This paper introduces an evolutionary game theory (EGT) and reinforcement learning (RL) framework to model AI trust as "reduced monitoring" in repeated user-developer interactions. It identifies that safe AI systems only persist as a long-run SOTA regime when institutional penalties for non-compliance exceed the costs of safety development and monitoring costs remain low for users.
Executive Summary
TL;DR: This paper redefines trust in AI from a "leap of faith" to a cost-saving monitoring strategy. By modeling the interaction between users and AI developers through Evolutionary Game Theory (EGT) and Q-learning, the authors demonstrate that safe AI development is only sustainable if monitoring remains inexpensive and regulatory penalties are sharp.
Background: Positioned at the intersection of AI Ethics and Governance, this work moves beyond static "one-shot" models. It provides a formal mathematical foundation for the common intuition that transparency is not just a moral good, but a functional necessity for market stability and safety compliance.
Problem & Motivation: The "Blind Trust" Fallacy
Most governance models assume users either "adopt" or "reject" AI. In reality, users verify outputs (monitoring) until they feel safe enough to stop. Monitoring is costly (time, expertise, or computational resources). If we ignore this cost, we fail to see the "Trust Paradox":
- If users trust blindly, developers are incentivized to cut corners (unsafe AI).
- If users monitor too much, the AI's efficiency is lost.
The authors identify a gap in literature: trust is an evolving process. They explore the feedback loop between a user's willingness to check the AI and a developer's willingness to invest in safety.
Methodology: Trust as an Adaptive Heuristic
The authors propose a repeated asymmetric game. Users have five strategies, ranging from Always Adopt (AllA) to sophisticated adaptive behaviors:
