UniDex is a comprehensive robot foundation suite for universal dexterous hand control, featuring a large-scale robot-centric dataset (UniDex-Dataset) derived from human videos and a unified 3D vision-language-action (VLA) policy. The system achieves State-of-the-Art performance on complex tool-use tasks, significantly outperforming existing VLA baselines like π0.
TL;DR
Dexterous manipulation has long been the "hard mode" of robotics due to data scarcity and hardware variety. UniDex changes the game by converting over 50,000 human video trajectories into robot-executable data. By introducing a functional action space (FAAS) and a 3D VLA policy, UniDex enables robots to use scissors, spray bottles, and kettles with unprecedented success rates, even transferring skills to entirely new robot hands without additional training.
The Problem: The "Gripper Ceiling" and Data Bottleneck
Most modern robot foundation models (like OpenVLA or RTI) are "gripper-centric." While parallel-jaw grippers are easy to control, they are physically incapable of using human tools like scissors or complex spray bottles.
The transition to dexterous hands (multi-fingered) introduces three massive headaches:
- Data Cost: Teleoperating a 24-DoF hand is exponentially harder than a 1-DoF gripper.
- Embodiment Gap: A Shadow Hand does not look or move like an Allegro Hand.
- Visual Gap: Learning from human videos is cheap, but a robot's "eye" sees a metal claw where a human has skin and bone.
Methodology: Bridging the Gap with FAAS and Retargeting
1. Function-Actuator-Aligned Space (FAAS)
Instead of commanding raw joint angles (which vary by robot), the authors proposed FAAS. This space groups actuators by their functional role — for example, the "pinch" action of an index finger is mapped to the same coordinate whether the hand has 6 or 24 joints. This provides a universal "language" for hand control.
2. Human-to-Robot Transformation
To build the UniDex-Dataset (9M frames), the team pulled from egocentric datasets like HOI4D. They used a "human-in-the-loop" retargeting GUI to ensure that when a human picks up a cup in a video, the robot's simulated fingertips maintain physically plausible contact points. Crucially, they mask out the human hand and replace it with a rendered robot hand in the point cloud to ensure the model learns from the robot's perspective.
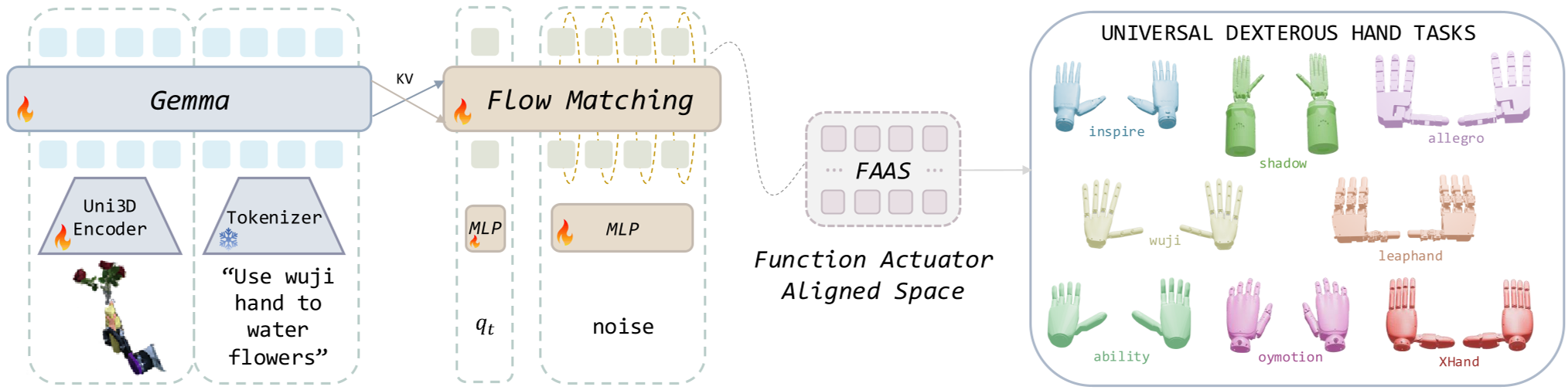 Figure: The UniDex-VLA architecture uses a Uni3D encoder to process point clouds, fused with language instructions to predict action chunks in the FAAS space.
Figure: The UniDex-VLA architecture uses a Uni3D encoder to process point clouds, fused with language instructions to predict action chunks in the FAAS space.
Experiments: Real-World Tool Use
The researchers tested UniDex-VLA on five grueling tasks: making coffee, sweeping, watering flowers, cutting bags with scissors, and using a computer mouse.
- Performance: UniDex-VLA achieved 81% task progress, nearly doubling the performance of π0 (38%).
