Uni-OPD is a unified On-Policy Distillation (OPD) framework designed for both Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). It introduces a dual-perspective optimization strategy that addresses exploration bottlenecks and teacher supervision unreliability, achieving SOTA results across 16 benchmarks in math, code, and multimodal reasoning.
TL;DR
On-Policy Distillation (OPD) is the current frontier for transferring reasoning capabilities from massive teachers to efficient student models. However, "hallucinating" teacher signals—where the teacher prefers a wrong student path—often sabotages training. Uni-OPD fixes this by introducing a dual-perspective recipe: it forces the student to explore harder, informative states and strictly calibrates teacher feedback to be consistent with the actual ground-truth outcome.
The "Liar" Teacher Problem: Why OPD Fails
In the standard OPD paradigm, a student generates a solution, and a teacher model provides token-level feedback by comparing its log-probabilities to the student's. The intuition is simple: imitate the teacher while being on-policy.
However, the authors identify a fatal flaw: Unreliable Supervision. Because student rollouts often drift into Out-of-Distribution (OOD) regions, the teacher’s scoring becomes noisy. You might encounter an "Overestimation of incorrect trajectories"—where a teacher rewards a wrong path because it "sounds like" a smart reasoning pattern—or "Underestimation of correct trajectories"—where a teacher punishes a creative but correct solution.
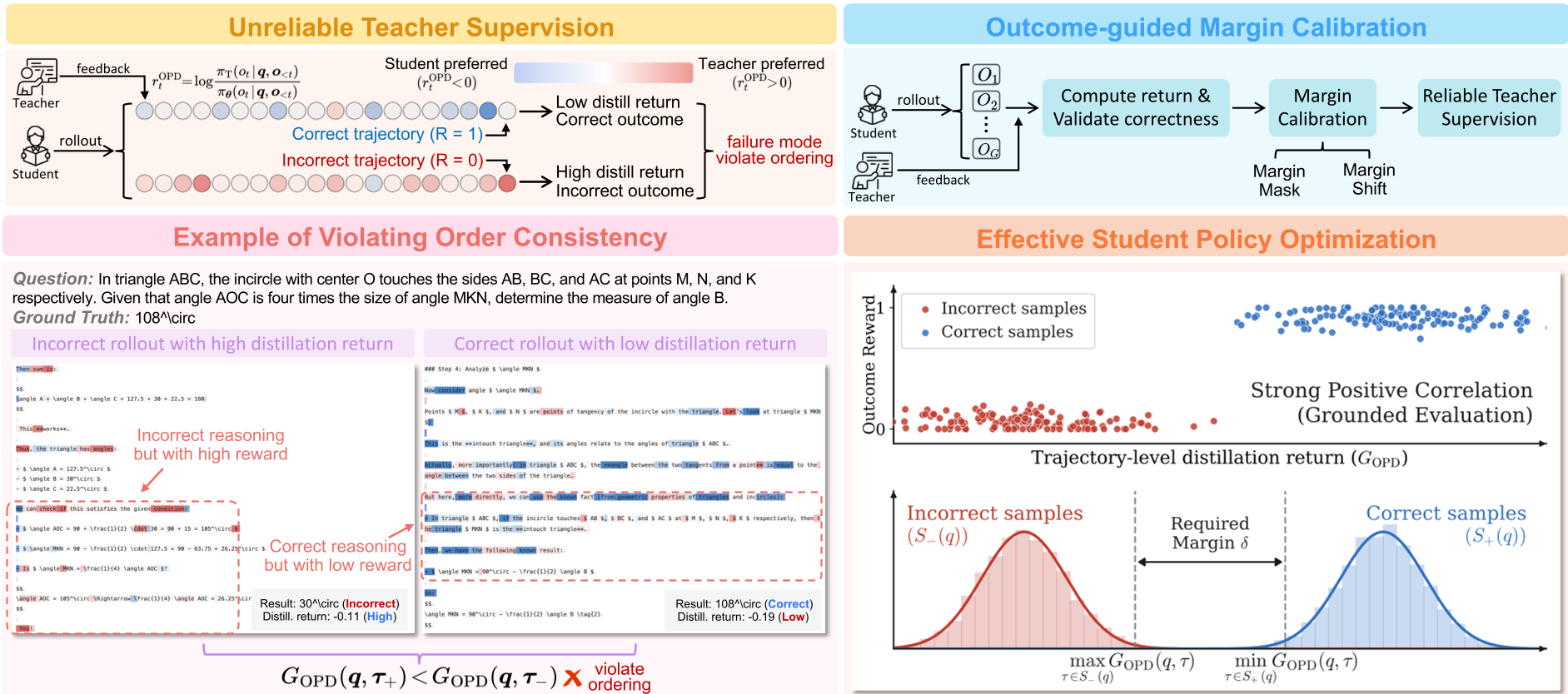 Figure 1: Standard teacher supervision vs. Outcome-guided calibration. The right side shows how Uni-OPD aligns the teacher's preference with the ground-truth outcome.
Figure 1: Standard teacher supervision vs. Outcome-guided calibration. The right side shows how Uni-OPD aligns the teacher's preference with the ground-truth outcome.
Methodology: The Dual-Perspective Recipe
1. The Student Perspective: Exploration via Balancing
The authors argue that removing "easy" or "hard" samples (common in RL) kills diversity.
