TARo (Token-level Adaptive Routing) is a novel test-time alignment framework that steers frozen Large Language Models (LLMs) toward structured reasoning during inference. By employing a learnable token-level router to dynamically blend base model and reward model logits, it achieves significant SOTA improvements, particularly a +22.4% accuracy boost on the MATH500 benchmark.
TL;DR
Training Large Language Models (LLMs) for complex reasoning is traditionally a heavy-duty task involving Reinforcement Learning with Verifiable Rewards (RLVR). TARo (Token-level Adaptive Routing) flips the script: it achieves SOTA reasoning performance by keeping the base model frozen and using a tiny, learnable router to dynamically inject "logical wisdom" from a small reward model during the generation process. It delivers an impressive +22.4% gain on MATH500 and successfully scales from 8B to 70B models without retraining.
Problem: The Fragility of Fixed Alignment
Standard test-time alignment methods usually combine a base model and a reward model using a fixed coefficient (e.g., ).
However, the authors identify a critical "Goldilocks problem":
- Hyperparameter Sensitivity: An might work for Llama but destroy Qwen’s performance.
- Domain Rigidity: A weight optimized for Math might be disastrous for Medical QA or general conversation.
- Temporal Inconsistency: During a single sentence, you might need the reward model's logic for a formula, but the base model's fluency for the surrounding text.
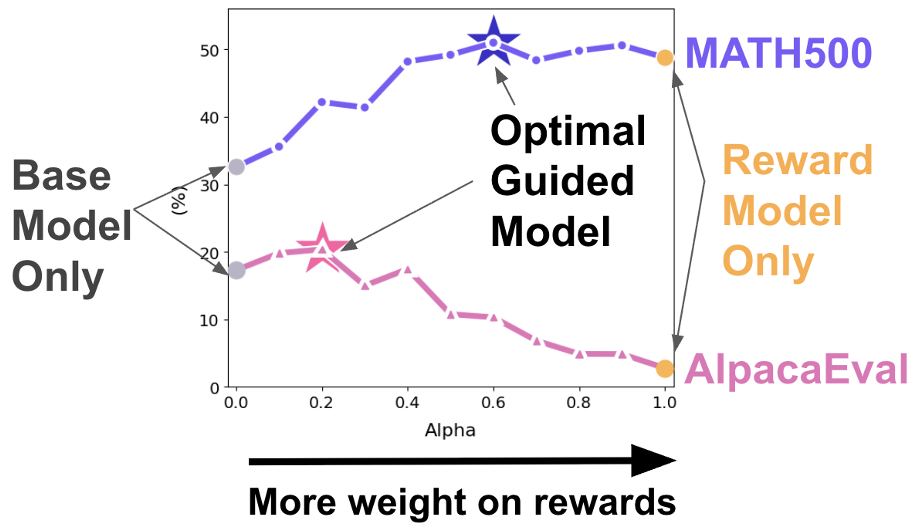 Figure 1: Showing how static mixing (GenARM) fluctuates wildly in performance compared to the adaptive TARo approach.
Figure 1: Showing how static mixing (GenARM) fluctuates wildly in performance compared to the adaptive TARo approach.
Methodology: The "Brain" in the Router
TARo introduces a two-stage solution to enable flexible reasoning:
1. Step-wise Reasoning Reward Model
Instead of generic preference pairs, the authors train the Reward LLM on Math-StepDPO, focusing on fine-grained logical consistency. The reward is decomposed into token-level log-likelihoods, providing a dense signal for every single character generated.
2. The Adaptive Token-level Router
This is the core innovation. A lightweight MLP "router" looks at the logits (the probability distributions) of both the base and reward models. It then outputs a scalar that decides exactly how much to mix the two models at that specific moment.
The authors tested two input designs for the router:
- Full-logits: Concatenating the entire vocabulary distribution (powerful but expensive).
- Top-K + Index Embedding: Looking only at the most likely candidates (efficient and scalable).
