本文提出了 Trace2Skill,一个通过整体分析大规模执行轨迹(Traces)来自动提取和演化智能体技能(Skills)的框架。该方法模仿人类专家的技能编写方式,通过并行分析成功和失败示例,将零散的经验感悟(Lessons)归纳、合并为一套逻辑严密、无冲突且可迁移的声明式技能目录,在 SpreadsheetBench 等任务上显著超越了 Anthropic 官方及人工编写的基线。
TL;DR
传统的 Agent 学习往往是“头痛医头”,看到一个错误改一行代码。阿里巴巴 Qwen 团队联合苏黎世联邦理工大学等机构提出的 Trace2Skill 彻底改变了这一模式。它通过并行回溯成百上千条执行结果,利用归纳推理将零散的教训浓缩成逻辑严密的“技能书”(SKILL.md)。结果令人惊叹:哪怕是用 35B 的小模型演化出的技能,带到 122B 的大模型身上,也能让其在 OOD 任务上性能飙升近 60%。
痛点深挖:Agent 为什么总是“学不会”?
目前赋予 Agent 领域技能主要靠人工编写(吞吐量低)或在线顺序更新(Sequential Updating)。后者存在两个致命伤:
- 碎片化陷阱:每遇到一个新情况就加一个 Skill,导致技能库迅速膨胀,最后检索器(Retriever)都找不准该用哪一个。
- 近视效应:在线学习通常只关注当下的轨迹,缺乏全局视野,容易把“偶然的成功”当成“必然的规律”,或者因为处理顺序不同导致技能产生逻辑冲突。
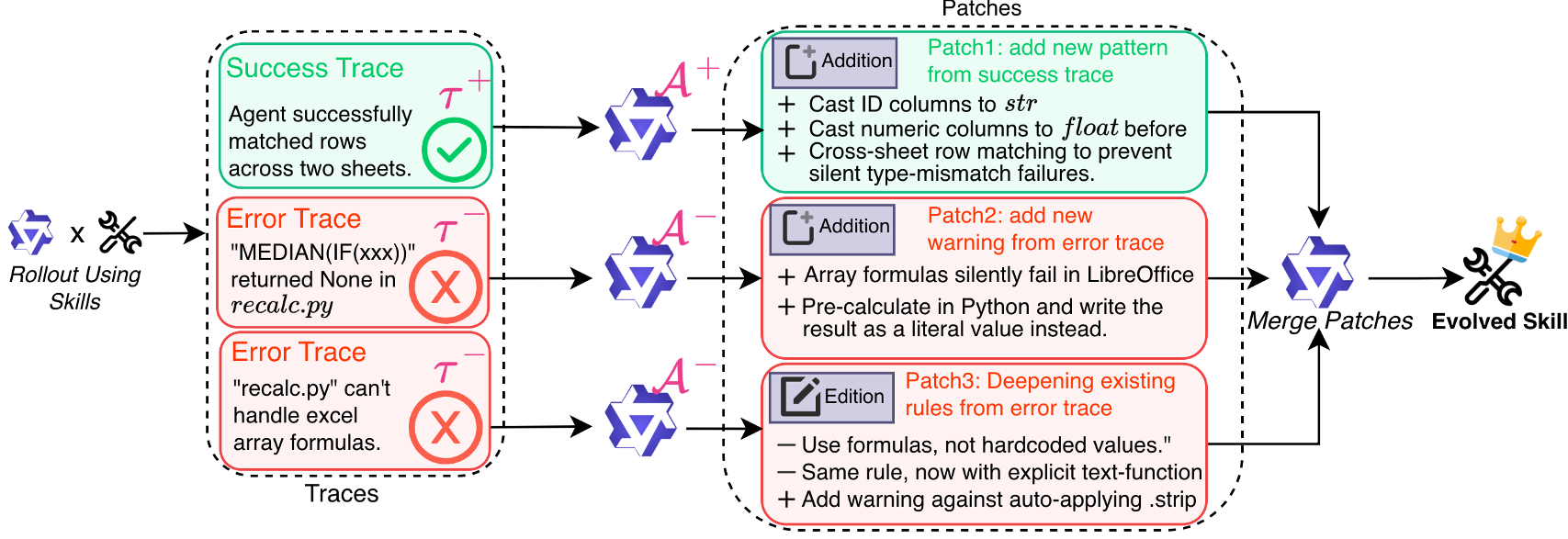
核心机制:Trace2Skill 的“三步走”战略
Trace2Skill 模仿了人类专家总结经验的过程:不是看一眼改一笔,而是看完一堆案例后再提笔定稿。
1. 轨迹生产(Trajectory Generation)
在并行环境下运行大量任务,收集原始的执行日志(Traces),并打上成功或失败的标签。
2. 多角色异步分析(Multi-Agent Patching)
- 错误分析员 (A-):最核心的创新。它不仅看日志,还会利用 ReAct 循环复现错误,通过修改代码验证猜想,直到找到导致失败的根因。
