UniScale is a synergistic co-design framework for industrial search ranking that jointly scales data and model architecture. It introduces the Entire-Space Sample System (ES3) for high-quality data expansion and the Heterogeneous Hierarchical Sample Fusion Transformer (HHSFT), achieving SOTA performance on billion-scale datasets.
Executive Summary
TL;DR: Alibaba's Taobao team presents UniScale, a framework that demonstrates that model scaling in search systems must be a "double-helix" of data and architecture. By expanding training data to the "entire space" (unexposed and cross-domain samples) and using a hierarchical Transformer (HHSFT), they achieved a 2.04% GMV boost in one of the world's largest e-commerce environments.
Background: While LLMs scale predictably with parameters, industrial ranking models often hit a performance ceiling. UniScale identifies that this is not a lack of parameters, but a data information bottleneck caused by biased, exposure-only training logs.
Problem & Motivation: The "Exposure Bias" Trap
In traditional search ranking, models only see what was shown to the user (Exposed Samples). This creates three major issues:
- Selection Bias: The model never learns how to handle the millions of items that weren't "good enough" to be shown, leading to training-inference mismatch.
- Exposure Bias: Users might buy an item later through a different path (e.g., a recommendation feed), but the search model treats the original unclicked search interaction as a "negative."
- Information Ceiling: Scaling a model to 1B+ parameters on the same small search log results in overfitting to noise rather than learning new patterns.
Methodology: The UniScale Framework
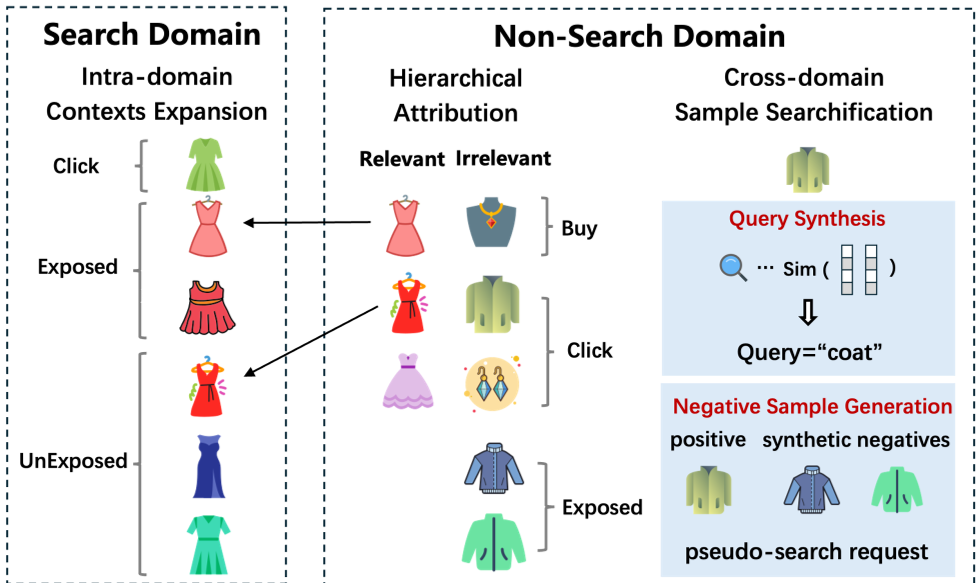
1. ES3: Entire-Space Sample System
To fix the data bottleneck, ES3 construct a unified training space:
- Intra-domain Expansion: It pulls in unexposed items and uses Hierarchical Label Attribution to give them "positive" labels if the user eventually bought them through ANY channel.
- Cross-domain Searchification: It takes user clicks from other domains (like Recommendations) and creates "synthetic queries" to make them look like search data, effectively "teaching" the search model about general user interests.
