UniCorrn is the first unified correspondence Transformer that achieves geometric matching across 2D-2D, 2D-3D, and 3D-3D modalities using a single set of shared weights. By leveraging a novel dual-stream decoder architecture, it surpasses specialized SOTA models by 8% on 7Scenes (2D-3D) and 10% on 3DLoMatch (3D-3D) registration recall.
In the world of 3D computer vision, the ability to find "correspondences"—matching the same physical point across different views—is the bedrock of SLAM, Structure from Motion (SfM), and camera relocalization. Historically, this has been a fragmented field: researchers built specialized models for image-to-image (2D-2D), image-to-point (2D-3D), and point-to-point (3D-3D) matching.
UniCorrn (Unified Correspondence Transformer) changes the narrative by introducing a single, weight-shared architecture capable of handling all three tasks simultaneously, often outperforming the specialists at their own game.
TL;DR
UniCorrn is the first model to unify geometric matching across 2D and 3D domains using a shared Transformer-based backbone and a novel dual-stream decoder. It achieves a staggering 10% boost in registration recall on the 3DLoMatch benchmark and an 8% boost on the 7Scenes 2D-3D task, proving that joint training across modalities leads to stronger geometric priors.
The "Why": Why has unification been so hard?
The difficulty of unifying 2D and 3D correspondence lies in the structural heterogeneity of the data:
- Grid vs. Sparse: 2D images are dense, regular grids; 3D point clouds are sparse, irregular, and unordered.
- Architectural Constraints: Traditional 2D methods use "Cost Volumes" or "Image Pyramids" which don't scale to the coordinate-based nature of 3D points.
- Missing Global Context: Standard nearest-neighbor searches between feature descriptors are "one-shot" and cannot be refined through deep, stackable neural network layers.
UniCorrn's authors recognized that Attention is all you need to solve this—literally. Since attention matrices naturally represent matching costs (similarity), a well-designed Transformer should be able to "look" across modalities to find matches.
Methodology: The Dual-Stream Breakthrough
The core innovation is the Matching Decoder. If you attend source features to target features, you get a similarity matrix. But how do you turn that into a coordinate prediction while keeping the features "stackable" for refinement?
1. Decoupled Residual Streams
UniCorrn splits the information into two separate residual streams:
- Appearance Stream (): Processes visual/geometric descriptors.
- Positional Stream (): Processes coordinate-based embeddings.
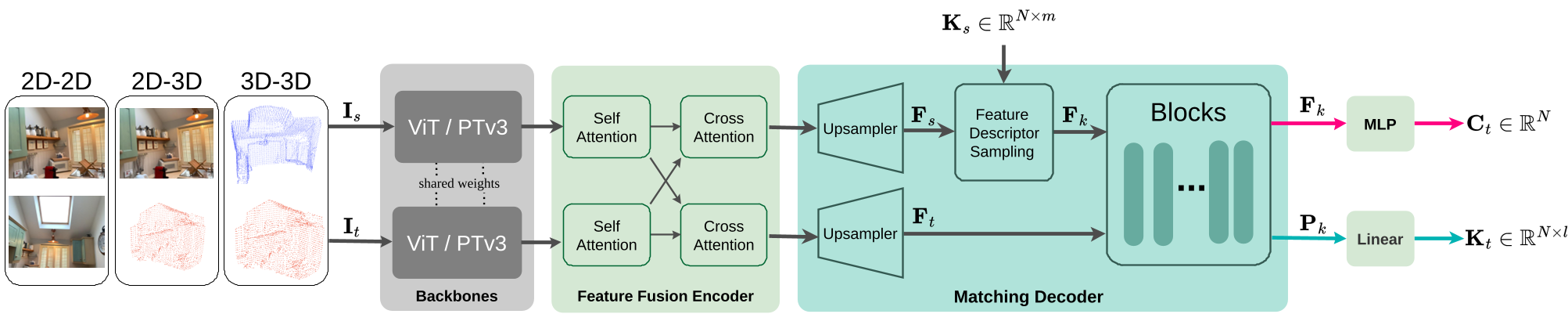
2. Gaussian Attention as Matching Cost
Instead of standard dot-product attention, UniCorrn uses a Gaussian Kernel. This captures non-linear complex correlations and is less sensitive to feature magnitude scales, which is critical when comparing a 2D CNN feature with a 3D Point Transformer feature.
3. Iterative Refinement
By stacking these dual-stream layers, the model gradually refines the predicted location. In each layer, the attention matrix (the "matching cost") becomes sharper, and the positional stream converges toward the ground-truth target coordinates.
Experimental Results: Surpassing the Specialists
The performance gains of UniCorrn are most visible in cross-modal (2D-3D) and low-overlap 3D tasks.
| Task | Benchmark | Metric | UniCorrn (Ours) | Previous SOTA | | :--- | :--- | :--- | :--- | :--- | | 2D-3D | 7Scenes | Registration Recall | 91.0% | 83.8% (Diff-Reg) | | 3D-3D | 3DLoMatch | Registration Recall | 83.2% | 79.0% (PEAL-3D) | | 2D-2D | ScanNet-1500 | AUC@20° | 71.3 | 70.9 (UFM) |

Why did joint training work? The authors performed a gradient conflict analysis. While there was some "interference" in normalization layers, the overall model benefited from the data-rich 2D domain (like MegaDepth) to learn robust features that helped sparse 3D matching.
Critical Insight & Future Outlook
UniCorrn proves that we don't need "specialist siloed models" for different sensors. However, the study identifies a key limitation: Normalization layer conflicts. When processing 2D grid statistics and 3D point statistics, shared BatchNorm or LayerNorm struggles. Solving this "statistical mismatch" could be the key to the first "Correspondence Foundation Model."
Summary: For any developer building cross-device 3D mapping (e.g., matching a mobile phone photo to a LiDAR scan of a building), UniCorrn represents a massive leap forward in both accuracy and pipeline simplicity.
For more details, check out the project website at neu-vi.github.io/UniCorrn/.