- 成功分析员 (A+):总结高效的操作范式,确保成功的经验也被固化。
3. 分层归纳合并(Conflict-Free Consolidation)
这是该工作的灵魂。框架将成百上千个“补丁”进行类似二叉树的分层合并:
- 少数服从多数:如果多个补丁都提到了“写 Excel 必须运行 recalc.py”,该模式会被提升为核心 SOP。
- 冲突消除:程序化检测对同一行代码的修改冲突,确保最终输出的 SKILL.md 文档语法严谨且逻辑闭合。
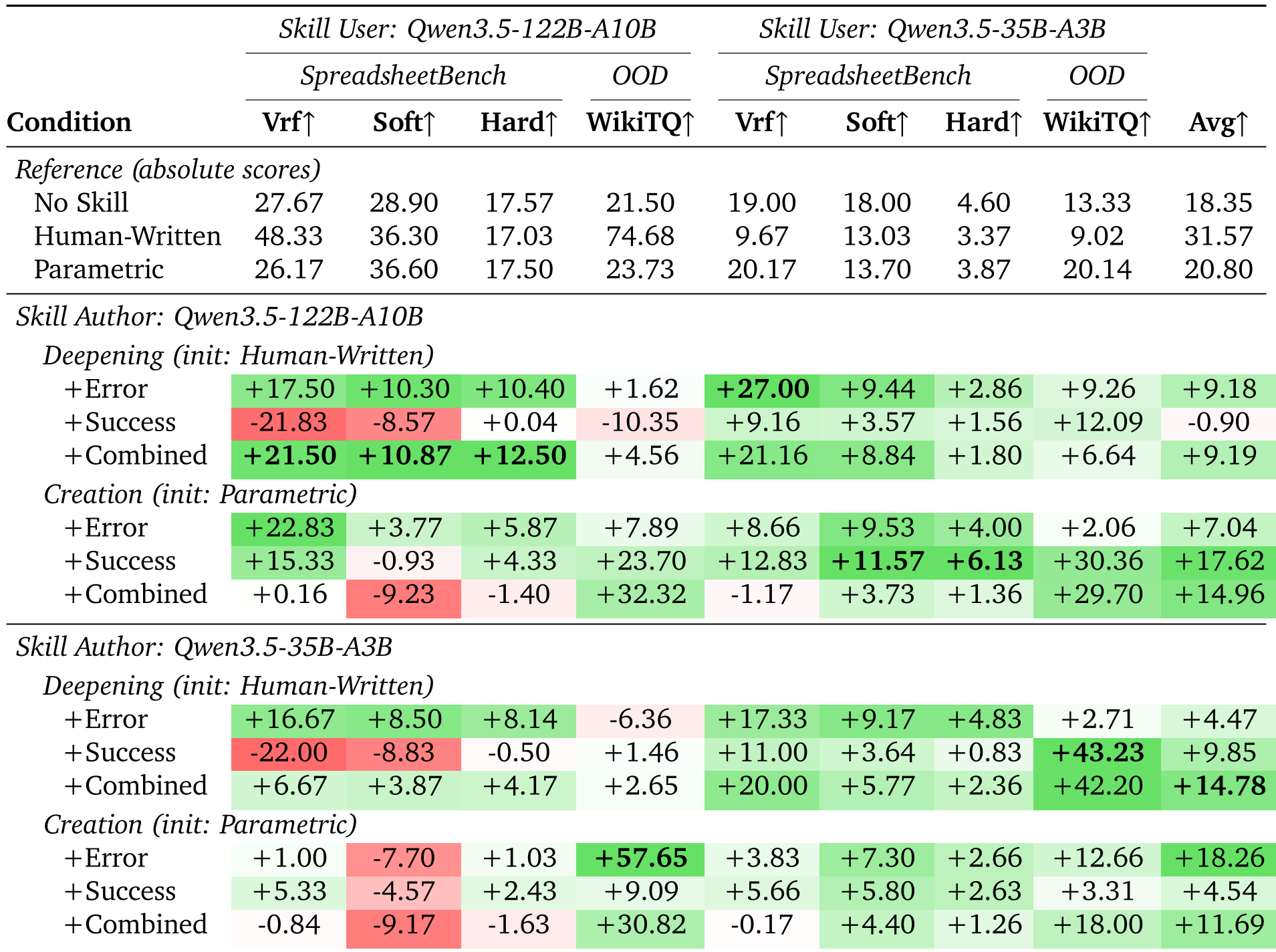
实验战绩:跨越尺度的迁移奇迹
论文最令人惊讶的发现是技能的超强迁移性:
- 以小博大:由 35B 模型生成的技能,被 122B 模型挂载后,在 WikiTQ 任务上取得了 81.38% 的高分,远超人工编写的 74.68%。
- 突破领域限制:虽然技能是在电子表格(Spreadsheet)任务上训练的,但在处理维基百科表格问答(OOD)时依然表现强劲。
深度洞察:为什么这种方法更有效?
- 显式推理 vs 隐式参数:通过文本化的技能,我们把“模型不知道自己不知道”的东西变成了“模型看得见的操作手册”。
- 拒绝检索依赖:相比于现有的 ReasoningBank 等检索式方法,Trace2Skill 将知识内化到一份精简的 Markdown 中,避免了检索偏差带来的干扰。
- 具身化错误分析:A- 分析员通过尝试修复(Fix-and-Verify)确保了教训的真实性,而非大模型的“幻觉”总结。
总结与局限
Trace2Skill 证明了:Agent 并不一定需要更强大的参数量来掌握领域知识,一套高质量的、基于实战经验演化而来的 Declarative Skills 才是通往 AGI 的轻捷径。当然,目前该方法对于每个补丁的因果贡献度量化还有待加强。
** takeaway:未来的智能体竞争,可能不再是参数规模的竞争,而是“技能演化算法”与“高质量 SOP 库”的竞争。**