UniMotion is the first unified framework capable of simultaneous understanding and generation across human motion, natural language, and RGB images. Built on a 1.5B LLM backbone, it achieves State-of-the-Art (SOTA) results across seven tri-modal tasks, including Text-to-Motion, Motion-to-Text, and Motion-guided Image Editing (MGIE).
TL;DR
UniMotion is the first truly "any-to-any" unified framework that treats human motion, text, and images as equals. By abandoning the traditional discrete tokenization (VQ-VAE) in favor of a fully continuous motion paradigm, it eliminates temporal jitter and achieves SOTA performance across 7 diverse tasks, including complex ones like Motion-guided Image Editing (MGIE).
Background: The "Tokenization" Bottleneck
For years, the community followed the MotionGPT paradigm: discretize motion into "tokens" so the LLM can treat it as a foreign language. However, this has two fatal flaws:
- Quantization Error: Rounding high-frequency motion data into a fixed codebook leads to "jittery" or unrealistic movement.
- Modal Asymmetry: Images are continuous; text is discrete. Forcing motion into a discrete space makes it harder for the model to "bridge" the gap between a visual pose and its mathematical representation.
UniMotion asks a bold question: What if we stop treating motion as a language and start treating it as a continuous physical signal?
Methodology: The Symmetric Tri-Modal Architecture
1. CMA-VAE: Bridging the Visual Gap
The core of UniMotion is the Cross-Modal Aligned Motion VAE (CMA-VAE). During training, the authors use a Dual-Posterior KL Alignment (DPA) strategy.
- The Intuition: A "Vision-Fused" encoder sees both the motion and the image, creating a rich semantic posterior. A "Motion-only" encoder is then forced via KL Divergence to mimic this rich distribution.
- The Result: At inference time, even if the model only sees 3D skeletal data, its latent space is already "pre-colored" with visual-semantic knowledge.
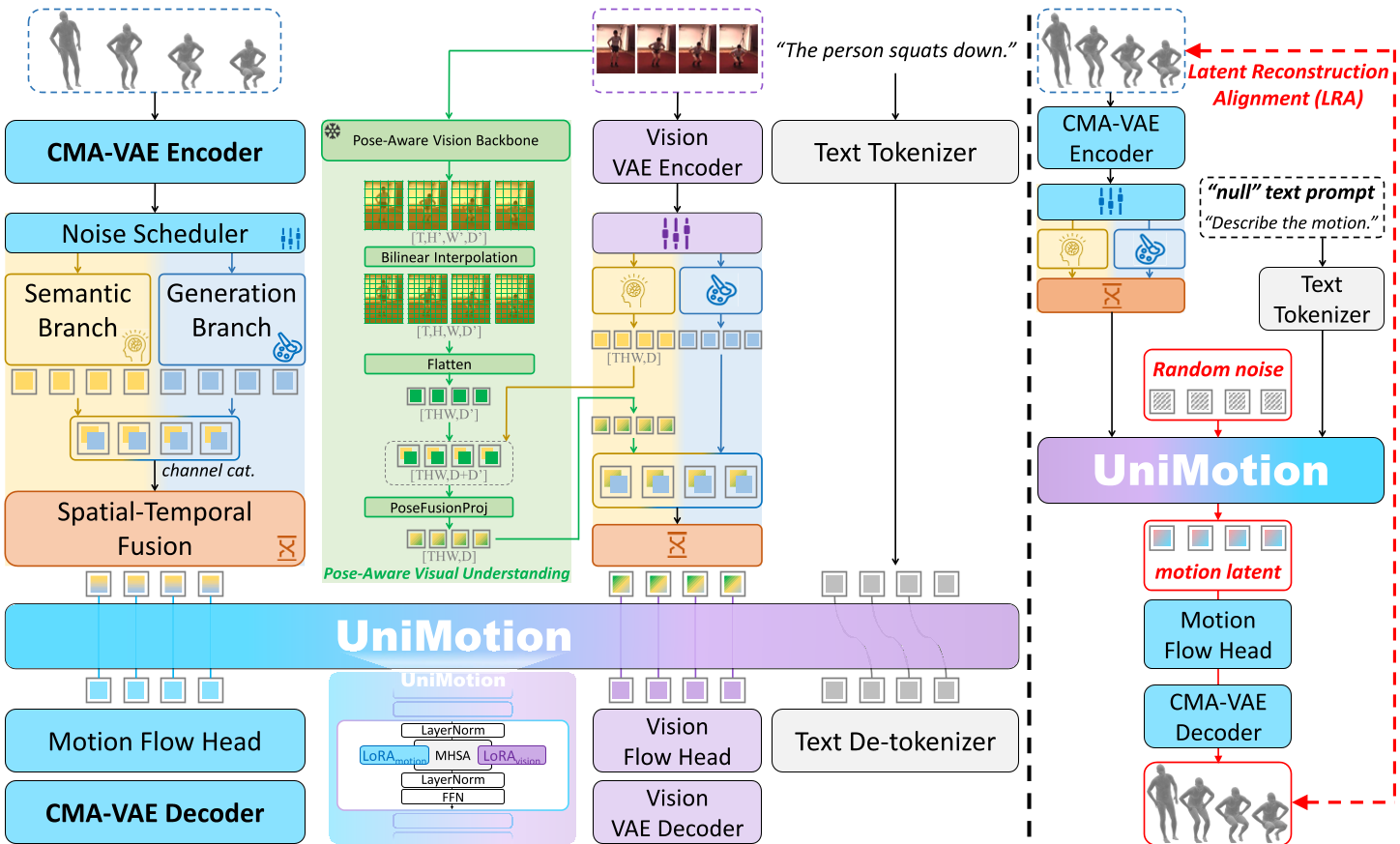
2. Dual-Path Embedders & Hybrid Attention
To handle the motion latents within the LLM, UniMotion employs a Dual-Path Embedder:
- Semantic Branch: Uses a Transformer to extract high-level "intent" (e.g., "running").
