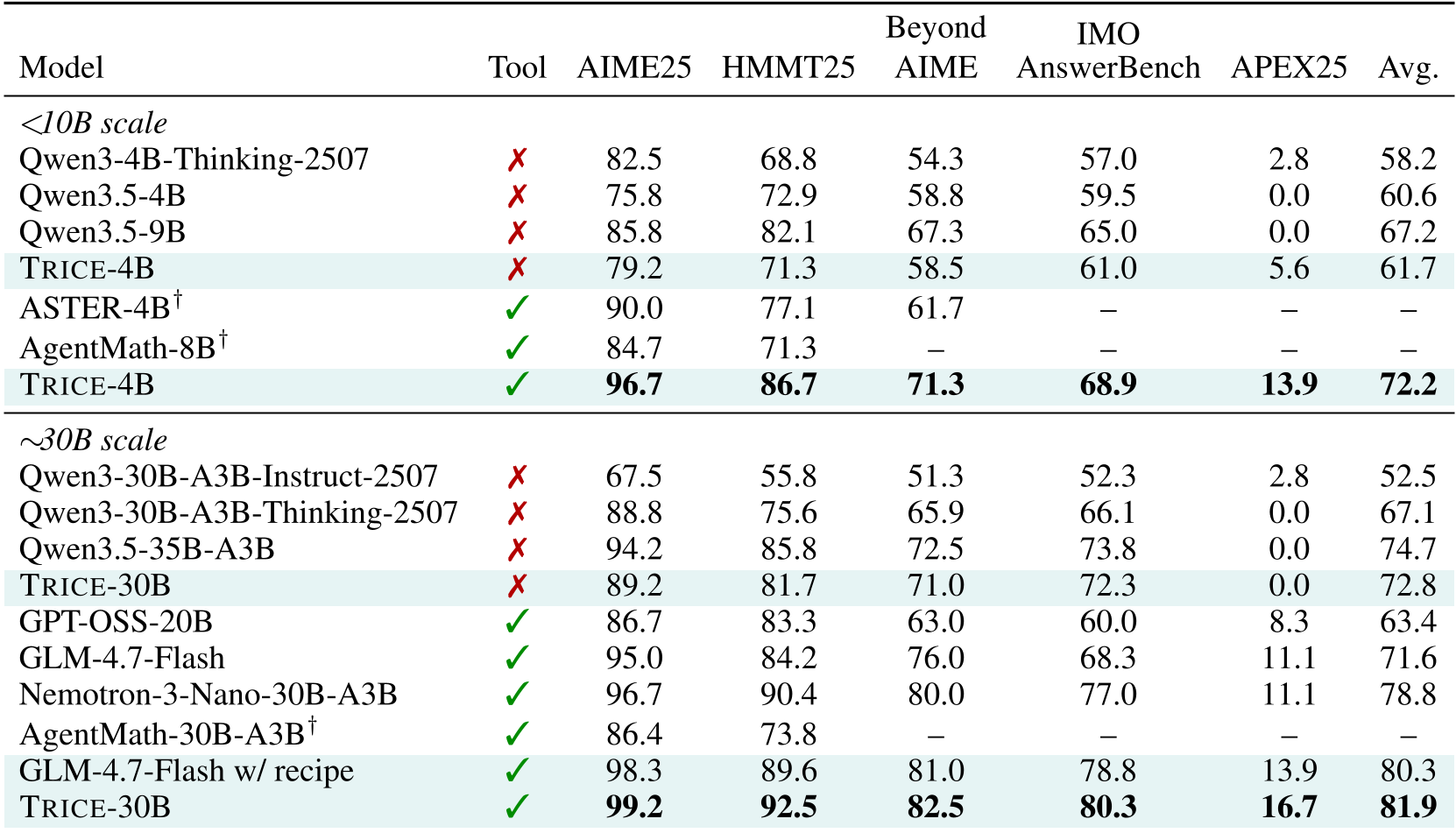
本文提出了 TRICE,一种针对强思维模型(Thinking Models)的全流程工具集成推理(Tool-Integrated Reasoning, TIR)训练方案。通过在 SFT 和 RL 阶段引入精心设计的轨迹数据与稳定性策略,TRICE-30B 在 AIME 2025 基准测试中达到了 SOTA 的 99.2% 准确率。
TL;DR
在学术界追求 Long-CoT(长思维链)提升逻辑极限的同时,来自上海 AI Lab、浙大及清华的研究团队提出了 TRICE 方案。他们发现即使是最强的思维模型,在面对复杂数学竞赛题时也会因“盲目自信”而拒绝使用计算工具。TRICE 通过一套从数据工程到强化学习的全流程配方,让模型学会在推理中无缝交织代码执行。其最终版模型在 AIME 2025 上斩获 99.2% 的恐怖高分,刷新了开源模型的 SOTA 纪录。
1. 痛点:思维模型的“工具僵局”
当前的思维模型虽然在纯文本逻辑上表现强劲,但在面对需要精确数值计算或系统性遍历的情景时,依然显得力不从心。
- 现象一:Delayed-code Pattern。模型往往在洋洋洒洒推理几万字后,最后一步才调用工具验证答案,这种“马后炮”行为无法利用工具修正中间过程的错误。
- 现象二:性能崩塌。一旦在 Prompt 中加入工具权限,思维模型的原生逻辑链往往会被干扰,导致准确率反而下降。
2. 核心配方:从数据驱动到阶段协调
作者认为,教模型使用工具不是简单的微调,而是一场精密的外科手术。
A. 数据工程:学其“形”更要学其“神”
- 教师模型选择:作者对比了 GPT-OSS 和 MiniMax,发现学生模型更容易学习“高频、轻量级”的调用风格(如 GPT-OSS)。这种风格将复杂计算拆解为简单步骤,通过 Stateful Sandbox(有状态沙箱)复用变量,更符合人类边算边想的过程。
- 工具优势筛选 (Tool-advantaged Problems):并非所有问题都适合调包。作者只保留那些“有了工具后准确率大幅提升”的问题作为训练集,引导模型识别工具的真正价值。
- 混合训练:为了防止模型在没法上网/调包时变“白痴”,训练集中强制保留了比例可观的纯文本推理轨迹。