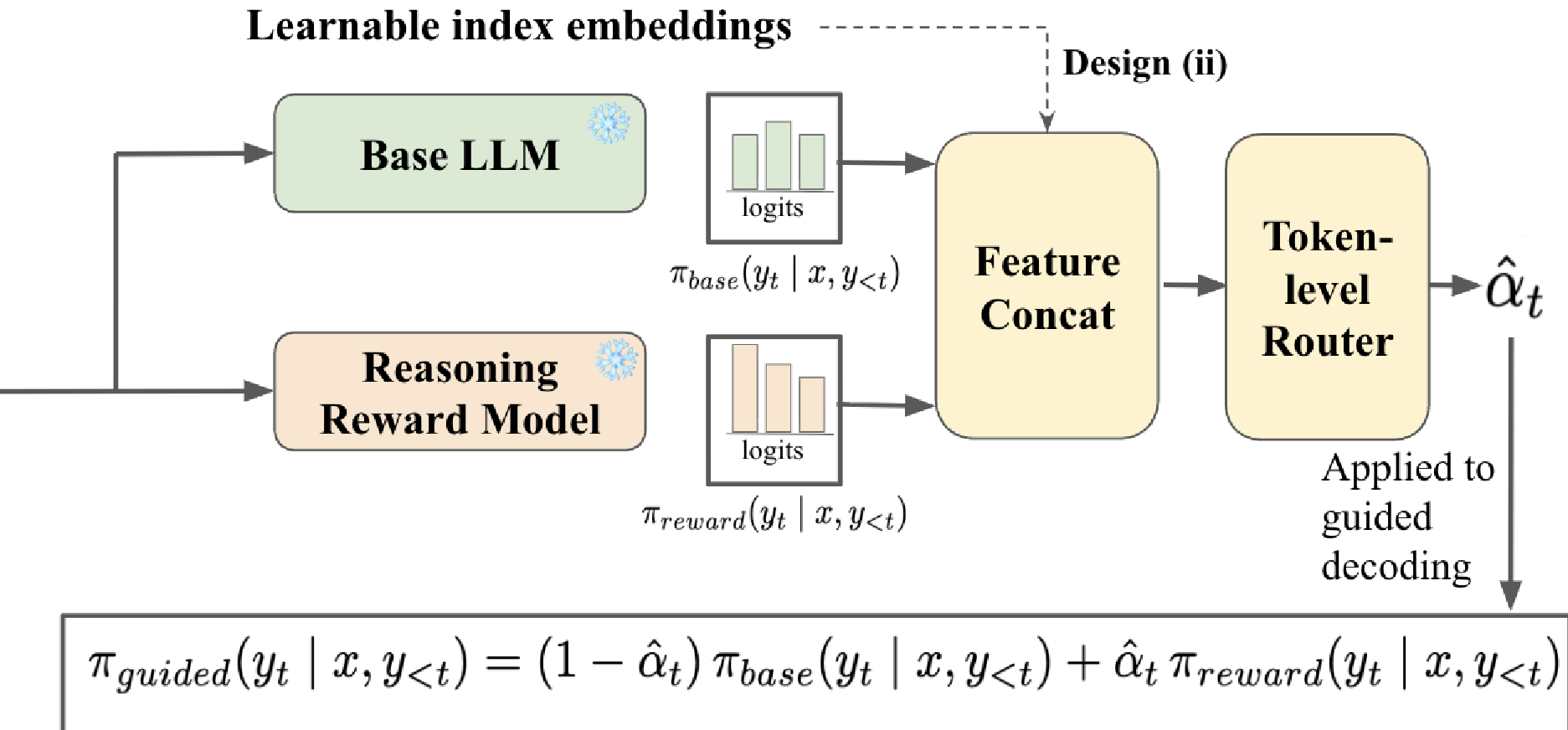 Figure 2: The TARo architecture – the router acts as a dynamic gatekeeper between the Base and Reward distributions.
Figure 2: The TARo architecture – the router acts as a dynamic gatekeeper between the Base and Reward distributions.
Why it Works: The Logical Partition
An interesting discovery in the paper is which tokens the router favors.
- High (Follows Reward): Mathematical operators (, ), structural scaffolds (Step, Case, Evaluate).
- Low (Follows Base): Contextual words (students, profit, squares, period).
The router intuitively learns that the base model is better at understanding the "story" of the problem, while the reward model is the "math specialist" called in only when logical transformations are needed.
Experimental Results: SOTA Gains & Scaling
TARo was tested against heavyweights like Llama-3.1 and Qwen-2.5 across math, clinical, and instruction-following benchmarks.
| Method | MATH500 | MedXpertQA | AlpacaEval | | :--- | :--- | :--- | :--- | | Base Model (Llama-3.1-8B) | 32.0 | 13.0 | 17.3 | | GenARM (SOTA TTA) | 49.2 | 11.2 | 10.8 | | TARo (Ours) | 54.4 | 13.2 | 20.8 |
Weak-to-Strong Generalization
One of the most profound findings is that the router and reward model—trained on 8B architectures—can effectively guide 70B parameter models without any fine-tuning. This proves that the "logic" of logit-mixing is scale-agnostic.
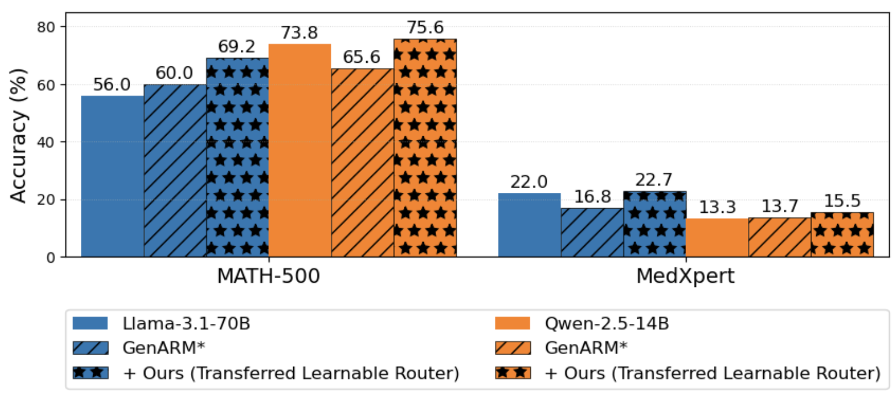 Figure 3: TARo successfully boosts the performance of 70B models using 8B-trained components.
Figure 3: TARo successfully boosts the performance of 70B models using 8B-trained components.
Critical Analysis & Future Work
While TARo is a massive leap for test-time alignment, it isn't a silver bullet:
- Overhead: Using "Full-logits" can significantly drop throughput (TPS) due to the large memory footprint of vocabulary-wide concatenation.
- Strategy Correction: Qualitative analysis shows TARo sometimes follows an incorrect logical path perfectly but lacks a "backtracking" mechanism to self-correct a fundamental strategy error.
Conclusion: TARo demonstrates that the next frontier of LLM alignment isn't just better weights, but smarter inference. By treating alignment as a dynamic routing problem, we can unlock deep reasoning in frozen models with minimal compute.