Uno-Orchestra is a unified orchestration policy that jointly optimizes task decomposition and subtask routing to heterogeneous (model, primitive) pairs. By collapsing planning and dispatching into a single causal-LM backbone, it achieves SOTA performance across 22 baselines on a 13-benchmark suite, reaching 77.0% macro pass@1.
TL;DR
Uno-Orchestra is a breakthrough in multi-agent systems that treats task planning and model routing as a single, unified decision process. Unlike previous systems that either simply route to one model or always force complex workflows, Uno-Orchestra learns to be "parsimonious"—decomposing only when necessary and dispatching tasks to the cheapest possible capable worker. It beats the best existing benchmarks by 16% in accuracy while being 10x cheaper.
Problem & Motivation: The Orchestration Paradox
As LLMs proliferate, we face a "capabilities vs. cost" ladder spanning three orders of magnitude. Traditional systems fail in two specific ways:
- Rigid Routing: They treat every query as a single unit or "atom," missing the parallelizable sub-structure of complex tasks.
- Decoupled Planning: They use one model to plan and another to route, creating massive context overhead and failing to optimize the "depth" of the plan against the actual execution budget.
The authors' central insight: Orchestration is a single causal-LM problem. A model should be able to say, in one forward pass, "This part of the problem needs GPT-4 via Python execution, but this other part can be handled by Gemini Flash via direct answer."
Methodology: Selective Delegation and Agentic-GRPO
Uno-Orchestra transitions through four modes of behavior: Lazy (direct answer), Oneshot (parallel subtasks), Continuation (sequential reasoning), and Decomp-Repair (fixing failures).
1. Unified Architecture
The system utilizes a single Qwen2.5-7B backbone that serves as both the planner and the dispatcher. It emits an XML-based DAG (Directed Acyclic Graph) where each node is an "admissible pair" consists of:
- Worker Model: (e.g., Claude-3.5-Sonnet, GPT-4o, Gemini Flash).
- Primitive/Skill: (e.g.,
web_search,execute_python,symbolic_math).
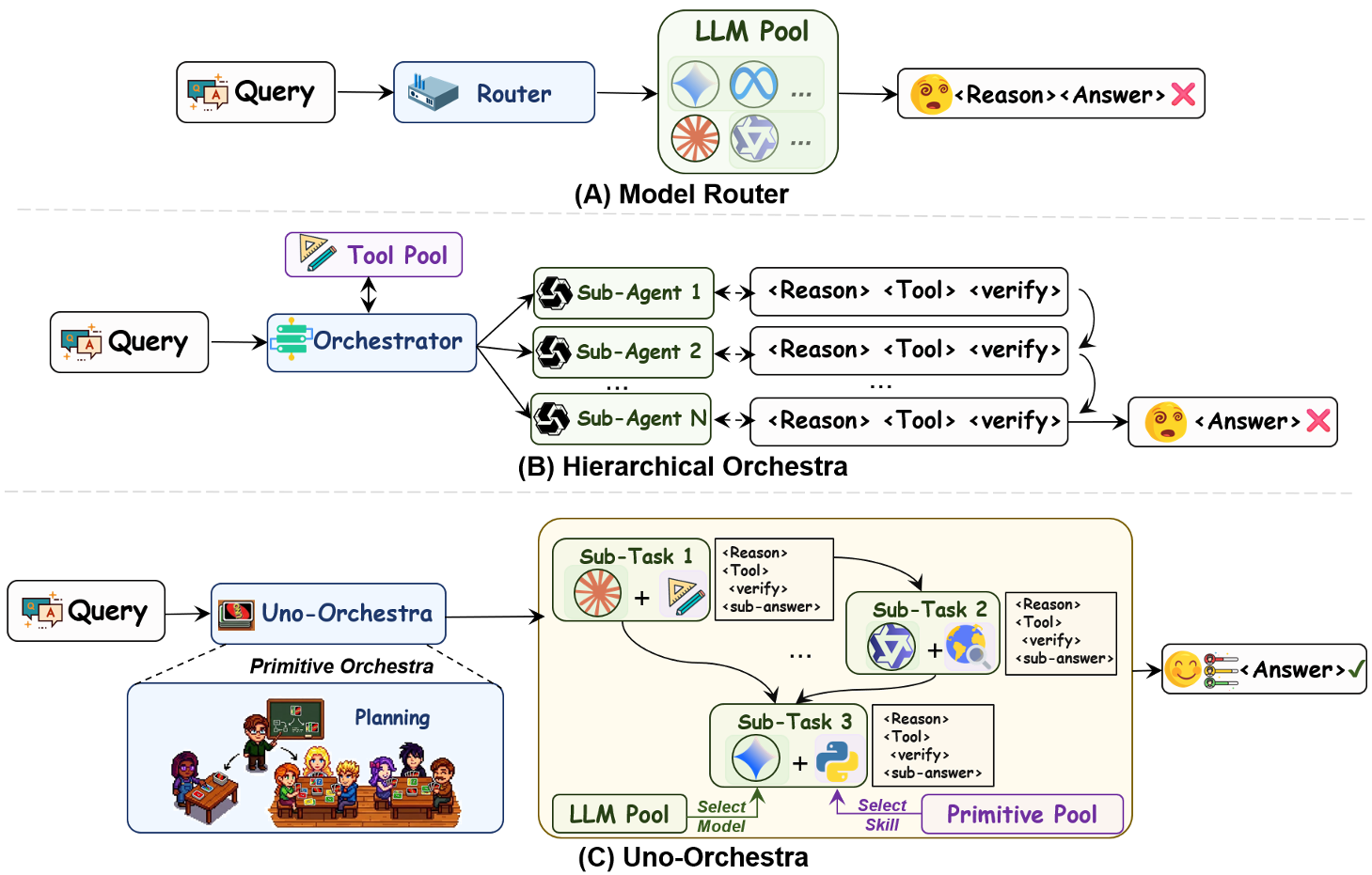 Figure 1: Contrast between standard routers, hierarchical systems, and the integrated Uno-Orchestra approach.
