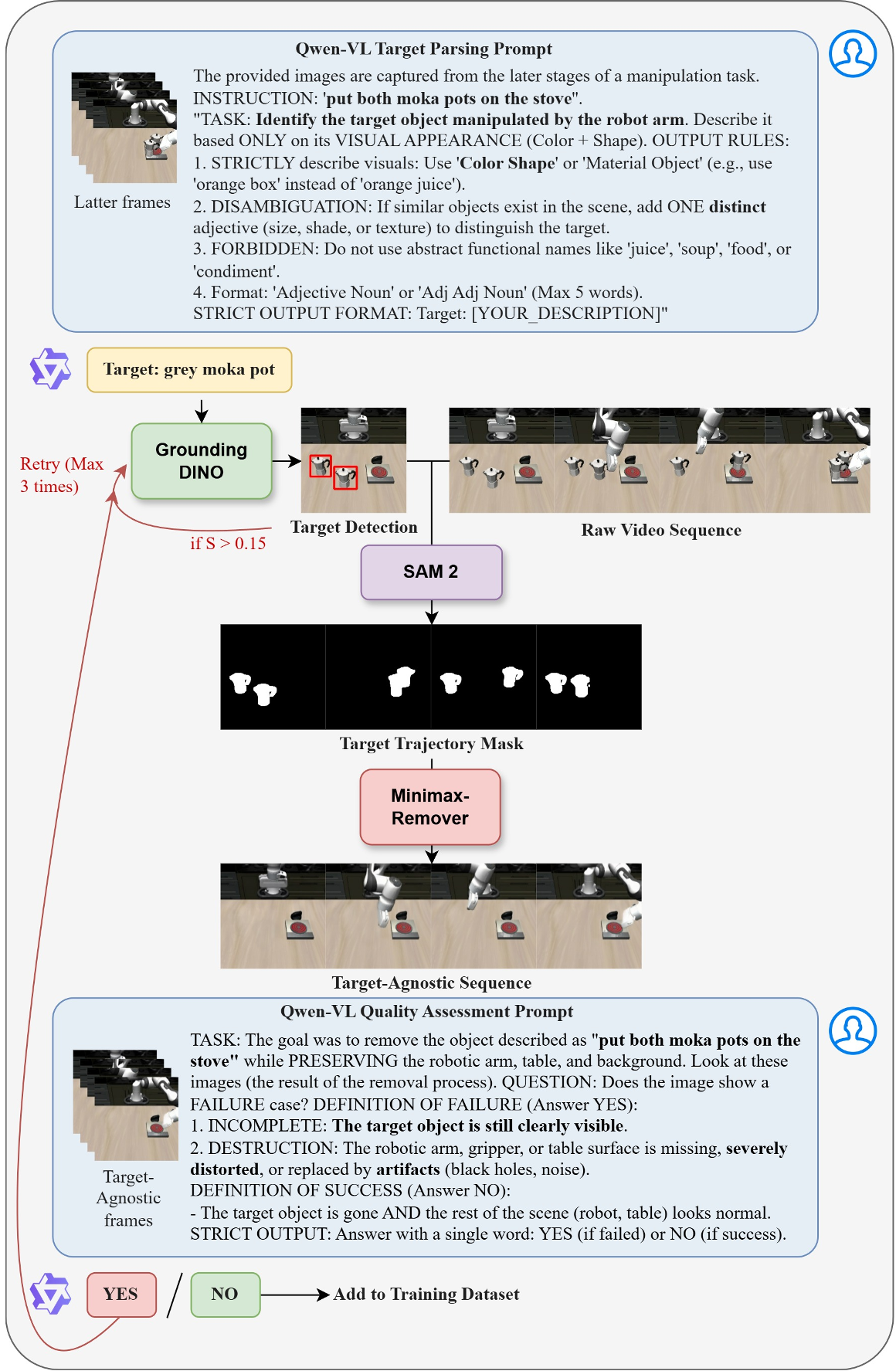
The Counterfactual Synthesis Pipeline
To make this work, the authors created an automated "data factory":
- Target Parsing: Qwen3-VL extracts a visual description of the target from the instruction.
- Detection & Tracking: Grounding DINO and SAM 2 localize the target across video frames.
- Inpainting: MiniMaxRemover "removes" the target and fills in the background, creating a counterfactual sequence.
Experiments & Results
LIBERO and VLABench Breakthroughs
The effectiveness of TAG is most evident in highly cluttered environments.
- In LIBERO-Long, which requires long-horizon planning prone to compounding errors, TAG increased the π0.5 success rate from 89.6% to 97.0%.
- In VLABench Track 1 (e.g., Selecting aSpecific Poker card), the success rate more than doubled (29.4% to 55.4%).
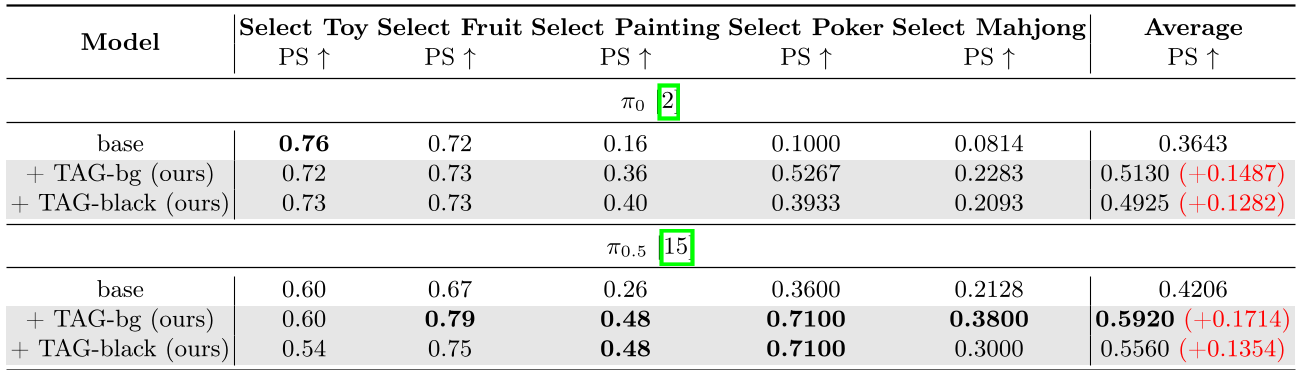
Ablation Study: Why Static Backgrounds Matter?
One key finding was that static backgrounds ($I_{bg}$) performed far better than real-time dynamic erasure. Frame-wise masking during inference introduced temporal artifacts that confused the spatial reasoning of the model. Using a clean, pre-intervention background provided a much more stable "anchor" for the subtraction process.
Critical Analysis & Conclusion
Takeaway
TAG provides a modular, "drop-in" improvement for any VLA model that uses iterative refinement (like Diffusion or Flow-Matching). It proves that explicit visual disentanglement at inference time is a powerful tool for achieving high-precision grounding without needing massive new architectural changes.
Limitations & Future Work
- Computation Overhead: Running the model twice (conditional and unconditional) at each inference step increases latency—though the authors imply this is manageable.
- Imperfect Erasure: If the inpainting model fails or removes too much (like the robotic arm itself), the guidance signal might become misleading.
In conclusion, TAG is a significant step toward making robots more reliable in messy, real-world environments. By simply training the model to know what the world looks like without the target, we empower it to act much more decisively with the target.