- TUA (Trust-Until-Abuse): Monitor until $N$ successes, then reduce monitoring.
- DtG (Distrust-to-Grace): Stop adopting after failure until $N$ successes are observed via occasional checks.
The Model Architecture
The interaction is modeled as a co-evolutionary system where the fitness of a developer’s "Safe" vs "Unsafe" strategy depends on the user's "Monitoring" frequency and the "Institutional Punishment" ($v$).
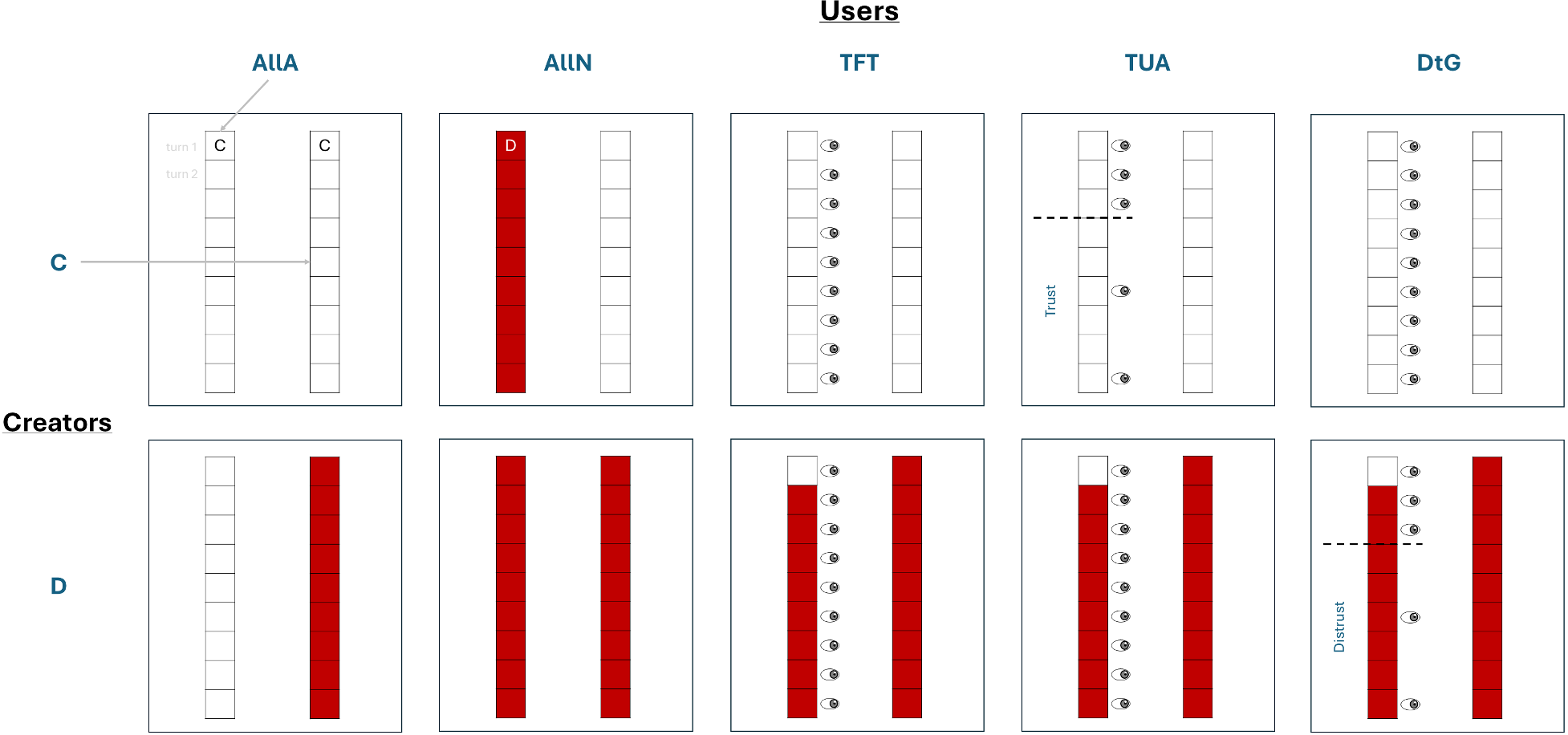 Figure 1: Comparison of TFT, TUA, and DtG strategies, showing how monitoring frequency (symbols on the right) changes based on the creator's behavior (cooperate/white vs defect/red).
Figure 1: Comparison of TFT, TUA, and DtG strategies, showing how monitoring frequency (symbols on the right) changes based on the creator's behavior (cooperate/white vs defect/red).
Calculations involve Replicator Dynamics for infinite populations and Q-learning for adaptive agents, ensuring that results aren't just artifacts of a specific mathematical framework but represent robust learning behaviors.
Experiments & Results: The Three Regimes of Governance
The study identifies three core equilibrium points in the AI ecosystem:
- Regime 1 (The Trap): No adoption and unsafe development.
- Regime 2 (The Risk): High adoption but unsafe systems (users are exploited).
- Regime 3 (The Ideal): Highly adopted, safe systems.
The Critical Role of Punishment and Monitoring Cost
The transition to the "Ideal" regime is governed by two levers:
- Monitoring Cost ($\epsilon$): When $\epsilon$ is low, users can afford to be vigilant, forcing developers into compliance. As $\epsilon$ rises, trust-based strategies fail, and the system drifts toward non-adoption or exploitation.
- Punishment ($v$): If the cost of compliance ($c$) is higher than the expected penalty ($v$), "Safe AI" becomes an evolutionary dead end.
