The paper introduces a novel Transformer architecture modification and a two-stage training pipeline (Self-Distillation SFT and RL) designed to incentivize "externalized reasoning." By adding stochastic early-exit heads, the model learns to truncate forward passes for easy tokens, effectively forcing complex cognitive work into visible Chain-of-Thought (CoT) tokens rather than hidden internal activations.
TL;DR
Current LLMs are too good at "thinking under their breath." Researchers have proposed a structural modification to the Transformer that forces models to stop computing as soon as a token is "easy" to predict. By using a two-stage pipeline of Self-Distillation and Reinforcement Learning, they've created a model that actively tries to save compute, theoretically pushing its complex reasoning out of its hidden states and into the visible Chain-of-Thought (CoT).
The Motivation: The Danger of "Non-Myopic" Planning
In the world of AI Safety, we rely on Chain-of-Thought (CoT) to monitor what a model is thinking. However, Transformers are inherently non-myopic. Research shows they often "pre-cache" logic for tokens they haven't written yet.
If a model can solve a complex, potentially malicious multi-step plan entirely within its 32 or 80 hidden layers, the final output might look benign while the "crime" happened in the unreadable latent space. This paper asks: What if we take away the model's ability to think deeply in secret?
Methodology: The Architecture of Transparency
The authors modified the standard Transformer in two distinct phases:
Phase 1: Stochastic Early-Exit Heads
They added "probes" or exit heads at intermediate layers (e.g., every 5 layers). Unlike previous "Early Exit" works that focused solely on speed, this method is stochastic. At each layer, the model samples a decision: Should I exit now or keep going?
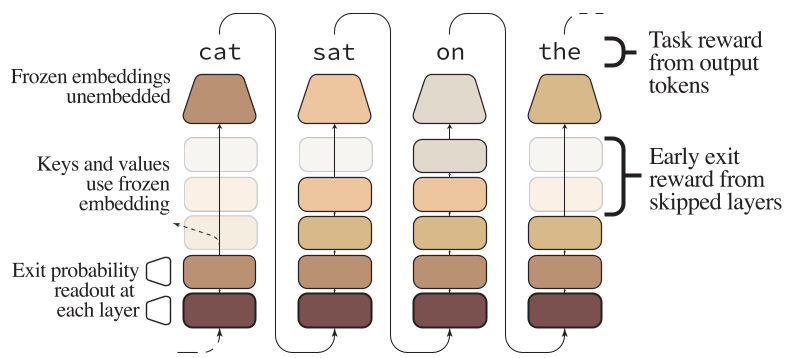 Figure 1: (A) Calibration via self-distillation. (B) RL incentivization using the RLOO algorithm.
Figure 1: (A) Calibration via self-distillation. (B) RL incentivization using the RLOO algorithm.
Phase 2: Training to be "Lazy"
The training is the secret sauce.
- Calibration (SFT): The model learns when it's safe to exit. If the current layer's prediction (the "Logit Lens") is already very close to what the final layer would say, the exit head is trained to favor stopping.
- Incentivization (RL): Using a modified RLOO (REINFORCE Leave-One-Out), the authors add a penalty for "Average Exit Layer."
The reward function essentially says: "I will reward you for the right answer, but I will reward you MORE if you give me that answer using only the first 10 layers instead of all 30."
Experimental Evidence: Success at the 4B Scale
The researchers tested this on Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B.
1. Computational Efficiency vs. Accuracy
Crucially, they found that accuracy actually improved during the RL phase. As the model learned to optimize its exit strategy, it became more robust at the task (Theory of Mind/GSM8K).
