UniMesh is a unified 3D vision framework that integrates 3D mesh generation and understanding into a single architecture by bridging the BAGEL diffusion model and the Hunyuan3D shape decoder. It achieves State-of-the-Art (SOTA) performance in text-to-3D generation (CLIP Image-Text similarity of 0.296) while enabling novel iterative semantic editing and self-reflective captioning.
Executive Summary
TL;DR: UniMesh is the first framework to truly unify 3D mesh generation and understanding within a single pipeline. By bridging the BAGEL diffusion model with the Hunyuan3D decoder via a novel "Mesh Head," it enables high-fidelity generation, zero-shot semantic editing through Chain-of-Mesh (CoM), and self-correcting 3D captioning.
Background Positioning: Traditionally, 3D vision is split: "Generators" create meshes but cannot describe them, while "Understanders" describe meshes but cannot modify them. UniMesh represents a transition toward Holistic 3D Intelligence, moving from "one-pass" synthesis to iterative, reasoning-based geometric modeling.
The Synergy Problem: Why Fragmentation Fails
Existing 3D systems suffer from a representation mismatch. If you want to edit a generated mesh today, you usually have to render it as an image, edit the image, and then re-reconstruct the mesh. This "lossy" loop introduces artifacts and loses geometric consistency.
The authors observed that Large Language Models (LLMs) solve complex problems through iteration (Chain-of-Thought). They asked: Can we treat 3D mesh generation as an iterative reasoning process where the model "thinks" about the mesh and refines it semantically?
Methodology: The Architecture of Unified Intelligence
UniMesh is built on three pillars:
1. The Mesh Head (The Interface)
Instead of converting generated image latents to RGB pixels and then back to 3D features, UniMesh uses a Mesh Head. It maps BAGEL's diffusion latents directly to Hunyuan3D's shape conditioning space.
- Insight: This preserves fine-grained semantic cues (like "holding a moon") that might be lost in low-resolution RGB rendering.
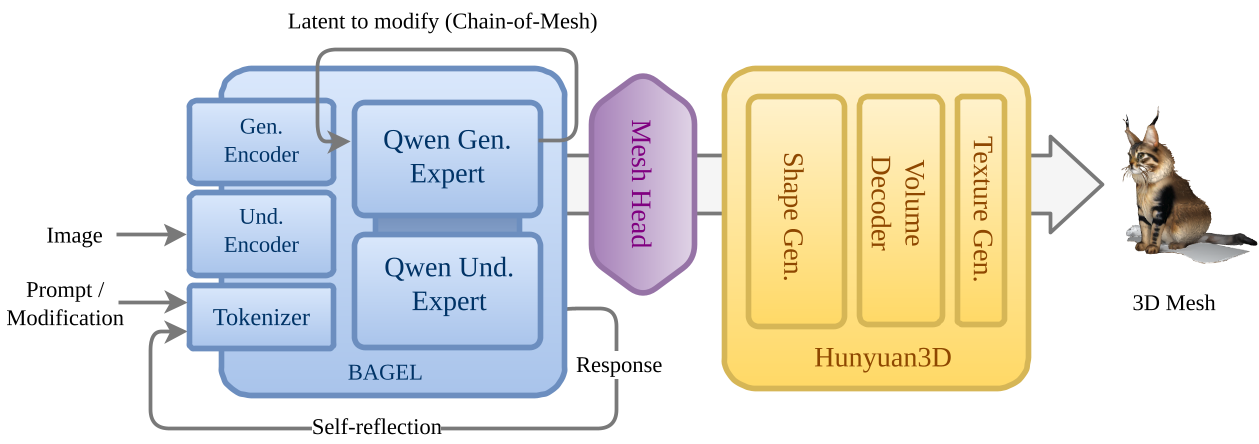 Fig 2: The architecture shows how the Mesh Head bridges semantic understanding (Qwen) with geometric synthesis (Hunyuan3D).
Fig 2: The architecture shows how the Mesh Head bridges semantic understanding (Qwen) with geometric synthesis (Hunyuan3D).
2. Chain-of-Mesh (Iterative Geometry)
Inspired by Chain-of-Thought, Chain-of-Mesh (CoM) allows for iterative editing. By feeding the current mesh's latent back into the system with a new prompt (e.g., "change color to red"), the model updates the latent space and regenerates a consistent, modified mesh.
