TouchAnything is a novel 3D reconstruction framework that recovers full object geometry from sparse tactile touches using a pretrained 2D vision diffusion model (Stable Diffusion) as a geometric and semantic prior. It processes tactile data from GelSight-style sensors into virtual camera observations and achieves open-world reconstruction of unseen objects.
TL;DR
TouchAnything enables robots to "imagine" the full 3D shape of an object after touching it only a few times. By repurposing off-the-shelf 2D vision diffusion models (like Stable Diffusion) as a geometric backbone, the framework overcomes the sparsity of tactile data to reconstruct accurate, high-fidelity 3D models of unseen objects in open-world environments.
The Motivation: Why Vision Alone Isn't Enough
In the real world, robots often operate in "blind" conditions—reaching into backpacks, navigating dark cupboards, or handling heavily occluded objects. While tactile sensing (like GelSight) provides precise local geometry, it is inherently "short-sighted." Reconstructing a full 3D object from a few contact patches is like trying to guess a jigsaw puzzle from three pieces.
Previous researchers tried to solve this by training deep networks on specific categories (e.g., "all jars"). However, these models break the moment they encounter a unique or "out-of-distribution" object. TouchAnything flips the script: instead of training on tactile data, it leverages the vast "common sense" geometry already learned by 2D image diffusion models trained on billions of internet photos.
Methodology: From Local Touches to Global Priors
The system operates in three distinct phases to bridge the gap between physical touch and generative imagination.
1. Tactile-to-Virtual Vision
The robot uses a GelSight sensor to capture local deformations. These "tactile images" are processed via a Multi-Head U-Net to extract local depth maps and surface normals. To make this data compatible with 3D computer vision pipelines, the authors treat each touch as a virtual camera positioned just behind the contact point.
2. Stage 1: Coarse Geometric Optimization
Using a neural implicit representation (SDF with multi-resolution hash-encoding), the model establishes the basic topology. It balances two forces:
- Tactile Consistency: Ensuring the surface passes through the actual contact points measured by the robot.
- SDS Guidance: Using Score Distillation Sampling from Stable Diffusion to ensure the overall shape matches a text prompt (e.g., "a camera").
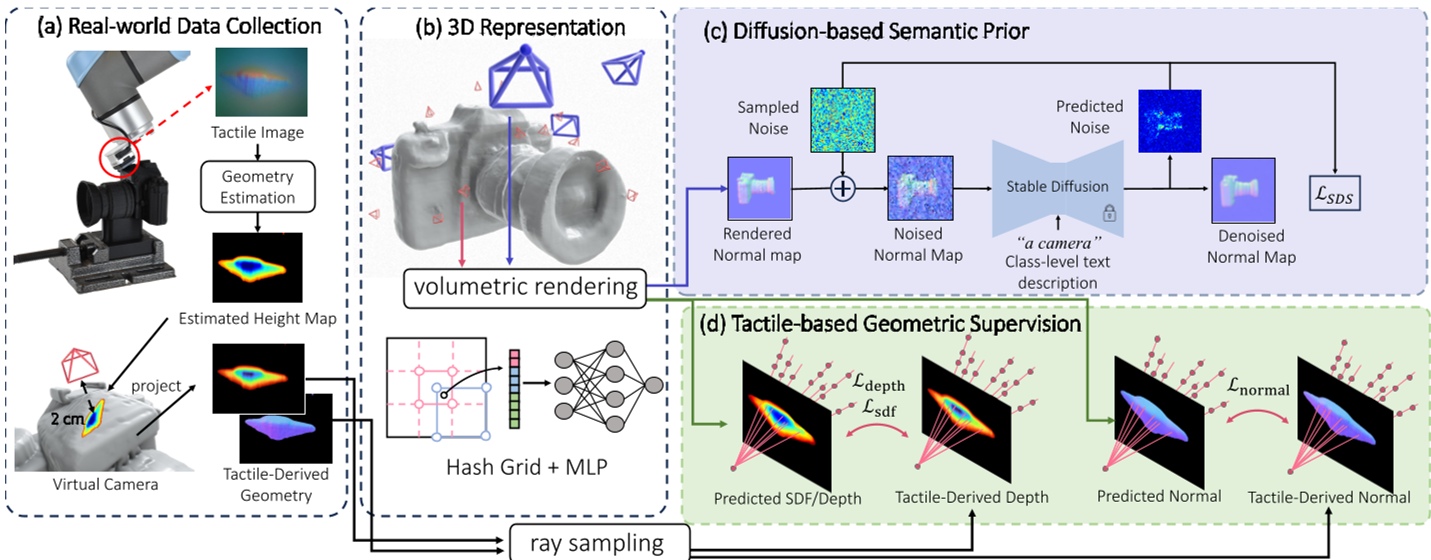
3. Stage 2: Fine-Grained Refinement
A neural MLP is too slow for high-resolution rendering. To capture fine details—like the ridges of a bottle or the buttons on a camera—the framework switches to DMTet, an explicit tetrahedral-grid representation. This allows for 512x512 rendering, enabling the diffusion model to inject high-frequency geometric textures into the mesh.
Key Results & Experimental Evidence
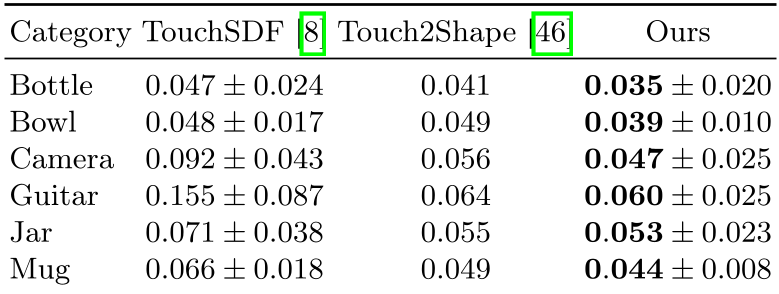
Outperforming Category-Specific Baselines
In simulations across ShapeNet categories, TouchAnything significantly reduced reconstruction errors compared to TouchSDF and Touch2Shape. Because it isn't tethered to a specific training set, it handles complex geometries (like Gutar necks or Camera lenses) far better than prior works.
| Category | TouchSDF (Error) | TouchAnything (Ours) | | :--- | :--- | :--- | | Camera | 0.092 | 0.047 | | Guitar | 0.155 | 0.060 |
Real-World "Open-World" Capability
The most impressive feat is the robot's ability to reconstruct objects it has never seen before—such as a power drill or a tomato soup can. The diffusion prior correctly "hallucinates" the back of a drill even if the robot only touched the handle, provided the semantic prompt is accurate.

Critical Analysis & Insights
Why does this work? The core insight is that 2D diffusion models are secret 3D masters. They have seen so many photos from different angles that they understand the underlying structure of the world. By using "Normal Maps" as the interface between the 3D representation and the 2D diffusion model, the authors effectively filter out "noise" and focus the AI on pure geometry.
Limitations:
- Prompt Dependency: As shown in ablation studies, if you tell the robot it is touching an "airplane" when it is actually a "bottle," the model will try to grow wings on the bottle.
- Passive Collection: Current sensing is passive; the robot doesn't yet "choose" where to touch to gain the most information.
Conclusion
TouchAnything represents a significant step toward robots that can operate in the dark or in messy environments. By treating "Touch" as just another way to condition a powerful generative prior, it moves us closer to a future where robots have human-like spatial intuition.
Takeaway: The future of robotics isn't just better sensors—it's better "imagination" powered by large-scale pre-trained models.