The paper introduces VTAM (Video-Tactile Action Model), a multimodal world model that integrates high-resolution tactile sensing (GelSight) with multi-view video into a predictive Transformer backbone. By jointly forecasting future visual and tactile latents, VTAM achieves SOTA performance in contact-rich tasks like potato chip handling and peeling, outperforming vision-only baselines by up to 80%.
TL;DR
While current Vision-Language-Action (VLA) models are impressive at following instructions, they are "physically clumsy" when it comes to delicate tasks like picking up a potato chip without crushing it. This paper introduces VTAM (Video-Tactile-Action Model), which gives robots a sense of touch by embedding tactile perception directly into a predictive "world model," leading to a massive 80% improvement in success rates for force-sensitive tasks.
The "Blind Spot" of Vision-Only Robotics
Most state-of-the-art robots rely almost exclusively on vision. However, vision has a fundamental limitation: occlusion. When a robot's gripper closes around an object, the most important physical interaction—the contact point—is hidden from the camera. This leads to two major failure modes:
- Over-grasping: Crushing fragile objects (like potato chips).
- Under-grasping: Failing to detect a slip until the object has already fallen.
Prior attempts to fix this by "tacking on" tactile sensors often fail because of modality collapse—the model’s training is so dominated by visual data that it eventually learns to ignore the noisy, high-frequency tactile signals.
Methodology: Perception as Prediction
VTAM shifts the paradigm from reactive sensing to predictive world modeling. Instead of just looking at the current state, the model uses a high-capacity Video Transformer to predict how both the visual scene and the tactile surface will evolve.
1. Joint Visuo-Tactile Latents
The system processes two camera views and one GelSight tactile stream through a shared Variational Autoencoder (VAE) space. By using a Multi-View Diffusion process, the model learns the temporal correlation between a robot's movement and the resulting deformation of the tactile sensor.
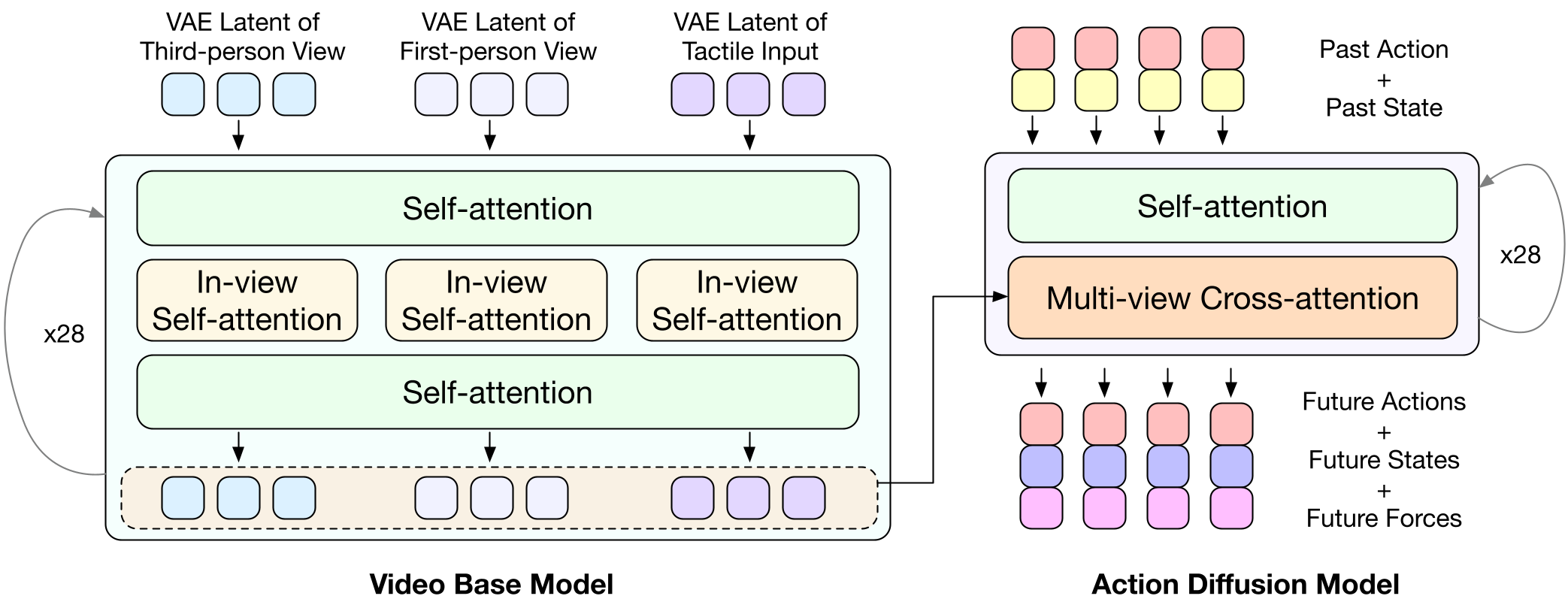 Figure: The VTAM framework. Note the alternating intra-view and cross-view attention that blends visual and tactile features.
Figure: The VTAM framework. Note the alternating intra-view and cross-view attention that blends visual and tactile features.
2. Solving Modality Collapse: Virtual Force Regularization
To ensure the model doesn't ignore the tactile data, the authors introduced Virtual Force Prediction. They calculate a 3D force proxy based on optical flow from the tactile sensor—measuring tangential shear (sliding) and normal compression (pressing). By forcing the model to predict these forces as an auxiliary task, the tactile branch remains "active" and influential during the entire learning process.
