UW-VOS is the first large-scale underwater Video Object Segmentation (VOS) benchmark, featuring 1,431 videos, 409 categories, and over 300k mask annotations. The authors also propose SAM-U, a parameter-efficient adaptation of SAM2 that achieves state-of-the-art results using a novel Underwater Domain Adaptation (UDA) block.
Executive Summary
TL;DR: The underwater world presents a "hall of mirrors" for computer vision: colors disappear, contrast fades, and organisms blend perfectly into their surroundings. UW-VOS is a landmark contribution that provides the first massive-scale dataset to train models for this hostile domain. Alongside it, SAM-U proves that we don't need to retrain massive foundation models from scratch; by tuning just 2% of SAM2's parameters with underwater-aware "gates," we can surpass full fine-tuning performance.
Positioning: This work is both a foundational benchmark (filling a massive data void) and a SOTA architectural refinement for parameter-efficient domain adaptation.
The "Red Light" Problem: Motivation
Why do SOTA models like Cutie or XMem fail when submerged?
- Spectral Attenuation: Red light is absorbed within meters, causing a heavy blue-green shift that destroys the color-based discriminative power of terrestrial models.
- Biological Camouflage: Evolution has perfected underwater "cloaking," making boundary detection significantly harder than in cityscapes.
- Small & Fast: 56.3% of objects in UW-VOS are "small targets," often moving erratically or exiting/re-entering the frame.
Standard benchmarks like DAVIS or YouTube-VOS simply don't prepare models for these physics-based degradations.
Methodology: Engineering the Underwater Prior
The authors propose SAM-U, which adapts the SAM2 (Hiera) backbone without breaking its pre-trained "common sense."
1. The Architecture Shift
Instead of full fine-tuning, which often causes "catastrophic forgetting" of general object concepts, SAM-U freezes the early layers of the encoder and inserts Underwater Domain Adaptation (UDA) blocks into the later, more semantically sensitive stages.
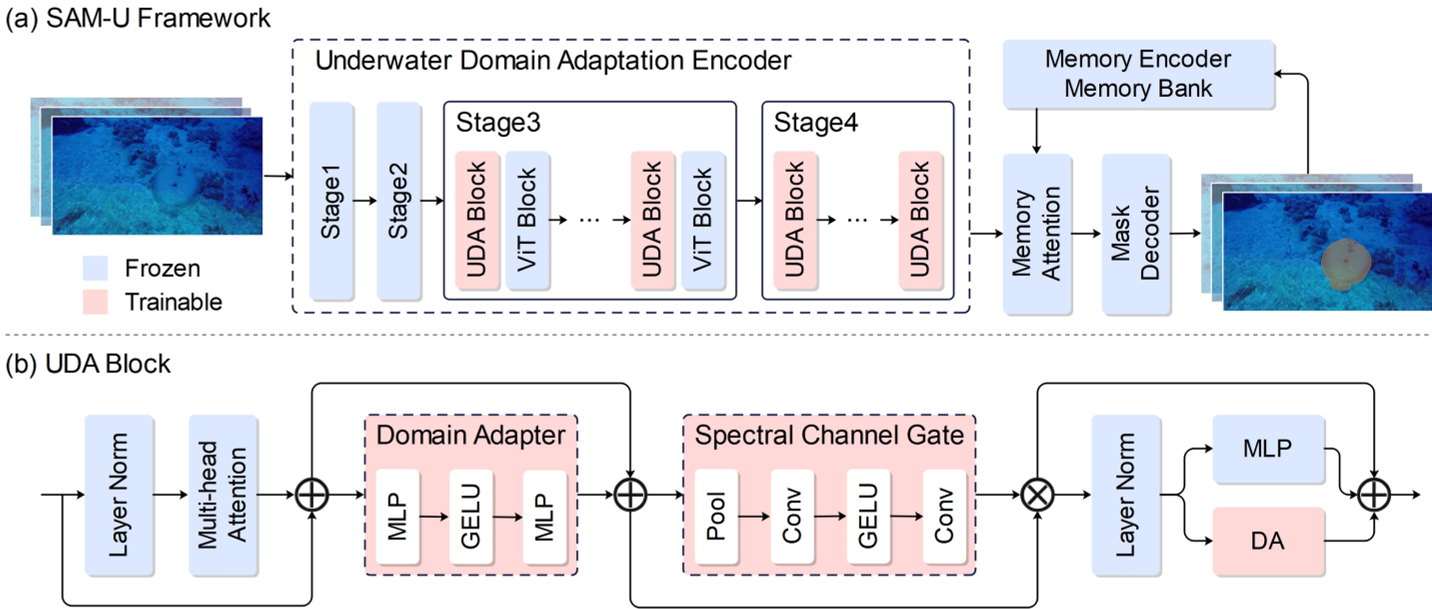
2. The Spectral Channel Gate (SCG)
This is the "secret sauce." Since underwater degradation is wavelength-dependent, the SCG module uses global average pooling to learn channel-specific scaling factors. It essentially acts as a learnable color-correction filter that tells the network which feature channels to trust when the "red" information is missing.