- Offline Difficulty-Aware Balancing: Instead of filtering, they upsample "mid-difficulty" samples— those the student gets right only occasionally. This flattens the J-shaped distribution into a uniform one.
- Online Correctness-Aware Balancing: During training, they explicitly prevent the model from collapsing by ensuring a 1:1 ratio of correct and incorrect trajectories in each batch, providing rich contrastive signals.
2. The Teacher Perspective: Outcome-Guided Margin Calibration
This is the core innovation. If a student produces a Correct trajectory () and an Incorrect one (), the "Order Consistency" rule dictates that the teacher's total return for must be higher than for .
If the teacher fails this (i.e., rewards the wrong answer more), Uni-OPD applies Margin Shift: This shifts the returns to restore a safety margin (), ensuring the student never learns to prefer a wrong answer just because the teacher was "confused."
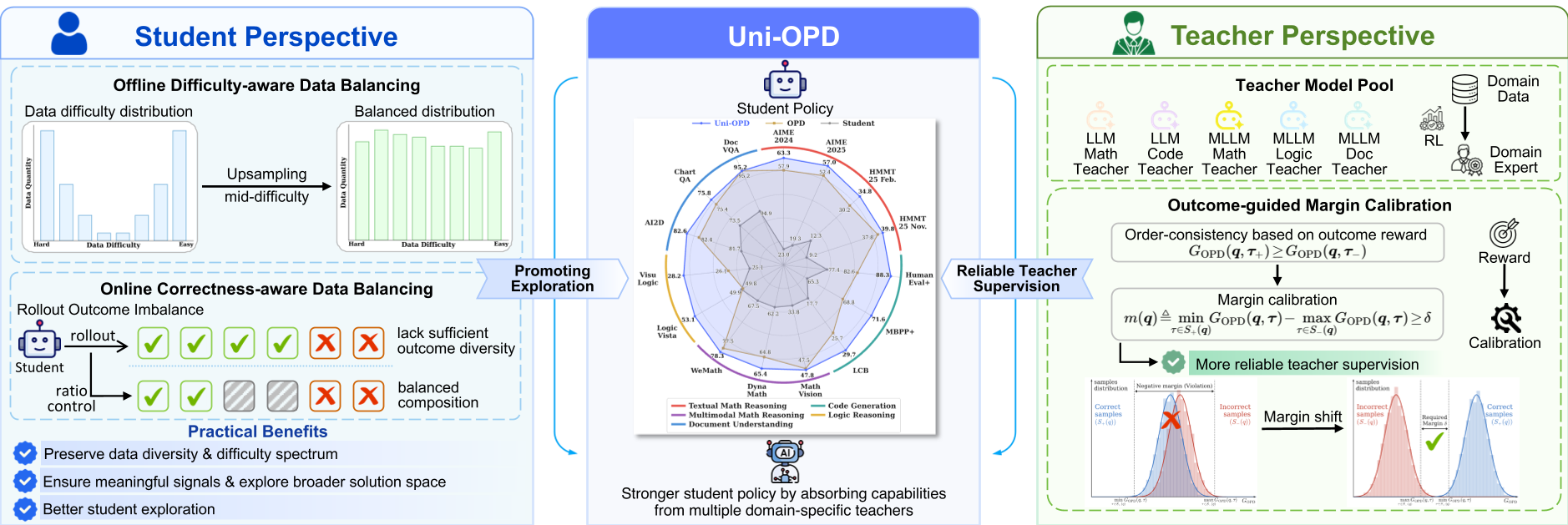 Figure 2: Overview of Uni-OPD. Note the integration of multiple domain-specific teachers (Math, Code, VL) into a single student policy.
Figure 2: Overview of Uni-OPD. Note the integration of multiple domain-specific teachers (Math, Code, VL) into a single student policy.
Experimental Battleground: SOTA Performance
Uni-OPD was tested across a massive array of 16 benchmarks, including LLM and MLLM tasks.
- Breaking the Capacity Barrier: It enables a tiny 1.7B model to absorb reasoning from a 30B teacher, reaching a 52.7 average on Code benchmarks—a massive leap for small-scale intelligence.
- Cross-Modal Synergy: In perhaps the most interesting result, the authors show that textual code data training actually helps multimodal math reasoning. Reasoning is a "modality-agnostic" capability that Uni-OPD captures effectively.
| Method | Math Avg (LLM) | Code Avg (LLM) | Multimodal Math Avg | | :--- | :---: | :---: | :---: | | Student (4B) | 15.9 | 53.5 | 54.5 | | Standard OPD | 47.0 | 60.2 | 57.9 | | Uni-OPD (Ours)| 48.5 | 63.6 | 61.0 |
 Figure 3: Token-level reward heatmap. After calibration (right), the correct rollout (bottom) correctly receives higher cumulative reward than the incorrect one (top).
Figure 3: Token-level reward heatmap. After calibration (right), the correct rollout (bottom) correctly receives higher cumulative reward than the incorrect one (top).
Critical Insight & Conclusion
Uni-OPD proves that for effective distillation, the teacher is not a god. The teacher's token-level preferences must be anchored to a ground-truth reward. By treating the outcome as a "Global Anchor," Uni-OPD stabilizes the training of smaller models, making them not just imitators of a teacher's style, but robust solvers of the actual problem.
The framework's success in cross-modal distillation suggests a future where a single multimodal student can act as a "Swiss Army Knife," unifying specialized experts from entirely different modalities into one efficient agent.