- Zero-Shot Transfer: A policy trained on the 6-DoF Inspire Hand was deployed to the 20-DoF Wuji Hand. It worked immediately, proving that FAAS successfully abstracts away hardware differences.
- Data Efficiency: Using UniDex-Cap (a portable capture rig using Apple Vision Pro), they found that 2 human demonstrations are roughly as valuable as 1 expensive robot teleoperation demo.
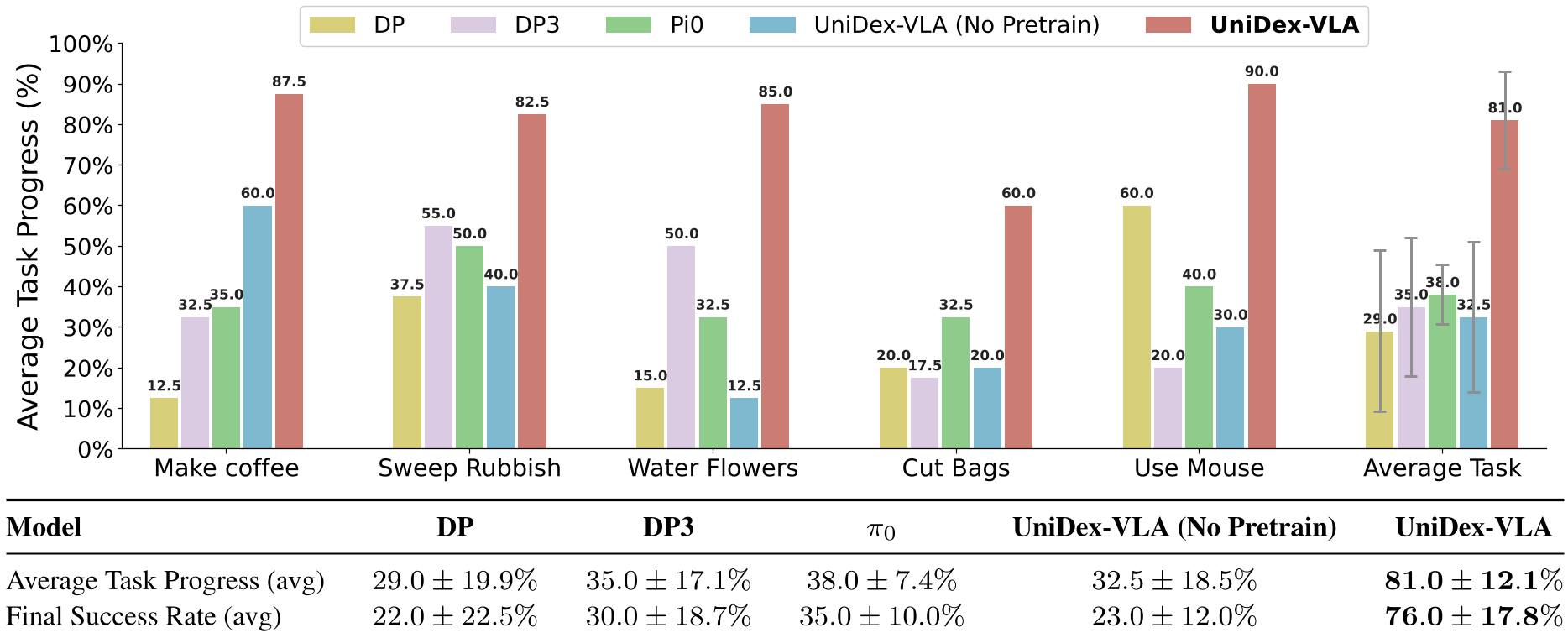 Figure: UniDex-VLA consistently outperforms Diffusion Policy (DP) and standard VLA baselines across all tool-use categories.
Figure: UniDex-VLA consistently outperforms Diffusion Policy (DP) and standard VLA baselines across all tool-use categories.
Critical Insight: Why Does This Work?
The secret sauce is the 3D representation. By using point clouds instead of 2D images, the model gains a geometric understanding of "contact affordances." When the model sees a pair of scissors, it isn't just looking at pixels; it's reasoning about where the fingers must fit in 3D space to apply leverage. Coupled with over 50k human-derived trajectories, the model develops a "motion prior" for how fingers should curl and exert force, which can then be fine-tuned for specific tools.
Conclusion & Future Outlook
UniDex represents a significant step toward "Universal Control." By decoupling the function of a hand from its mechanical joints, the authors have created a blueprint for a single brain that can control many bodies.
The main limitation remains the reliance on high-quality 3D data and the manual effort still required for some retargeting. Future work likely involves automating the retargeting further and incorporating "action-free" videos where no hand poses are explicitly labeled.
Takeaway: The future of dexterous robotics isn't just better hardware—its about translating the vast library of human movement into a format robots can finally understand.