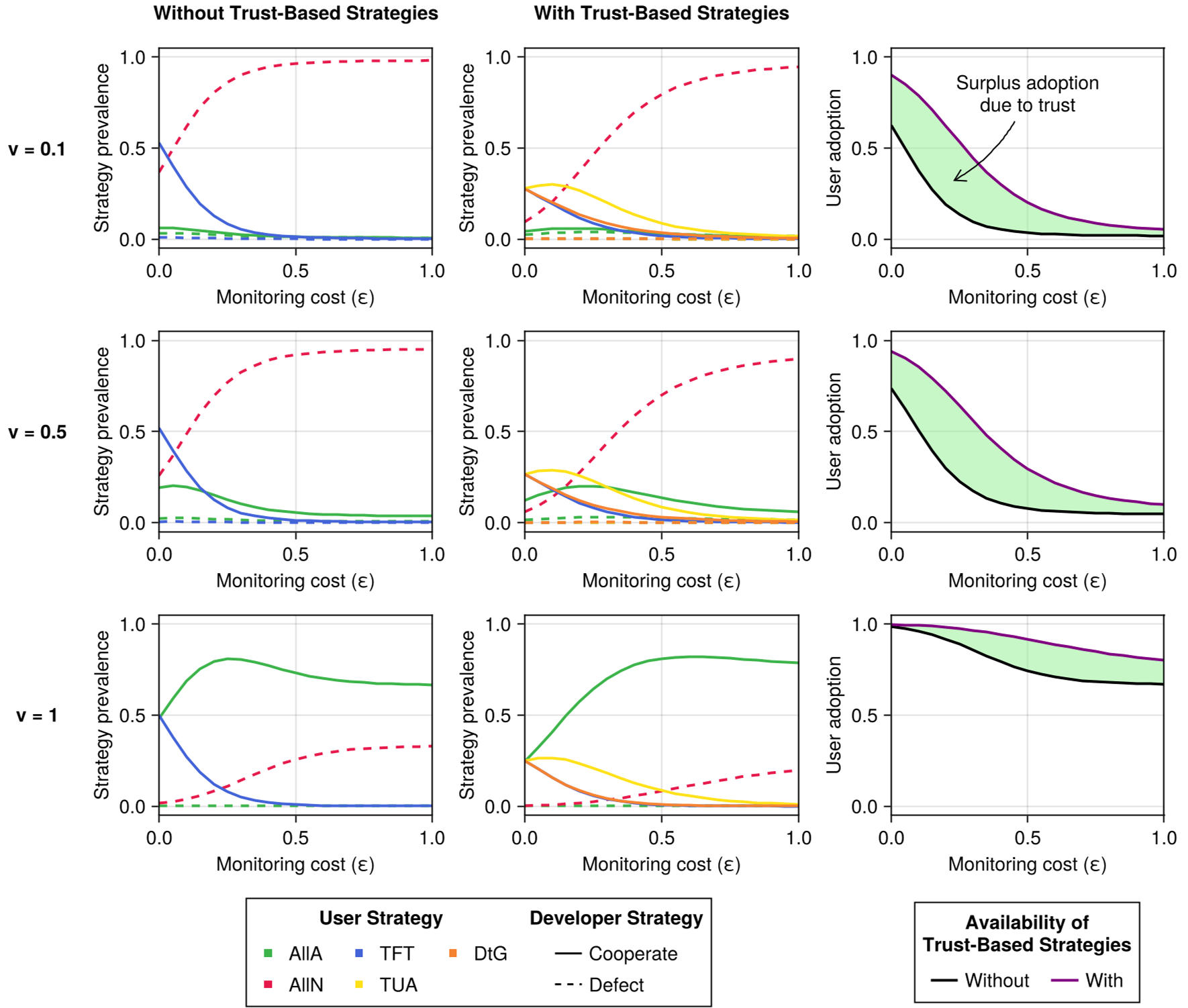 Figure 2: Stationary distributions showing that trust-based strategies (middle column) significantly stabilize user adoption compared to simple strategies (left column), especially at low monitoring costs.
Figure 2: Stationary distributions showing that trust-based strategies (middle column) significantly stabilize user adoption compared to simple strategies (left column), especially at low monitoring costs.
Q-Learning Robustness
Reinforcement learning simulations confirmed these findings. In Figure 5, we see that high monitoring costs eventually kill off trust-based strategies (TUA), leading to a "defective and All-Non-adoption society."