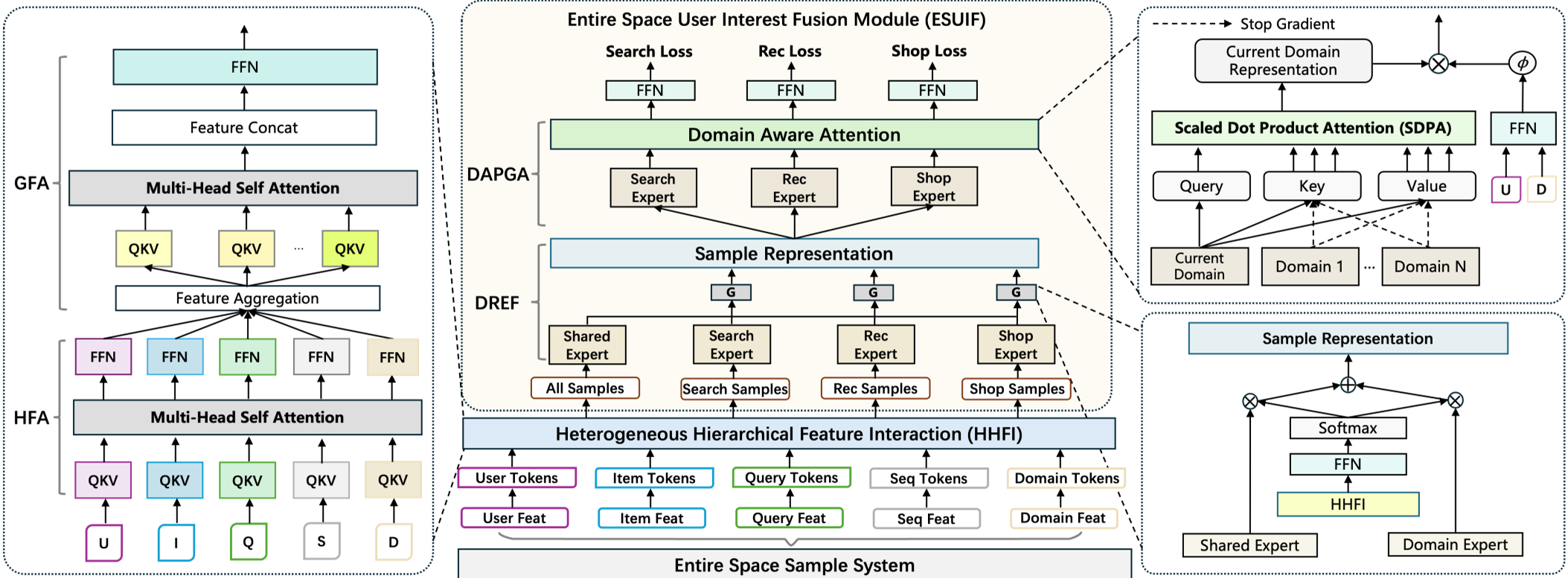
2. HHSFT: The Architecture for Heterogeneity
Scaling data introduces "noise" and "distribution shifts." HHSFT handles this via two layers:
- Heterogeneous Hierarchical Feature Interaction (HHFI): Unlike standard Transformers, it uses token-specific projection matrices. This prevents categorical IDs (like User ID) from being "confused" with continuous values (like Price) in the latent space.
- Entire Space User Interest Fusion (ESUIF): It uses a Domain-Routed Expert Fusion mechanism. Shared experts learn global patterns, while domain-specific experts act as filters to prevent cross-domain noise from "poisoning" the search ranking signals.
Experiments & Results
The authors validated UniScale on billion-scale datasets against SOTA baselines like Wukong and RankMixer.
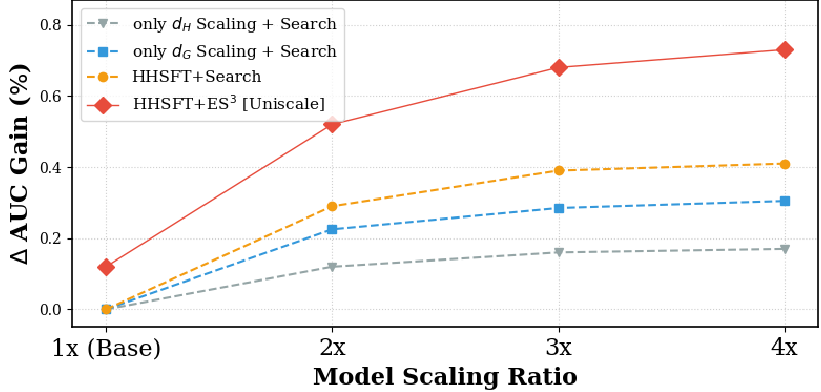
- Synergistic Scaling: As shown in the graph below, the gap between search-only data and UniScale's entire-space data widens as the model gets larger. This proves that bigger models require diverse data to reach their potential.
- Ablation Success: Using ES3 data with a standard backbone actually hurt performance (-0.43% AUC), while the HHSFT architecture turned that same data into a +1.14% gain.
Critical Analysis & Conclusion
Takeaway: UniScale shifts the focus from "just add more layers" to "how do we feed the layers better." It proves that for industrial systems, the architecture must be designed to protect the model from the noise of big data while absorbing its signals.
Limitations: The "Searchification" of cross-domain data relies on synthetic query generation, which may introduce semantic hallucinations if the underlying co-occurrence statistics are sparse.
Future Outlook: The authors envision "Trinity Scaling"—the simultaneous optimization of Samples, Features, and Architecture—as the next frontier for reaching LLM-level intelligence in recommendation systems.