Figure 1: Contrast between standard routers, hierarchical systems, and the integrated Uno-Orchestra approach.
2. Agentic-GRPO
Standard RL (like vanilla GRPO) struggles with multi-turn tasks because the reward only comes at the very end. If a model makes a great planning decision in Turn 1 but fails to aggregate in Turn 3, the whole trajectory gets a "0." Agentic-GRPO introduces Turn-level Credit Assignment. It distributes parts of the final terminal reward back to individual turns and adds "process shaping" rewards (e.g., rewarding valid XML schema or successful tool calls) to guide the model through the long-horizon desert.
Experimental Results: Breaking the Pareto Frontier
The results are striking. Across 13 benchmarks (Math, Code, Agentic tools, etc.), Uno-Orchestra doesn't just improve accuracy; it shifts the entire efficiency curve.
- Accuracy: 77.0% macro pass@1 (vs. 67.2% for the strongest baseline).
- Thrift: It achieves this at roughly 1.20 per query.
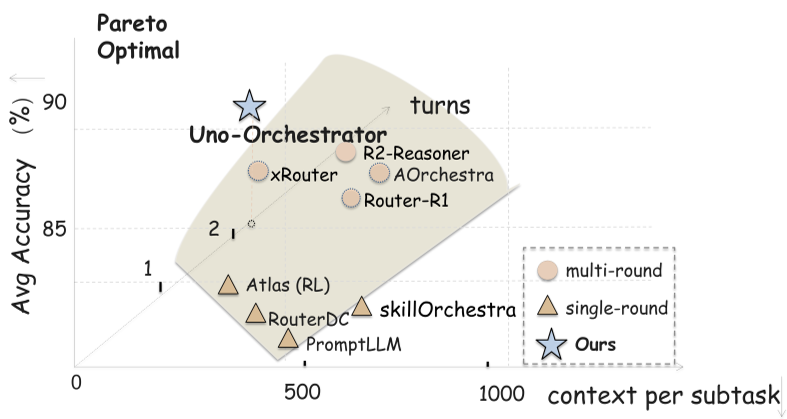 Figure 2: Uno-Orchestra (bottom-right) dominates the Accuracy-Cost frontier, offering high performance at near-minimal cost.
Figure 2: Uno-Orchestra (bottom-right) dominates the Accuracy-Cost frontier, offering high performance at near-minimal cost.
The "Lazy" Advantage
A key reason for the efficiency is the "Lazy" mode (15.6% of trajectories). On simple queries, the model recognizes it doesn't need a multi-agent swarm and just answers directly. This "abstention from complexity" is what allows it to save massive amounts of context and cost compared to traditional "agentic workflows" that always trigger multi-step processes.
Critical Analysis & Conclusion
Takeaways
- Joint Optimization Matters: Learning "Whether to decompose" and "Who to route to" together is strictly superior to treating them as separate steps.
- Anonymized Training: The authors trained the router on "anonymous" worker labels to prevent the model from simply relying on "brand names" (like GPT-4), forcing it to actually learn the capability profiles of different workers.
Limitations
- Verifier Dependency: The RL quality is still highly dependent on having a ground-truth verifier. In "open-ended" real-world tasks where no symbolic or exact-match answer exists, the reward signal becomes much noisier.
- API Latency: While token costs are low, the wall-clock time is still subject to the slowest worker in the DAG.
Future Work
The "Selective Delegation" principle is likely the future of "Computer Use" agents. As models begin to interact with operating systems, the ability to parsimoniously decide between expensive "reasoning" steps and cheap "action" steps will be the difference between a viable product and an expensive research demo.