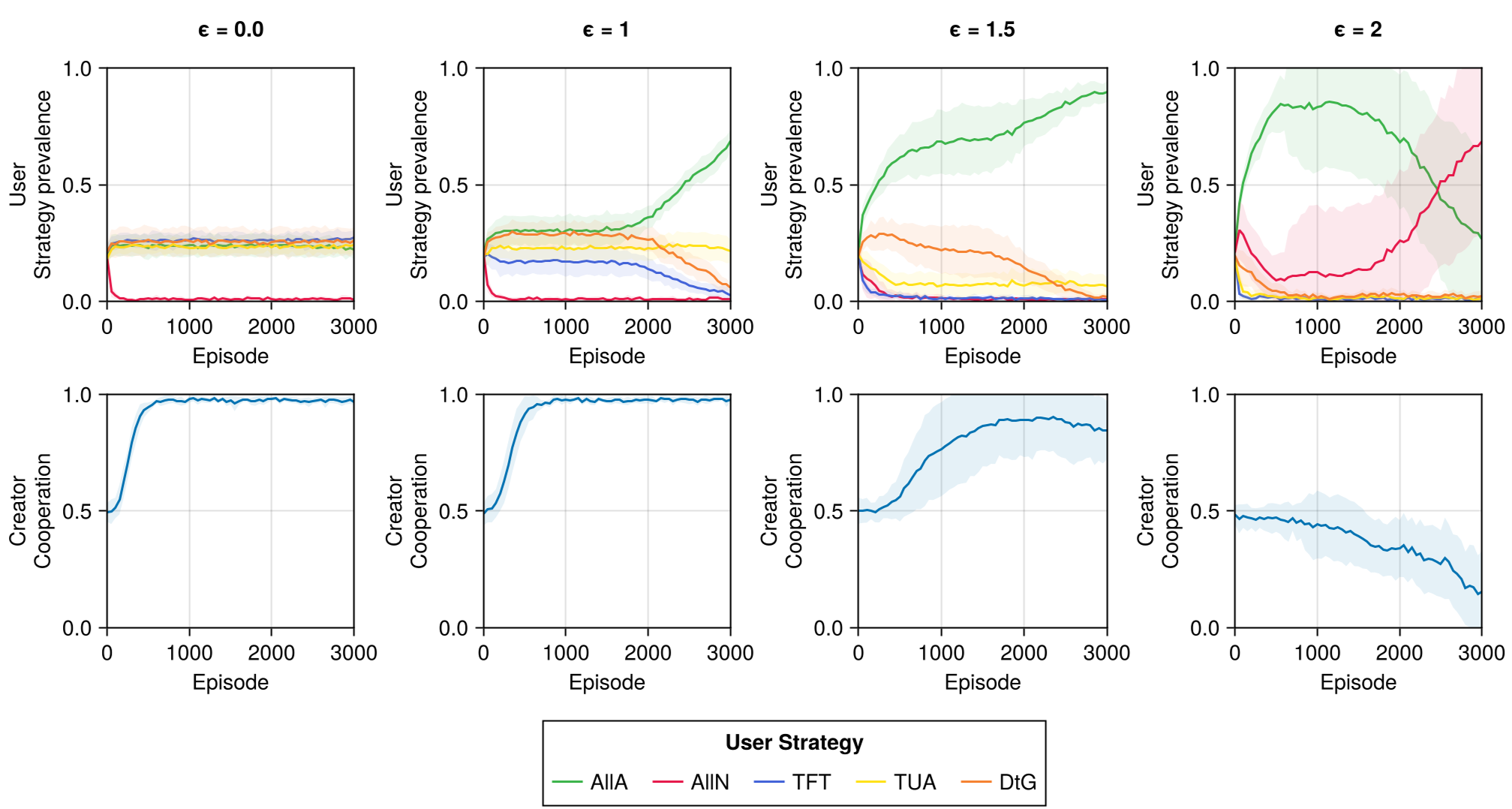 Figure 3: Q-learning agents transitioning from cooperation to a defective state as monitoring costs increase from $\epsilon=0$ to $\epsilon=2$.
Figure 3: Q-learning agents transitioning from cooperation to a defective state as monitoring costs increase from $\epsilon=0$ to $\epsilon=2$.
Critical Analysis & Conclusion
Takeaway
The paper formalizes why transparency (lowering $\epsilon$) and meaningful sanctions (increasing $v$) are the two pillars of AI governance. Without both, evolutionary pressure drives developers toward "unsafe but profitable" behavior.
Limitations
- Homogeneity: The model assumes all users and developers in a population act similarly, ignoring the diversity of "Big Tech" vs "Startups."
- Implicit Regulators: The "Regulator" is a static parameter rather than an evolving agent who might also be susceptible to lobbying or resource constraints.
Future Prospect
This research opens the door to "Regulatory Simulations," where policymakers can test the impact of specific transparency requirements (like LLM "System Cards") on market stability before they are even enacted.