本文提出了 PolyStep,一种无需梯度的脉冲神经网络及非微分模型优化器。该方法通过在压缩子空间内利用多胞体(Polytope)顶点进行正向采样,并结合熵正则化最优传输(Optimal Transport)或 Softmax 进行参数更新,在完全不依赖 Backpropagation 的情况下实现了非微分架构的高效训练。
TL;DR
在 AI 领域,Backpropagation(反向传播)如同空气般无处不在,但它有一个致命的阿基里斯之踵:要求所有组件必须可微。近日,来自图宾根大学等机构的研究者提出了 PolyStep,一种革命性的无梯度优化器。它放弃了寻找梯度的尝试,转而利用最优传输 (Optimal Transport, OT) 理论在多胞体几何结构上进行采样更新。PolyStep 不仅在脉冲神经网络 (SNN) 和硬量化网络上超越了所有无梯度基线,更在 100 万变量的离散组合优化任务中展现了惊人的扩展性。
1. 痛点:被梯度困住的“黑盒”
现代神经网络越来越渴望引入不连续、离散的组件:
- 脉冲神经元 (Spiking Neurons):模拟生物大脑,极致节能,但其硬阈值函数导数为零或无穷。
- 硬量化 (Quantization):如 int8 或二值化网络,取整操作会切断梯度流。
- 组合路由 (Discrete Routing):如 MoE 架构中的专家选择。
传统的做法是使用 Surrogate Gradients(代理梯度) 或 STE(直通估计器),但这本质上是“指鹿为马”——用平滑函数强行模拟跳变函数。这不仅引入了偏差,还需要复杂的超参数调优。如果模型是一个真正的“黑盒”(比如不可导的物理模拟器),Backpropagation 将彻底停摆。
2. 核心直觉:从“导数”转向“几何”
PolyStep 的核心思想是不再纠结于单点的梯度,而是在参数空间进行结构化探索。
2.1 粒子化与子空间投影
为了处理数以百万计的参数,PolyStep 首先将参数 划分为多个粒子,并在每一层使用随机子空间投影(HybridSubspace)。这种做法极大地降低了搜索维度的诅咒。
2.2 多胞体探测 (Polytope Probing)
在每个迭代步骤中,PolyStep 在当前参数点周围构建一个旋转的正轴体(Orthoplex)。想象你在山顶,向前后左右、上下八方各派出一名观察员(Probe Points),反馈周围的地形高度(Loss 值)。
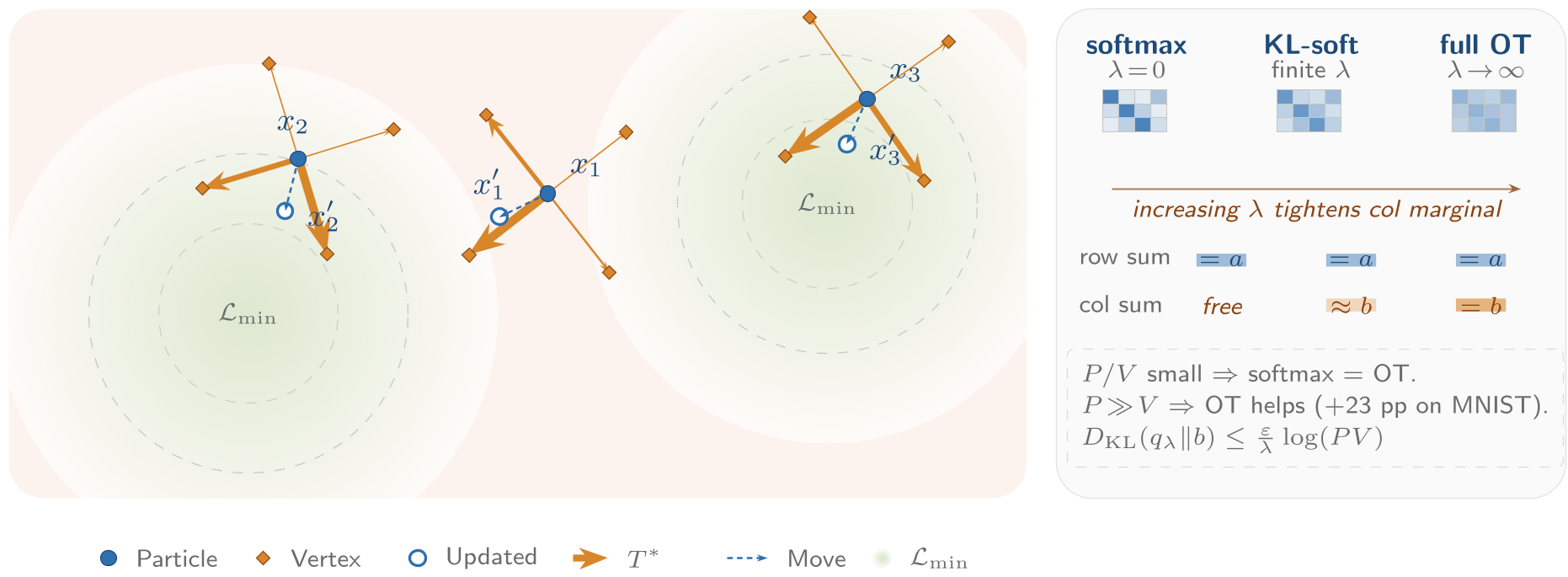 图 1:PolyStep 的前向优化流程。从参数压缩、多胞体采样到最优传输解算及重心投影。
图 1:PolyStep 的前向优化流程。从参数压缩、多胞体采样到最优传输解算及重心投影。
2.3 最优传输作为“指挥官”
获得各顶点的损失值后,如何决定下一步往哪走?PolyStep 将其建模为一个正则化最优传输问题:
