本文提出了一种名为 Text Embedding Interpolation 的无需训练(Training-free)的图像编辑框架。该方法通过在文本编码器的嵌入空间中寻找特定概念的转向向量(Steering Vector),实现了对生成模型(如 FLUX, Qwen-Image)在推理阶段的连续、可控语义编辑。
TL;DR
传统的图像编辑往往深陷于 LoRA 微调或架构特定模块的泥潭,导致新模型适配成本高昂。本文提出了一种极简视角:无需训练,仅通过 LLM 自动寻找文本编码器中的“转向向量”(Steering Vector),配合弹性范围搜索,就能在 FLUX、Wan2.1 等模型上实现如丝般顺滑的连续编辑(如控制笑容程度、年龄增长或季节变换)。
核心洞察:从“权重学习”回归“语义导航”
随着生成模型(如 Flux, Qwen-Image)的语义理解能力日益强大,复杂的辅助模块可能不再是必须。作者认为,**线性表征假设(Linear Representation Hypothesis)**在生成模型的文本编码器中依然成立。
这意味着,我们不需要为了一个“笑容”滑块去训练一个 LoRA,只需要在语义空间中找到“微笑”到“严肃”的那条直线,然后让输入的文本嵌入(Text Embedding)沿着这条线滑动。
技术细节:如何构建一个完美的“滑块”?
1. 自动化的语义发现
作者并没有手动设计对比实验,而是利用 LLM 自动生成上百对去偏的对比 Prompt(例如:“一个微笑的人” vs “一个表情严肃的人”)。通过对这些 Prompt 在文本编码器末层的输出进行**均值差(Difference-of-Means)**计算,提取出核心转向向量 。
2. 精准打击:LLM 辅助的 Token 选择
这是本文的一个关键点:不要暴力修改所有的 Token 嵌入。如果你想让一个人的脸变老,却修改了“背景中的树”的 Embedding,会导致严重的伪影。 作者启发式地使用 LLM 来判断哪些 Token 属于“主体”、哪些属于“风格”,仅对相关的 Token 实施转向操作。
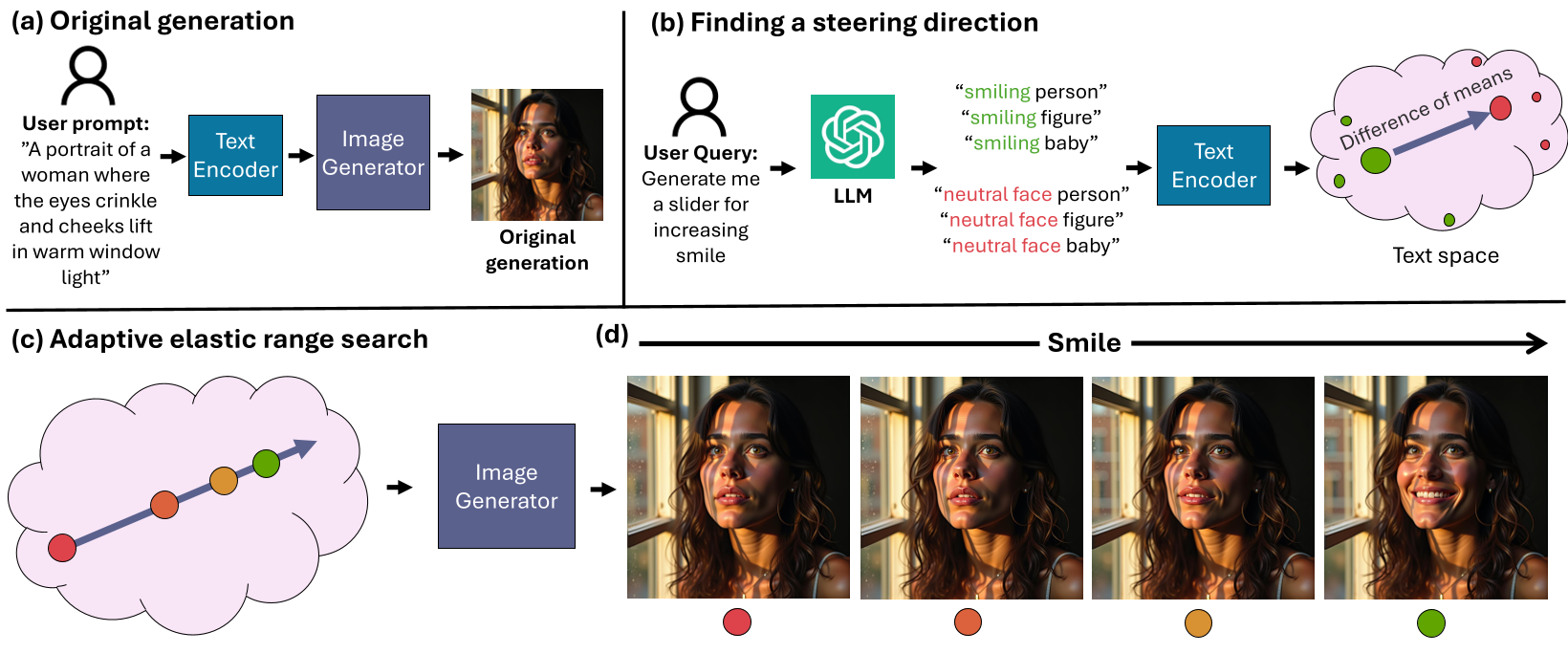 图 1:框架全景图。从 LLM 生成对比对,到 Token 选择,再到最终的线性插值生成。
图 1:框架全景图。从 LLM 生成对比对,到 Token 选择,再到最终的线性插值生成。
3. 弹性范围搜索 (Elastic Range Search)
编辑强度 设多少合适?太小没效果,太大图像会崩坏。 作者引入了**弹性带优化(Elastic-band Optimization)**思想:
- MOVE:根据感知距离(DreamSim)自动调整采样点,确保滑块在每一段的视觉变化都是均匀的。
- EXPAND:在变化剧烈的区域自动插入更多采样点。
- Adaptive:自动识别出模型能承受的最大强度边界,防止生成结果背离流形(Off-manifold)。
实验战绩:以简胜繁
在 FLUX.dev 底座上,这种“无训练”方法展现出了惊人的竞争力。
- 编辑成功率:在 Qwen-Image-Edit 这种强力模型上,本方法的 ΔVQA 达到 0.63,甚至超过了专门训练的 SliderEdit。
- 内容保留度:通过 DreamSim 指标验证,该方法在改变局部属性时,能极好地维持原图的纹理与背景。
- 通用性:该方法不改动权重,因此直接“零成本”迁移到了视频生成模型(如 Wan2.1),实现了视频风格的连续控制。
 图 2:定性结果展示。可以看到在年龄、拥挤程度、照片写实度等维度,本方法都实现了平滑且无伪影的过渡。
图 2:定性结果展示。可以看到在年龄、拥挤程度、照片写实度等维度,本方法都实现了平滑且无伪影的过渡。
局限性与思考
尽管表现卓越,该方法仍受限于底座模型的“知识上限”。例如,如果模型本身画不出六个手指的手,转向向量也无法强行纠正这种固有的归纳偏置(Inductive Bias)。此外,视频领域的感知度量缺乏也限制了自动校准算法在视频中的应用。
总结
这篇论文是对“大道至简”的再次诠释。它提醒我们,随着基础模型能力的爆炸式增长,很多曾经需要重型微调才能解决的问题,现在也许只需要在 latent 空间里做一次优雅的偏移。对于开发者而言,这提供了一种无需显存训练、逻辑高度解耦的插件式编辑新思路。