Experiments: Breaking the Bottleneck
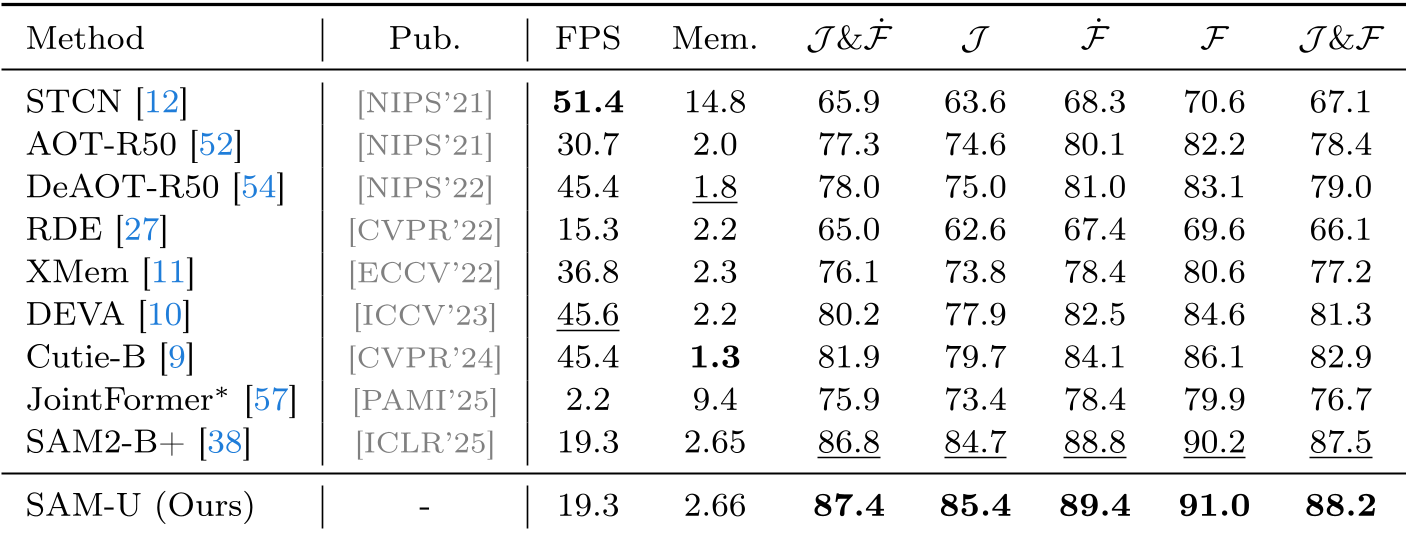
The team benchmarked 9 major VOS frameworks. While foundation models like SAM2-B+ showed the most robustness in zero-shot settings, they still struggled with Camouflage (CAM) and Exit-Re-entry (ER).
Key Results:
- Accuracy: SAM-U achieves 88.2 J&F, a +0.7 gain over full SAM2 fine-tuning.
- Efficiency: It uses only 1.5M trainable parameters (vs 80.8M in full tuning).
- Data Efficiency: The authors found a "negative transfer" threshold—fine-tuning with less than 5% of the data actually hurts performance, emphasizing the need for their large-scale dataset.
Critical Insight: Why PEFT Wins Here
The most profound takeaway is that for domain-specific tasks (like underwater or medical imaging), Parameter-Efficient Fine-Tuning (PEFT) isn't just a workaround for low compute—it's an optimizer. By freezing the bulk of the transformer, we keep the high-level "objectness" knowledge intact and only allow the UDA blocks to adjust for the "environmental noise."
Conclusion & Future Outlook
UW-VOS sets a new gold standard for marine AI. The attribute-based analysis identifies Camouflage and Small Targets as the remaining "dark matter" of underwater vision. Future work will likely need to integrate Temporal Memory specifically tuned for the erratic swimming patterns of marine life, potentially moving toward multi-modal (sonar + visual) fusion.
Takeaway for Practitioners: If you are adapting a foundation model to a specialized environment, don't just "unfreeze all." Use lightweight, physically-inspired gates like the SCG to guide the adaptation.