- 将“质量”(更新步长)分配到低成本的顶点上。
- 引入熵正则化项 控制探索的弥散程度。
- 在子空间受限时,该机制等价于一种自适应的 Softmax 加权,使参数向多个低损失方向的聚合重心平滑移动。
3. 实验战绩:非微分领域的“推土机”
3.1 脉冲神经网络 (SNN)
在 hard-LIF 神经元的 MNIST 训练中,当 CMA-ES 和 OpenAI-ES 等传统无梯度方法准确率在 16%-33% 之间徘徊时,PolyStep 一举冲到了 93.4%,几乎逼近了有梯度代理的上限(97.8%)。
3.2 组合优化与强化学习
在 100 万变量的 MAX-SAT 任务上,PolyStep 维持了 92.6% 的子句满足率,而进化的 ES 方法在面对如此高维的离散景观时,表现迅速退化至接近随机。 在 RL 任务中,当部署了 Binary 或 INT8 量化策略导致 PPO/DQN 彻底崩溃时,PolyStep 依然能稳定地解决 CartPole 和 Acrobot 环境。
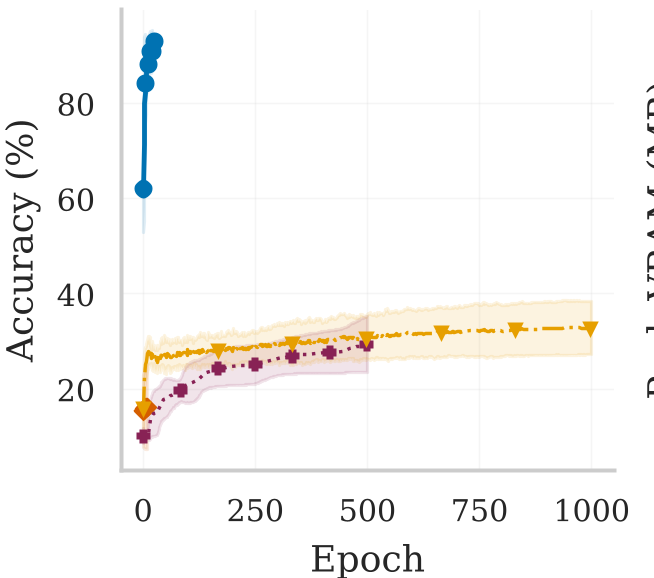 图 2:在长序列 SNN 评估中,PolyStep 的峰值内存展现出亚线性的增长趋势,在 T=400 时比 BPTT 降低了约 30 倍。
图 2:在长序列 SNN 评估中,PolyStep 的峰值内存展现出亚线性的增长趋势,在 T=400 时比 BPTT 降低了约 30 倍。
4. 为什么 PolyStep 有效?
- 分段流畅性 (Piecewise-smoothness):论文通过严谨的数学证明显示,即便在不连续的景观中,只要通过旋转和半径抖动进行采样,PolyStep 的重心步长在期望意义上等价于某种平滑过后的“守恒梯度”。
- 前向原生性:由于只需要 Forward Pass,PolyStep 完美避开了存储激活值(Activation Checkpointing)的压力。
- 鲁棒的几何架构:最优传输的 Marginal Constraints 保证了搜索方向的多样性,防止了粒子在复杂地形中过快陷入局部最优。
5. 局限性与展望
尽管 PolyStep 在非微分领域战功卓著,但在传统的平滑任务(如标准 CNN 或大语言模型从零训练)上,其效率依然无法与 Adam 这种利用了精确一阶信息的优化器相比。每一步迭代需要数百万次前向评估,这在当前算力环境下是一笔不小的开销。
总结 (Takeaway): PolyStep 开辟了一条连接“连续解析优化”与“离散黑盒优化”的新路径。随着 AI 硬件向更高效的推理芯片、神经形态形态演进,这种原生支持不可微组件、极度节省内存、仅需前向传播的优化框架,或许会成为下一代边缘智能体训练的关键。
作者注:本文基于 arXiv 论文 "Training Non-Differentiable Networks via Optimal Transport" 进行深度解读,代码已在 GitHub 开源。