The Unified Audio Front-end LLM (UAF) is the first large language model specifically designed to consolidate core audio front-end tasks—VAD, SR, ASR, TD, and QA—into a single auto-regressive generative framework. It achieves state-of-the-art results across these tasks, notably outperforming existing multimodal LLMs in noisy, speaker-overlapping environments and reducing interaction latency for full-duplex systems.
TL;DR
Human conversation is fluid, interactive, and full-duplex. However, most AI assistants today still behave like walkie-talkies—processing audio in rigid blocks and stumbling when interrupted. UAF (Unified Audio Front-end LLM) by Alibaba Inc. collapses the entire front-end stack (VAD, Speaker Recognition, ASR, and Turn-taking) into a single generative model. By using a reference audio prompt to anchor the user's voice, it achieves breakthrough robustness in noisy, overlapping dialogue environments.
The Problem: The "Cascaded" Bottleneck
Traditionally, a speech assistant is built like a relay race:
- Signal Processing: Noise suppression and echo cancellation clean the audio.
- VAD/SR: Detects if someone is talking and who they are.
- ASR: Transcribes the speech.
- LLM: Generates a response.
This "Cascaded Architecture" is fundamentally flawed for full-duplex interaction. Each module introduces its own latency, and errors in early stages (like a VAD misjudging background noise as a user) propagate downstream. Furthermore, traditional noise suppression often destroys subtle speech cues, ironically making ASR harder.
Methodology: Perception as Generation
The core insight of UAF is to treat "listening" and "sensing" as a sequence prediction problem. Instead of outputting just text, the model outputs State Tokens that represent the interaction flow.
1. The Architecture
UAF utilizes an Encoder-Projector-LLM framework. It processes audio in 600ms chunks, allowing the system to react in sub-second intervals.
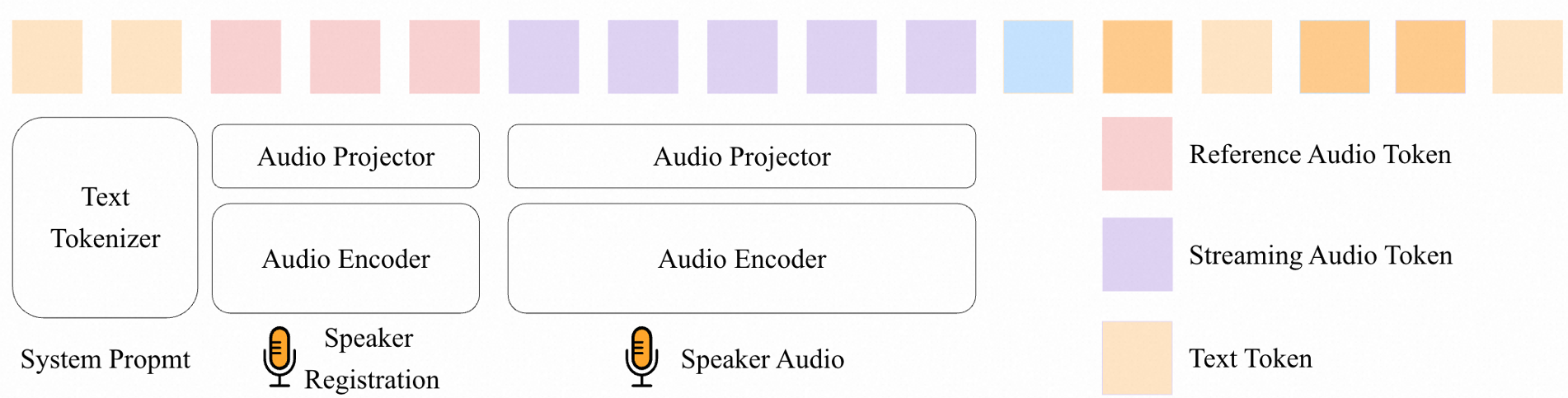
2. Speaker Anchoring
One of UAF's most powerful features is the Reference Audio Prompt. By feeding a 3-5 second clip of the target speaker at the start of the context, the model uses the attention mechanism to "filter" out other voices and system echoes. This mimics the human "Cocktail Party Effect" at a neural level.
3. Decoupled Heads: Perceive First, Transcribe Later
The authors made a critical discovery: if the VAD/Turn-taking tasks share the same Head as the Language Model (ASR), the model gets "impatient." It tries to transcribe before the user is finished. To solve this, UAF uses Dedicated Task Heads for VAD and Turn-taking, allowing the LLM to monitor the "state" of the conversation continuously while only triggering ASR when a semantic boundary is reached.
Experiments & Results: Robustness Under Fire
The experimental results highlight UAF's superiority in complex acoustic environments.
Speaker-Aware ASR Performance
When tested against interfering speakers and heavy noise (Low SNR), UAF leaves general-purpose audio LLMs in the dust. At 2 dB SNR, while other models fail with WERs above 30%, UAF maintains a clinical 5.34 WER.

Mastery of Interaction
In turn-taking detection, UAF achieves 100% accuracy in identifying interruptions. This is the "holy grail" of full-duplex systems—the ability to know exactly when the user wants the AI to shut up and listen.
Deep Insight: A Paradigm Shift
UAF represents a shift from Signal-level perception to Semantic-aware perception. Because the front-end is part of the LLM, the system doesn't just "hear" volume; it "understands" whether a sound is a user hesitating ( <InComplete> ), an accidental background noise ( <SIL> ), or a deliberate backchannel ( "Uh-huh" ).
Limitations
Despite its prowess, UAF currently relies on a 30B-parameter backbone for its best results, which may pose challenges for edge-device deployment. Additionally, the need for a reference audio prompt means users must "enroll" their voice, complicating zero-shot interactions with new users.
Conclusion
UAF proves that the future of interactive AI lies in Unified Perception. By moving beyond the modular cascade, we get systems that are not just smarter, but faster and more "human" in their listening behavior. For the next generation of AI agents, listening is no longer a preprocessing loop—it is an integral part of the intelligence itself.