Experimental Showdown: VTAM vs. π0.5
The researchers tested VTAM against heavyweights like the π0.5 (a scaled VLA) on three brutal tasks:
- Potato Chip Pick-and-Place: Must detect contact and modulate force to avoid fractures.
- Cucumber Peeling: Requires maintaining stable contact force against a curved, slippery surface.
- Whiteboard Wiping: Maintaining force on tilted surfaces with varying heights.
Results Table
| Model | Chip Success | Peeling Success | Wiping Success | | :--- | :--- | :--- | :--- | | π0.5 (Vision Only) | 10% | 0% | 0% | | π0.5 + Tactile (Naive) | 5% | 0% | 0% | | VTAM (Ours) | 90% | 85% | 95% |
VTAM's success isn't just about higher numbers; it's about behavioral intelligence. In the chip task, if VTAM feels the grasp fail via the tactile sensor, it automatically returns to re-attempt the grasp rather than blindly moving to the "place" position.
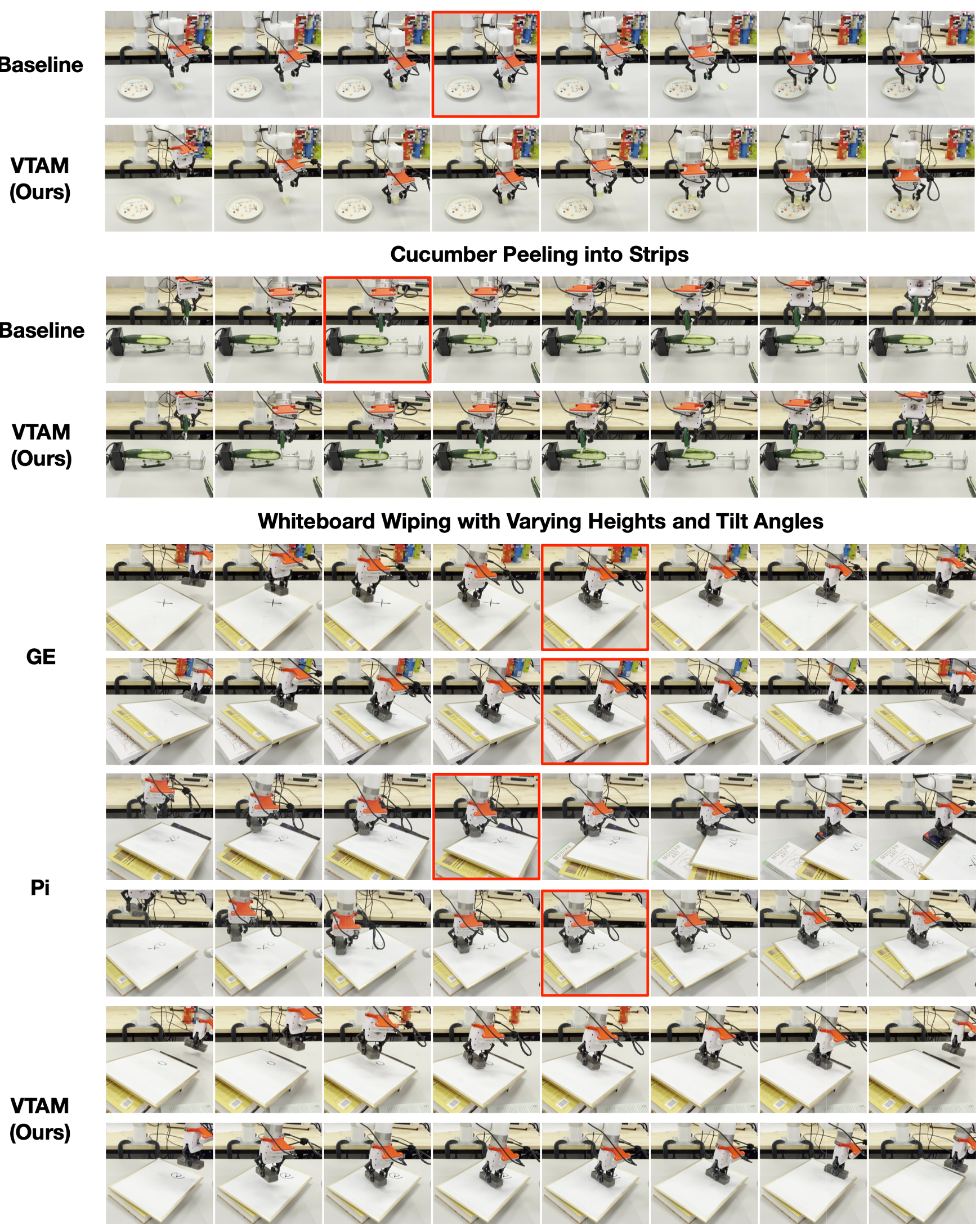 Figure: Comparison of manipulation behaviors. VTAM shows consistent force-aware trajectories, whereas baselines either lose contact or apply excessive force.
Figure: Comparison of manipulation behaviors. VTAM shows consistent force-aware trajectories, whereas baselines either lose contact or apply excessive force.
Future Outlook
VTAM proves that for embodied foundation models to truly match human dexterity, we must move beyond the "vision-first" mentality. By integrating tactile dynamics into the very core of a world model, robots can finally "feel" the world they are interacting with. This opens the door for robots in home care, surgery, and delicate manufacturing where the "soft touch" is everything.
Limitations
Currently, VTAM relies on a two-stage training process which adds complexity. Future iterations may seek to unify this into a single end-to-end pretraining regime on even larger multimodal datasets.