UniVA is a Unified Value Alignment framework designed for industrial generative advertising recommendation. It reformulates the system from a semantics-centric paradigm to one where commercial value (bid, eCPM) is aligned across tokenization, decoding, and serving, achieving SOTA performance on the Tencent WeChat Channels platform.
TL;DR
The shift toward Generative Recommendation (GR) has transformed how industrial systems perceive items—moving from embeddings to discrete Semantic IDs (SIDs). However, in advertising, "relevance" isn't enough; "value" (revenue) is paramount. UniVA (Unified Value Alignment) is a new framework from Tencent and Wuhan University that embeds commercial value directly into the DNA of the generative process, leading to a massive 37% offline improvement and 1.5% online GMV lift.
Problem: The "Value Inconsistency" Trap
Existing GR systems are largely "semantics-centric." They assign IDs based on how an ad looks or sounds, not how much it earns. This leads to three systemic failures:
- Value-insensitive Tokenization: Ads for luxury cars and budget tires might share the same SID path because their descriptions are semantically similar, despite having vastly different bid profiles.
- Semantic-dominated Decoding: During beam search, a model might prune a high-value ad early because its "prefix" has a slightly lower linguistic probability.
- Value-unaware Serving: Online serving often wastes computation on "invalid" SID paths that don't satisfy specific advertiser targeting rules.
Methodology: The UniVA Framework
UniVA tackles these issues by propagating value signals through the entire pipeline: Tokenization Decoding Serving.
1. The Commercial SID (CSID) Tokenizer
Instead of relying solely on Residual Quantization (RQ) for IDs, UniVA introduces a hybrid structure. The upper levels of the ID tree handle semantics, while the final level is reserved for a Commercial Token.
- Classify-then-Bin: Ads are grouped by attributes (Industry, ROI, Goal) and then their bids are discretized into bins to maximize "Weighted Entropy." This ensures that ads in the same "leaf node" are truly similar in commercial value.
2. Generation-as-Ranking Decoder
UniVA discards the traditional "generate then re-rank" bottleneck. It uses a dual-head architecture:
- Generation Head: Predicts the next SID token to maintain semantic coherence.
- Value Head: Estimates the eCPM (Expected Cost Per Mille) for each potential token. The outputs are fused , allowing the model to "rank" while it "generates."
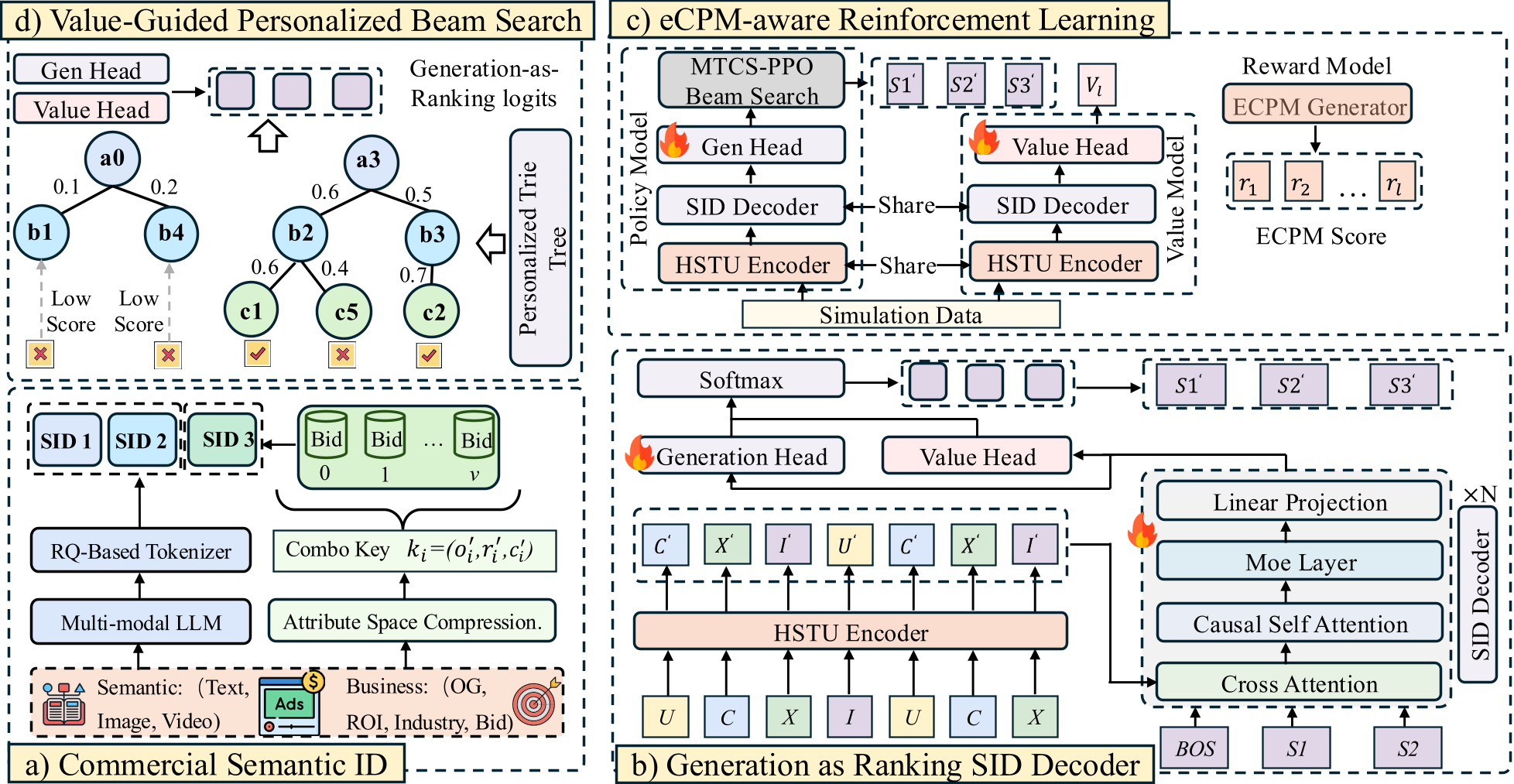 Figure 1: The UniVA framework showing the interaction between the encoder, dual-head decoder, and the RL simulator loop.
