UniGRPO is a unified reinforcement learning framework that jointly optimizes autoregressive text reasoning and flow-matching visual synthesis within a single MDP. Validated on the ByteDance-Seed/Bagel model, it achieves SOTA performance on GenEval (0.90) and Text Alignment benchmarks by aligning Chain-of-Thought (CoT) reasoning with image generation.
TL;DR
UniGRPO is a minimalist yet powerful RL framework that treats the entire process of Thinking (Text AR) and Drawing (Flow Matching) as a single, unified Markov Decision Process (MDP). By jointly optimizing these phases using Group Relative Policy Optimization (GRPO), the model learns to generate purpose-driven "thoughts" that directly improve the fidelity and alignment of the final image.
Perspective: Why Joint Optimization Matters
The field is converging on a hybrid architecture: Autoregressive (AR) transformers for language and Flow Matching for pixels. However, most models treat these as separate modules connected by a prompt. This results in "reasoning" that sounds plausible but doesn't actually help the model paint better details.
UniGRPO breaks this wall. It forces the model to receive a single terminal reward based on the final image, propagating visibility back through the reasoning tokens. If the "thoughts" don't help the "painting," the policy is penalized.
Methodology: The Architecture of Unified MDP
The authors define a two-phase state space:
- Text Phase: The model generates reasoning tokens $y_k$ (Chain-of-Thought).
- Image Phase: The model performs denoising steps $x_{t_k}$ conditioned on both the original prompt and the newly generated thinking tokens.
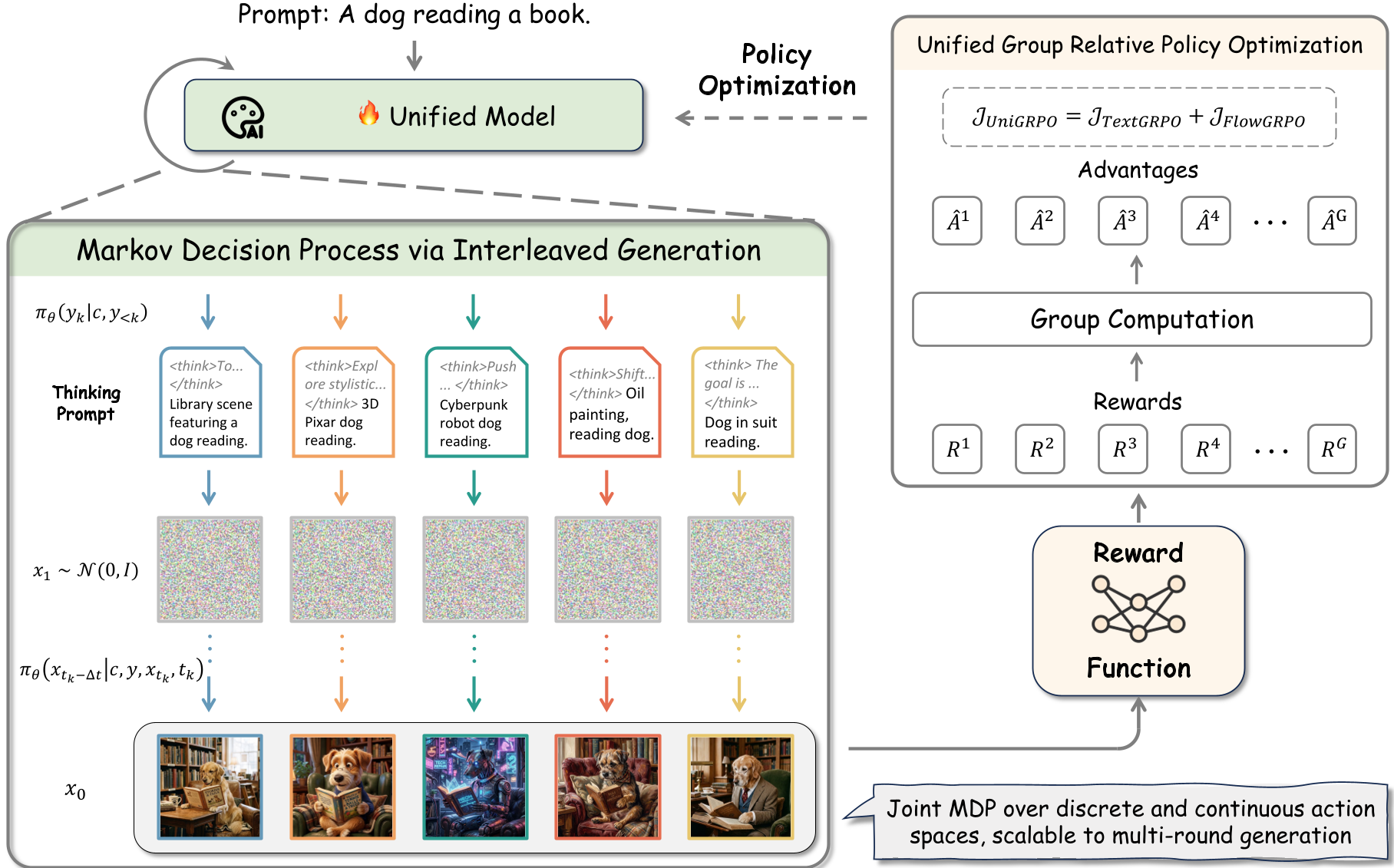
Two Critical Innovations for Scalability
- CFG-Free Training: Typically, models use Classifier-Free Guidance (measuring the difference between conditional and unconditional outputs). UniGRPO removes this during training. By calculating the advantage directly on a linear rollout, the model "internalizes" the alignment capability, saving 50%+ of compute and simplifying the gradient graph.
- Velocity MSE Regularization: Standard KL penalties on latents are inconsistent across the noise schedule, leading to "reward hacking" (e.g., the model finds a texture that gets a high score but looks like static). UniGRPO applies an MSE penalty directly on the velocity fields $v_ heta$, forcing the RL model to stay structurally close to the pre-trained base model.
Experiments and SOTA Results
The framework was tested on the Bagel architecture. After SFT, the model had decent capabilities, but UniGRPO pushed it to new heights.
| Method | Thinking | TA Score | GenEval | | :--- | :---: | :---: | :---: | | Bagel SFT | Yes | 0.7769 | 0.82 | | FlowGRPO | No | 0.8112 | 0.88 | | UniGRPO (Ours) | Yes | 0.8381 | 0.90 |
As shown in the ablation studies, the Velocity MSE (blue line) maintains a stable validation reward and high aesthetic quality, whereas "No KL" (red line) eventually crashes into reward-hacked garbage.
Visual Evidence: Does Thinking Help?
In Figure 6, we see the impact of UniGRPO. Instead of vague descriptions, the <think> block contains specific spatial and structural planning (e.g., "depicting six cups neatly spaced in two horizontal rows").

Critical Insight & Conclusion
UniGRPO proves that Post-Training is the new Pre-Training for multimodal models. By treating reasoning as a latent variable that must justify its existence through the quality of the final image, we move closer to "System 2" thinking for visual generation.
The limitation remains the Sparse Terminal Reward. Future iterations using Multimodal Process Reward Models (PRMs) to evaluate the logical consistency of the "thoughts" before the image is even drawn will likely be the next frontier in achieving true human-level visual intelligence.