本文提出了 Uni-OPD,一个通用的在线策略蒸馏(On-Policy Distillation, OPD)框架,旨在统一 LLM 和 MLLM 在后训练阶段的能力增强。通过引入双视角优化策略,Uni-OPD 在 16 个基准测试中展现了卓越的性能,成功实现了跨模型、跨模态以及从强模型到弱模型的能力迁移。
TL;DR
在大型语言模型(LLM)和多模态模型(MLLM)的后训练阶段,如何高效地将专家的“智慧”传承给轻量级学生模型?腾讯 LLM 团队与浙江大学联合提出的 Uni-OPD 给出了答案。它通过学生侧的数据探索平衡和教师侧的置信度边界校准,解决了在线策略蒸馏(On-Policy Distillation)中长期存在的探索不足与监督信号失真问题,实现了跨模态、跨规模的 SOTA 性能平衡。
痛点深挖:为什么简单的“师教生”行不通?
在线策略蒸馏(OPD)虽然比传统的离线 SFT 能更好地缓解曝光偏差(Exposure Bias),但开发者往往会发现两个致命问题:
- 无效探索:学生模型要么一直在做它已经会的“简单题”,要么在面对完全摸不着的“天书”,导致训练梯度缺乏信息量。
- 教师的“幻觉”偏见:教师模型对学生生成的错误路径有时会给出莫名其妙的高分(Overestimation),或者由于路径与教师习惯不符而打低分。这种评分与最终正确性(Outcome)的脱节,会让优化过程陷入混乱。
核心机制:双视角优化配方(Dual-Perspective Recipe)
Uni-OPD 的核心设计逻辑在于:让学生“练得精”,让老师“教得准”。
1. 学生视角:难度与正确性的动态平衡
- 离线难度感知(Offline Difficulty-aware):不同于传统的直接丢弃简单/困难样本,作者发现保持多样性至关重要。Uni-OPD 选择性地对“中等难度”的样本进行过采样,将 J 型或 U 型的分布拉平,从而强制模型在最有潜力的区域进行探索。
- 在线正确性感知(Online Correctness-aware):在训练过程中,动态调整 Batch 内部正确与错误轨迹的比例,防止模型坍缩到局部最优。
2. 教师视角:结果引导的边界校准(Outcome-guided Margin Calibration)
这是 Uni-OPD 最精妙的设计。作者定义了一个**顺序一致性(Order Consistency)**准则:
任何正确的轨迹(Positive Trajectory),其从老师那获得的平均奖励必须高于错误轨迹(Negative Trajectory)。