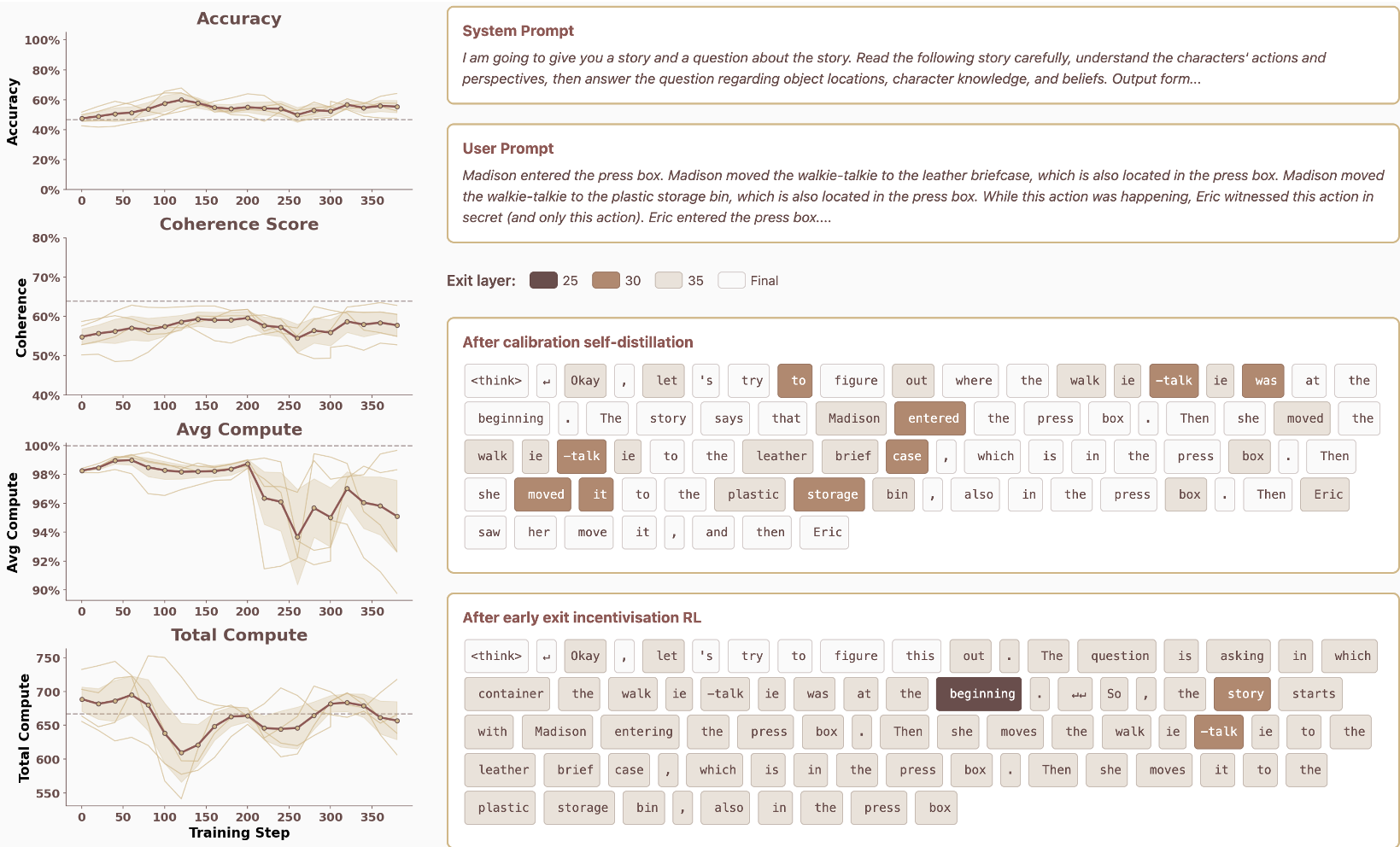 Figure 2: RL training dynamics. As steps increase, Accuracy (top left) goes up while Average Compute (bottom left) goes down.
Figure 2: RL training dynamics. As steps increase, Accuracy (top left) goes up while Average Compute (bottom left) goes down.
2. Token-Level Adaptivity
The model didn't just learn to exit early everywhere. It learned to be adaptive. For "easy" tokens (like parts of common words), it exits almost immediately. For "hard" tokens that require actual logic, it utilizes the full depth of the network.
Critical Analysis: A Double-Edged Sword?
While this is a brilliant proof-of-concept for Mechanistic Interpretability, a few questions remain:
- The "Internal Pressure" Paradox: If we limit compute, does the model simply become more "efficient" at hiding information in the remaining layers, or does it truly move that logic to the CoT?
- Scaling: Will a 70B or 400B model find even more clever ways to obfuscate its reasoning despite the layer penalty?
Conclusion
This paper shifts the focus of LLM efficiency from "Save money/Time" to "Enforce Safety." By treating the depth of a Transformer as a scarce resource that the model must "pay" for, we might finally be able to force AI to show its work in a way that humans—and monitors—can actually trust.
Takeaway: The future of safe RLHF might not just involve rewarding "good" answers, but specifically rewarding "shallow" computation for easy steps, reserving the "deep" transformations for where they are truly needed.