3. Self-Reflection (The Critic)
For understanding tasks like captioning, UniMesh uses an Actor-Evaluator-Self-reflection triad. If an initial caption is vague, the "Evaluator" identifies the error, and the "Self-reflection" module provides verbal feedback to regenerate a more accurate description.
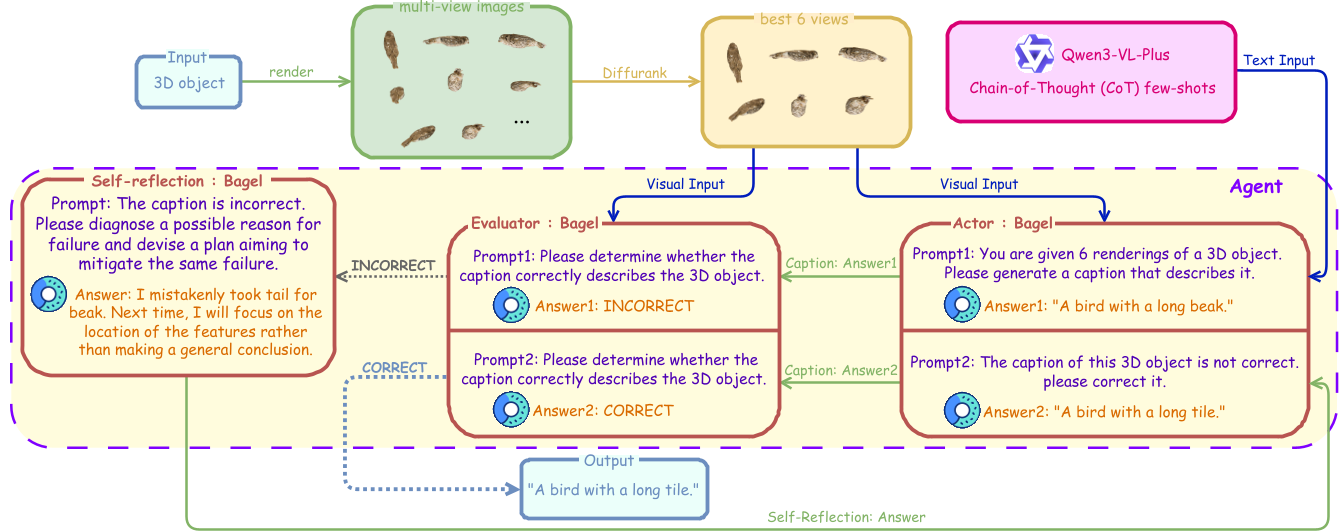 Fig 4: The feedback loop for 3D understanding using the Reflexion framework.
Fig 4: The feedback loop for 3D understanding using the Reflexion framework.
Experiments & Results
UniMesh is not just a theoretical unification; it sets new performance bars:
- Generation SOTA: On the DreamFusion prompt set, it achieved a CLIP Image-Text similarity of 0.296, outperforming specialized models like InstantMesh and LGM.
- Understanding Excellence: It achieved the best FID score (0.113) in 3D captioning, proving that its "self-reflected" captions are more natural and accurate than those from single-pass VLMs.
 Fig 1: Examples of iterative semantic edits (adding attributes, changing structure) enabled by the CoM mechanism.
Fig 1: Examples of iterative semantic edits (adding attributes, changing structure) enabled by the CoM mechanism.
Critical Analysis & Conclusion
Takeaway: The "Mesh Head" is the critical bridge. By bypassing RGB reconstruction, UniMesh proves that diffusion latents contain sufficient geometric information for high-fidelity 3D shape generation.
Limitations:
- The model still relies on 2D view rendering for its "understanding" module.
- The "Evaluator" (BAGEL-based) can sometimes make incorrect judgments, limiting the effectiveness of the self-reflection loop.
Future Outlook: UniMesh paves the way for Native 3D LLMs—models that treat 3D geometry not as a rendering task, but as a primary linguistic and structural entity to be reasoned about directly. We expect this "Generation-Understanding" loop to become the standard for future embodied AI and interactive 3D design tools.