B. SFT 动力学解析:避开“伪拟合”陷阱
作者揭示了 TIR 训练的三个阶段:
- Form (形式阶段):模型拼命调用工具,但逻辑混乱,长度暴涨,准确率反而跌。
- Substance (本质阶段):模型开始领悟工具与逻辑的交替。
- Noise (噪声阶段):过度拟合教师的冗余信息,RL 潜力降低。
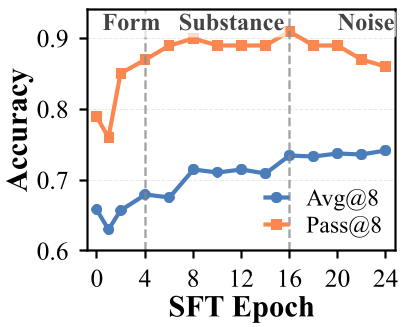 通过监控 pass@k 和响应长度,作者精确定位了第 2 阶段的实验点作为 RL 的初始 Checkpoint。
通过监控 pass@k 和响应长度,作者精确定位了第 2 阶段的实验点作为 RL 的初始 Checkpoint。
3. 强化学习:全上策略(On-policy)的救赎
在 RL 阶段,由于工具返回的 Observation(如报错信息、绘图数据)具有高度的不确定性和“离策略”属性,传统的 RL 非常容易训练崩塌(Collapse)。 TRICE 采用了:
- Outcome-based Reward:不给工具调用本身发奖励(防止奖励黑客行为),只根据最终答案对错给分。
- On-policy Rollout:抛弃分批次更新,采用完全的上策略训练,极大地提升了稳定性。
4. 实验战果:降维打击
TRICE-30B 在多个硬核数学榜单上展现了统治力:
- 性能飞跃:在 APEX 2025(国际奥数难度)上,相比基座模型实现了从 0 到 16.7% 的突破。
- 更短、更强:由于工具压缩了复杂的算术推导,TRICE 的响应长度比纯文本模型更短,显著节省了推理开销。
5. 深度洞察:工具到底解锁了什么?
作者通过 Gemini 对解决路径进行了分类,发现代码执行器在模型手中已经变成了:
- 经验发现:先算几个小案例,推导通用公式。
- 算法搜索:直接暴力搜索组合空间。
- 计算卸载:保证高精度。 这证明了 TIR 并非简单的“外挂计算器”,而是模型认知能力的物理延伸。
总结与局限
TRICE 成功证明了:思维深度(Long-CoT)+ 工具宽度(TIR)= 未来推理模型的新标准。 目前的局限在于该方案高度依赖数学这一可验证领域。未来如何将这套配方迁移到软件工程、科学探索等开放领域,将是 Agent 技术演进的关键路径。