- Generation Branch: A simple MLP that preserves raw kinematic details.
Furthermore, they utilize Hybrid Attention. Unlike standard causal LLMs, this allows full bidirectional attention within a motion sequence (essential for physics-based consistency) while maintaining causal ordering for text tokens.
Solving the Cold-Start: Latent Reconstruction Alignment (LRA)
A major challenge in training unified models is that text is "sparse." A caption might say "a man walks," but the motion latent is "dense" (containing every joint angle). If you only train with text, the model struggles to calibrate the precise motion pathway.
LRA solves this by having the model reconstruct its own motion latents from noise (Motion-to-Motion) before learning from text. This "warm-up" ensures the LLM backbone and Flow Heads understand the geometry of the motion space before they ever see a word of English.
Experimental Results: True Tri-Modal Versatility
UniMotion was tested across seven tasks. The results are definitive: continuous representations win.
| Task | Metric | UniMotion | Previous SOTA (Representative) | | :--- | :--- | :--- | :--- | | Motion Captioning | BertScore | 41.2 | 36.7 (MG-MotionLLM) | | T2M Generation | R@3 | 0.841 | 0.807 (MoMask) | | Vision-to-Motion | MPJPE ↓ | 75.0mm | 81.8mm (UniPose) |
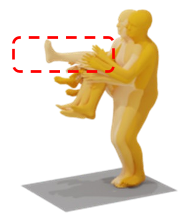
Qualitative Superiority
As shown in the comparison below, discrete models like MoMask often fail to capture specific height constraints (arms above head), whereas UniMotion’s continuous flow matching handles these with ease.
Critical Analysis & Future Outlook
Why does it work? The secret is the Reverse KL in the DPA loss. By being "mode-seeking," the motion encoder ignores noisy visual details (like background colors) and focuses strictly on the semantic modes relevant to the human pose.
Limitations: Processing motion as a continuous signal at 1.5B scale is computationally expensive. While the model excels at indoor datasets like Human3.6M, "wild" scenarios with extreme occlusions still pose a challenge for the frozen vision backbone.
Future Impact: UniMotion paves the way for Embodied AI where a robot can receive a visual command, describe what it's about to do, and generate the motor plan—all within a single, unified latent space.