如果老师给出的 Token 级奖励均值违背了这一准则,Uni-OPD 会启动边界偏移(Margin Shift):利用最终的结果 Reward 作为锚点,给正确路径加上一个偏移量,给错误路径一个惩罚项,强制拉开它们之间的差距。
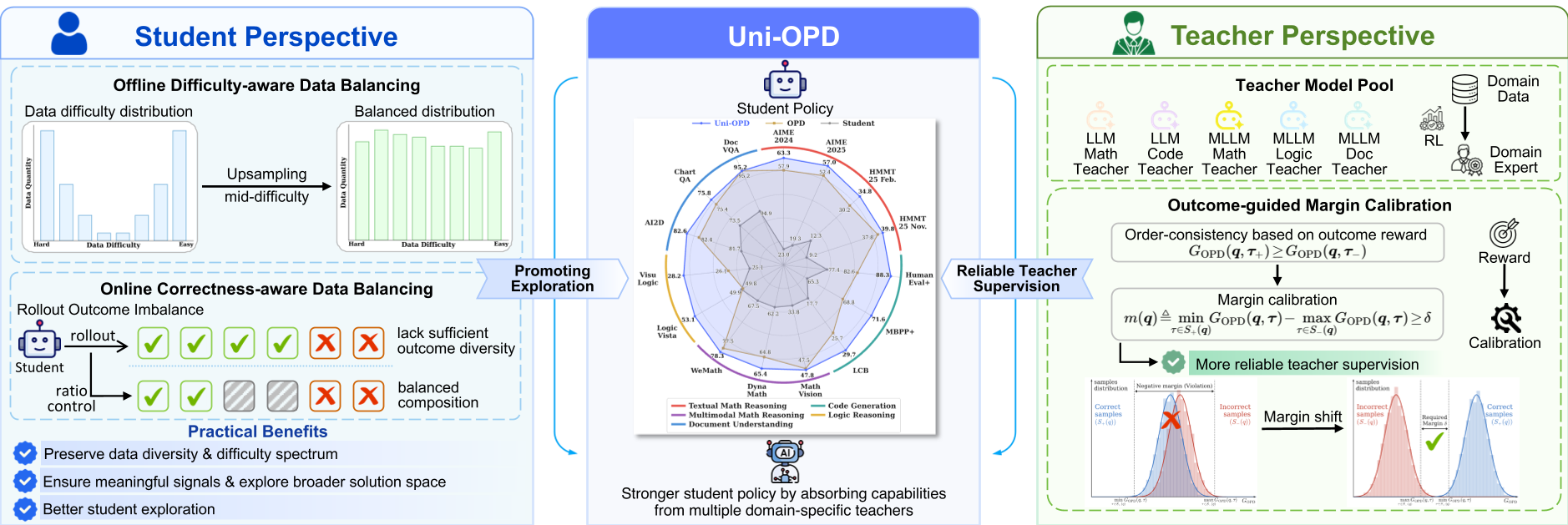 图 1:Uni-OPD 框架概览。左侧为数据均衡采样,右侧为边界校准机制。
图 1:Uni-OPD 框架概览。左侧为数据均衡采样,右侧为边界校准机制。
实验战绩:跨模态、跨规模的降维打击
SOTA 对比:
在 16 个基准测试中,Uni-OPD 表现强劲。即使是将 30B 强模型的推理能力蒸馏到 1.7B 或 4B 模型中(Strong-to-Weak),性能不仅大幅超越传统的 SFT 和 vanilla OPD,甚至在某些指标上逼近了原始教师模型。
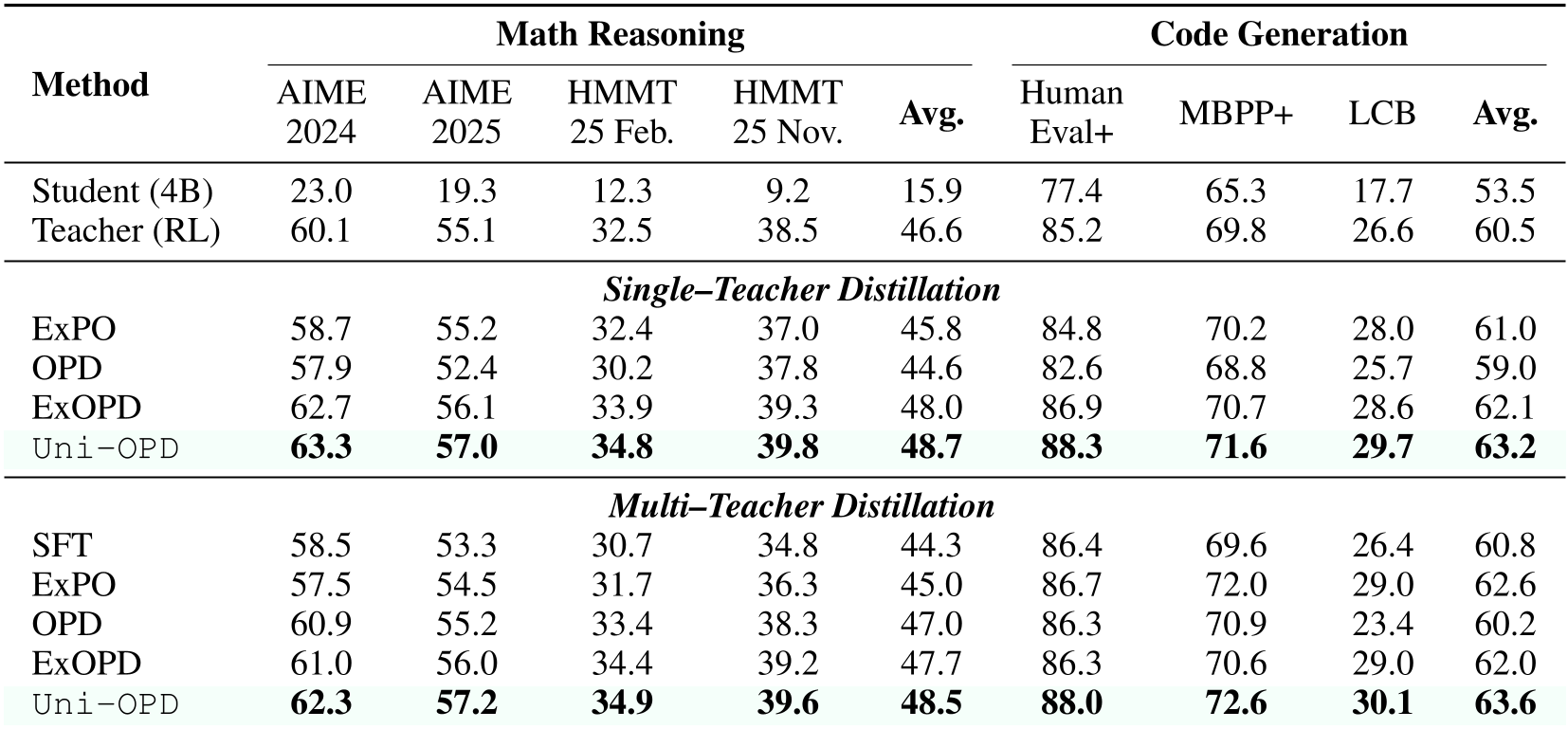 表 1:在数学推理与代码生成任务中,Uni-OPD 显著提升了学生模型的上限。
表 1:在数学推理与代码生成任务中,Uni-OPD 显著提升了学生模型的上限。
跨模态能力迁移:
最引人注目的发现是——推理能力是模态无关的。Uni-OPD 成功将纯文本专家的逻辑推理能力注入到 MLLM 中,使得多模态模型在处理视觉图表、逻辑谜题时,表现得像纯文本专家一样严密。
 图 2:Token 级 Reward 热力图。经过校准后(右侧),正确路径与错误路径的区分度显著增强,颜色对比更加分明。
图 2:Token 级 Reward 热力图。经过校准后(右侧),正确路径与错误路径的区分度显著增强,颜色对比更加分明。
深度洞察与总结
Uni-OPD 的成功告诉我们,蒸馏不仅仅是模仿概率分布,更是模仿判断逻辑的顺序。
- 主要的价值:该工作为模型能力的“缝合”与“精简”提供了一套标准化方案。它证明了通过巧妙的反馈校准,小模型可以极其高效地吸收多领域专家的长处。
- 局限性:目前由于依赖外部教师模型的 Prefill logprobs,对于闭源 API 教师或超大规模部署仍有一定的工程挑战。
- 未来展望:这种“结果引导”的思想非常契合当前的 Reasoning Models(如 DeepSeek-R1, O1 系列),未来可能成为此类模型持续进化的核心组件。
Uni-OPD 不仅仅是一个算法框架,更是对“如何更有效地定义高质量监督信号”的一次深刻反思。对于正在追求轻量化、高性能模型的 AI 从业者来说,这无疑是一份极具参考价值的实战指南。