本文是一篇关于视频理解(Video Understanding)的深度综述,系统性地将其划分为底层几何感知、高层语义认知以及统一视频模型三个维度,重点探讨了从特定任务流水线向集成几何与语义的通用视频大模型(Video Foundation Models)的范式演进。
TL;DR
视频理解正经历一场深刻的范式革命。本文梳理了从底层几何探测(Depth, Pose, Flow)到高层语义推理(Segmentation, Tracking, VQA)的演进历程,并指出未来的终极目标是建立能感知物理规律、具备长期记忆、且能预测未来的视频基础模型(Video Foundation Models)。
1. 痛点:被孤立的“几何”与“语义”
在过去很长一段时间里,视频理解被拆解为互不干涉的子任务。做深度估计的团队往往不关心视频里的动作语义;做行为识别的团队则较少考虑场景的 3D 物理结构。这种割裂导致模型缺乏对现实世界的物理直觉(Physical Intuition),容易在长序列中出现“物体消失”或“空间扭曲”等幻觉(Hallucinations)。
2. 底层几何:从优化对齐到前馈预测
视频几何理解的核心是恢复 3D 结构。
- 经典范式:依赖推理时的多视图几何对齐,计算开销巨大。
- 新趋势:联合前馈几何模型(Joint Feed-forward Geometry Models)。
如 DUSt3R 和 VGGT 等模型,直接通过一次网络前向传播同时输出点云、深度和相机位姿。它们不再依赖繁琐的相机标定,而是学习一种通用的空间表征。
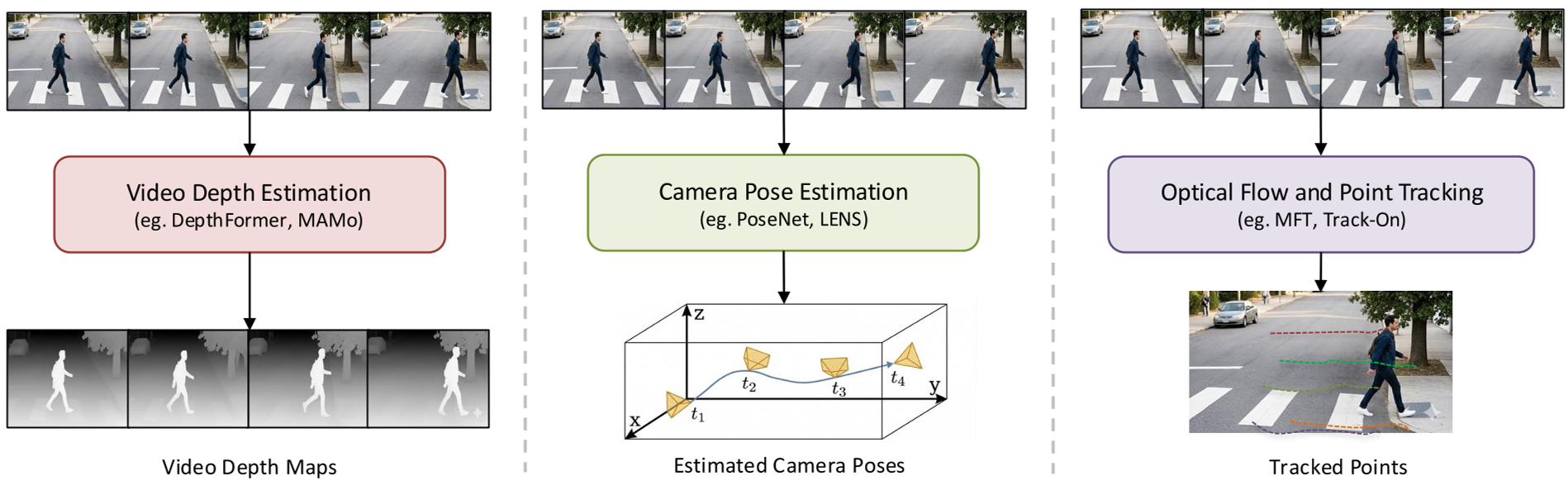 上图展示了视频深度估计、位姿估计与点追踪之间的关联。
上图展示了视频深度估计、位姿估计与点追踪之间的关联。
3. 高层语义:大模型驱动的感知飞跃
语义理解的目标是回答“视频里正发生什么”。
- 视频分割(Segmentation):从封闭集转向 Open-vocabulary(开放词汇)。SAM2 的出现标志着分割任务进入了大规模预训练时代,通过记忆机制实现了极强的时空连续性。
- 目标追踪(Tracking):正从单纯的 RGB 匹配转向 RGB-X 多模态融合(如集成深度、热成像或事件相机),以应对极端光照和遮挡。
- 视频问答(VideoQA):性能瓶颈已从原子动作识别转向了长时叙事推理(Long-form Narrative)。
 多模态追踪通过引入辅助感官线索(如 Depth)显著提升了在复杂环境下的鲁棒性。
多模态追踪通过引入辅助感官线索(如 Depth)显著提升了在复杂环境下的鲁棒性。
4. 统一模型:理解与生成的闭环
这是目前学术界最前沿的战场。为什么要把“理解”和“生成”放在一个模型里?
- 直觉(Insight):如果你能精准地模拟(生成)接下来几秒视频的演化,说明你已经彻底“理解”了当前的场景结构和因果逻辑。
作者将统一模型分为三类:
- 组装系统(Assembled):LLM 作为大脑调用专家工具(如 HuggingGPT)。
- 自回归统一模型(AR Native):将视频视为 Token 流,统一预测下一个词/块(如 Emu3, VILA-U)。
- 混合架构(Hybrid):共享骨干网络,但使用扩散(Diffusion)或流匹配(Flow Matching)实现高保真生成(如 Show-o2, TUNA)。
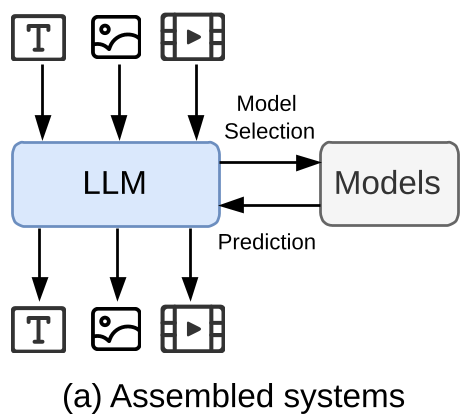 图例显示了从外部工具调用到原生 Token 统一的跨越。
图例显示了从外部工具调用到原生 Token 统一的跨越。
5. 深度洞察:未来的三大挑战
- 主动预测的世界模型:未来的模型不应只是被动地打标签,而应能像人类一样主动思考“如果我这样做,场景会发生什么”。
- 记忆作为一等公民:目前的 Transformer 在处理小时级视频时依然捉襟见肘。如何设计超越简单 Context Window 的层次化存储机制(Memory Mechanism)是关键。
- 不确定性下的规划:视频理解最终要服务于决策(如自动驾驶)。模型需要理解视频中的“不确定性”,并基于此进行概率性的路径规划。
总结
视频理解正在告别“刷榜特定数据集”的阶段,迈向具有物理一致性、语义推理能力和未来预测功能的通用智能体时代。这篇综述为研究者提供了一张清晰的路线图:几何提供骨架,语义填充灵魂,而统一模型则赋予其模拟未来的能力。