TETO (Tracking Events with Teacher Observation) is a novel teacher-student framework for event-based motion estimation that achieves SOTA point tracking on EVIMO2 and optical flow on DSEC. By distilling knowledge from a pretrained RGB tracker using only 25 minutes of unannotated real-world data, it eliminates the need for massive synthetic datasets and addresses the sim-to-real gap.
TL;DR
TETO (Tracking Events with Teacher Observation) marks a paradigm shift in event-based vision. Instead of training on hours of "glitchy" synthetic data, it learns complex motion estimation from a mere 25 minutes of real-world footage. By distilling intelligence from a pretrained RGB teacher, TETO achieves SOTA performance in point tracking and optical flow, subsequently powering high-fidelity video frame interpolation (VFI) in extreme conditions.
The "Sim-to-Real" Wall in Event Cameras
Event cameras are the "speed demons" of computer vision, capturing brightness changes at microsecond resolution. However, the field has been stuck in a Synthetic Data Trap. Models like ETAP and MATE rely on thousands of hours of rendered data (EventKubric).
The problem? Synthetic events are often "too clean" or exhibit periodic artifacts from discrete RGB interpolation. This leads to a massive sim-to-real gap when these models encounter the messy, non-linear dynamics of the real world.
Methodology: Distilling the Wisdom of RGB
The core philosophy of TETO is simple: Why simulate the world when we can watch it?
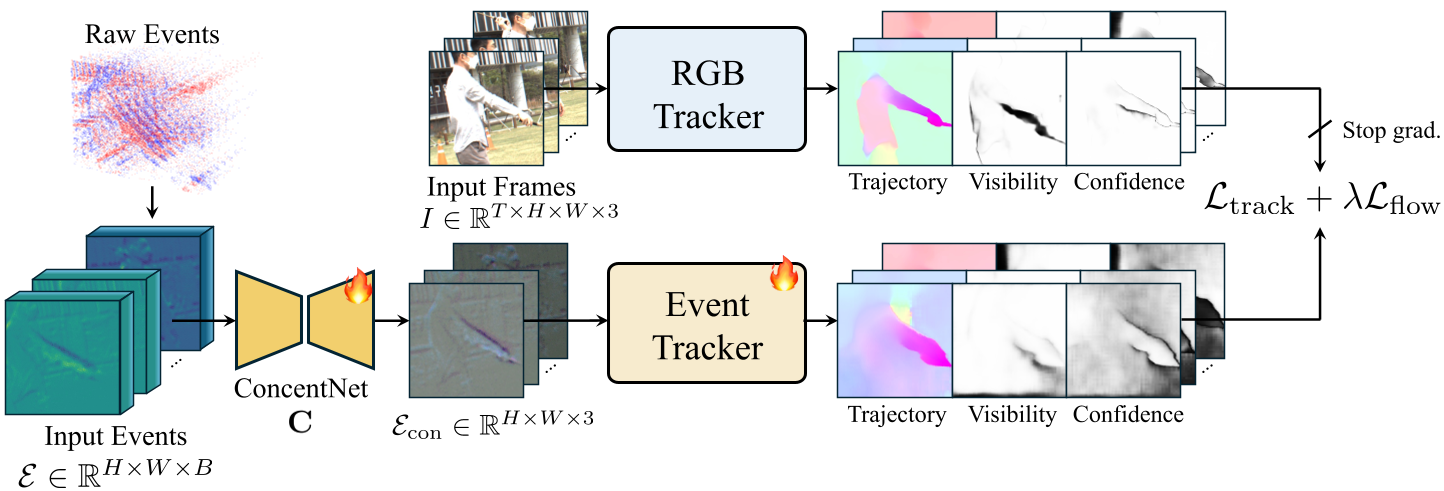
1. The Teacher-Student Framework
The authors use a pretrained RGB tracker (AllTracker) as a "Teacher." Since RGB frames are available during training, the teacher generates pseudo-trajectories and optical flow labels. The "Student" (the event-based model) attempts to replicate these labels using only event data.
2. Concentration Network
To feed sparse, multi-scale event stacks into a standard RGB-designed backbone (ConvNeXt), TETO introduces a Concentration Network. This lightweight U-Net compresses temporal bins into a 3-channel representation, preserving pretrained weights and architectural integrity.
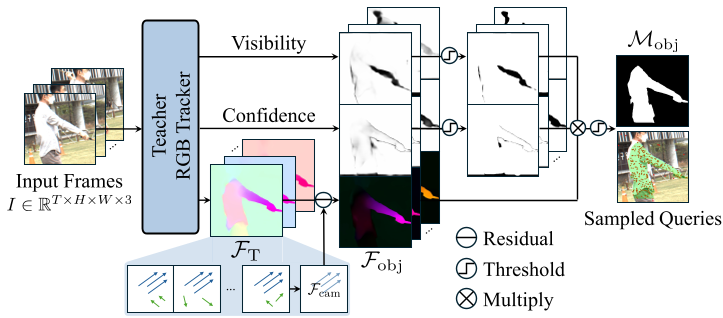
3. Motion-Aware Data Curation
A major challenge in real-world data is Ego-motion dominance. If the camera is moving, every pixel generates events, drowning out the motion of small objects. TETO uses RANSAC to fit a global affine model, identifies residual flow (the objects), and oversamples query points from these dynamic regions to ensure the model learns "real" object tracking.
Results: SOTA with Minimal Data
TETO doesn't just match synthetic-trained models; it beats them.
- Point Tracking: On EVIMO2, TETO hits a SOTA AJ of 67.9, surpassing ETAP which utilized 10x more training data.
- Optical Flow: On the DSEC benchmark, TETO's zero-shot performance (2.15 EPE) already beats previous unsupervised methods trained specifically on that domain.
- Video Frame Interpolation: By feeding TETO's motion priors into a Video Diffusion Transformer (Wan2.1), the system generates sharp, ghosting-free frames even at 6x interpolation rates.

Seeing Beyond Appearance
One of the most striking findings is that TETO outperforms its own teacher in extreme conditions. Because the student learns the temporal logic of events rather than just imitating RGB pixels, it can track objects in total darkness or through water droplets where the RGB teacher is completely blinded.

Critical Analysis & Conclusion
TETO proves that data quality > data quantity. By focusing on motion-aware curation of real-world event statistics, it bypasses the need for complex simulation pipelines.
Limitations:
- Fluid Motion: Like most trackers, it struggles with spatially incoherent changes (splashes, flames).
- Shadows: It may occasionally track moving shadows as if they were solid objects—a classic event camera pitfall.
Takeaway: TETO provides a robust template for the next generation of event-based vision, showing that even with limited unannotated data, we can achieve superhuman tracking by effectively bridging the gap between RGB "appearance" and event "dynamics."