Figure 1: The UniVA framework showing the interaction between the encoder, dual-head decoder, and the RL simulator loop.
3. eCPM-aware Reinforcement Learning
To train the Value Head, the authors use an Offline Simulator and MCTS-PPO. By treating SID generation as a sequence of actions in an RL environment, the model learns which "token paths" lead to the highest total conversion value (GMV).
Experiments & Industrial Results
The authors tested UniVA on the Tencent WeChat Channels platform, one of the world's most demanding advertising environments.
Offline Performance Scaling
Transitioning from a basic decoder to the full UniVA stack (including Sparse MoE backbones) showed a clear scaling law. More parameters and better value alignment led to better conversion prediction.
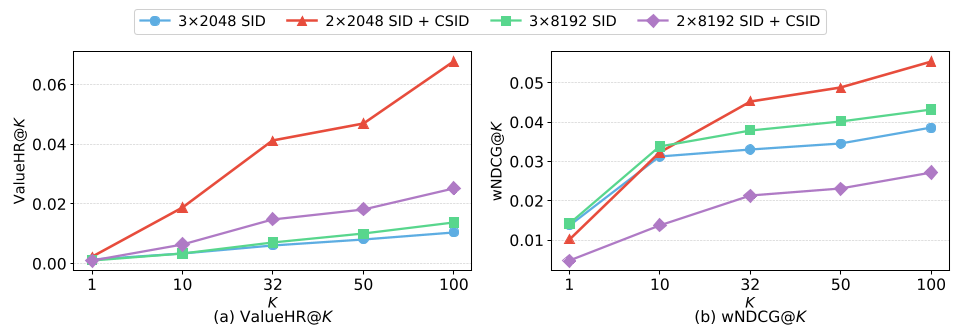 Table 1: Step-by-step gains from adding Commercial SID, MoE/MoR architectures, and RL-based value alignment.
Table 1: Step-by-step gains from adding Commercial SID, MoE/MoR architectures, and RL-based value alignment.
Visualizing Value Coherence
The success of the Commercial SID is best seen in "Bid Dispersion." Before UniVA, many ads with different bid ranges were lumped together. Now, the Bid Range (within a single SID path) has been reduced by nearly an order of magnitude (Figure 3 in the paper).
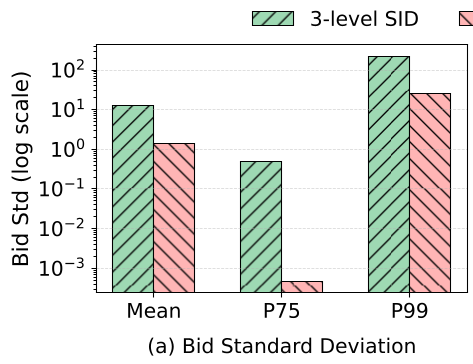 Figure 2: Comparing 3-level semantic SIDs vs. UniVA's Commercial SID. The tighter grouping on the right indicates more stable and predictable commercial performance.
Figure 2: Comparing 3-level semantic SIDs vs. UniVA's Commercial SID. The tighter grouping on the right indicates more stable and predictable commercial performance.
Critical Insight & Future Outlook
UniVA proves that Generative Recommendation is not just about LLMs "understanding" content—it's about building a unified vocabulary for business logic. By incorporating a "Personalized Tries Tree," UniVA also solves the cold-start and constraint-satisfaction problems that plague generative models in production.
Takeaway: In the future, we should expect more "Value Aligned" tokenizers. Whether it's for e-commerce (profit margin), streaming (watch time), or ads (eCPM), the way we discretize our world into IDs is the most powerful "Inductive Bias" we can give a generative model.
Conclusion
UniVA successfully bridges the gap between the semantic richness of LLM-based recommenders and the hard constraints of industrial advertising. It provides a blueprint for how to turn a generative "chatterbox" into a high-precision, value-maximizing engine.