VideoDetective is an inference-only framework for long video understanding that achieves State-of-the-Art (SOTA) results by combining extrinsic query priors with the video's intrinsic structure. It models videos as Spatio-Temporal Affinity Graphs and uses a "Hypothesis-Verification-Refinement" loop to propagate relevance scores from sparse observations across the entire video.
TL;DR
In the era of long-video understanding, the bottleneck has shifted from "how to read" to "where to look." VideoDetective is a plug-and-play inference framework that treats video understanding as a signal propagation problem over a Spatio-Temporal Affinity Graph. By combining extrinsic query decomposition with intrinsic video manifold structures, it outperforms proprietary giants like GPT-4o while using a fraction of the computational budget.
The Problem: The Unidirectional Retrieval Trap
Most current long-video MLLMs follow a "Query -> Search -> Filter" paradigm. They treat a video as a bag of isolated frames or a linear sequence. If the initial query-matching step fails to find a clue, the model is essentially blind. This approach ignores a fundamental truth: video content is highly redundant and structured. Temporal dynamics and visual similarities mean that a "part" can often tell you about the "whole."
Existing methods suffer from:
- Context Window Limits: Dense sampling is too expensive.
- Structural Blindness: They don't use the video's internal correlations to guide the search.
- Reasoning Rigidity: If the first "hit" isn't the right one, there's no systematic way to "diffuse" that information to neighboring segments.
Methodology: The Hypothesis-Verification-Refinement Loop
VideoDetective transforms the video into a graph $G = (V, E)$.
- Nodes ($V$): Semantic segments grouped by visual similarity.
- Edges ($E$): A fusion of Visual Affinity (pixel-level similarity) and Temporal Affinity (proximity in time).
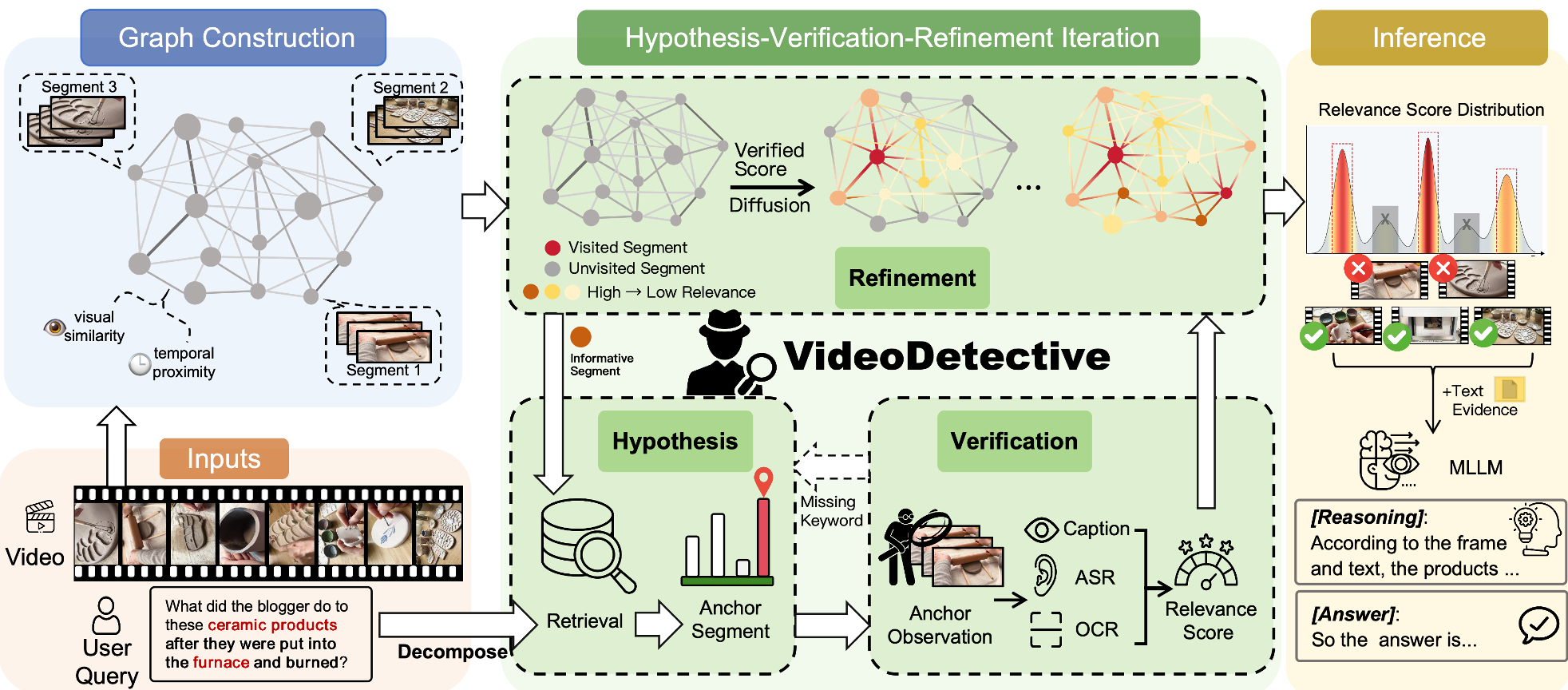
The framework operates through an iterative loop that mirrors how a detective might search a crime scene:
- Hypothesis: The model decomposes a complex query into semantic facets (entities and events). It selects an "anchor" segment based on initial priors.
- Verification: It zooms into the anchor, extracting multimodal evidence: Visual Captions, OCR (on-screen text), and ASR (speech). It computes a local relevance score.
- Refinement: This is the "secret sauce." The local relevance score is treated as an injection signal and diffused across the graph. Through manifold regularization, the model updates a Global Belief Field. If a segment is visually/temporally close to a confirmed clue, its belief score rises, even if it hasn't been "seen" yet.
The Math: Manifold Smoothness
The model minimizes a cost function that balances Consistency (keeping the scores of observed segments) and Smoothness (ensuring neighbors on the graph have similar scores): $$\mathcal{J}(\mathbf{F}) = |\mathbf{F} - \mathbf{Y}|_2^2 + \mu \mathbf{F}^ op \mathbf{L} \mathbf{F}$$ Where $L$ is the graph Laplacian. This allows the relevance signal to "flow" through the video structure.
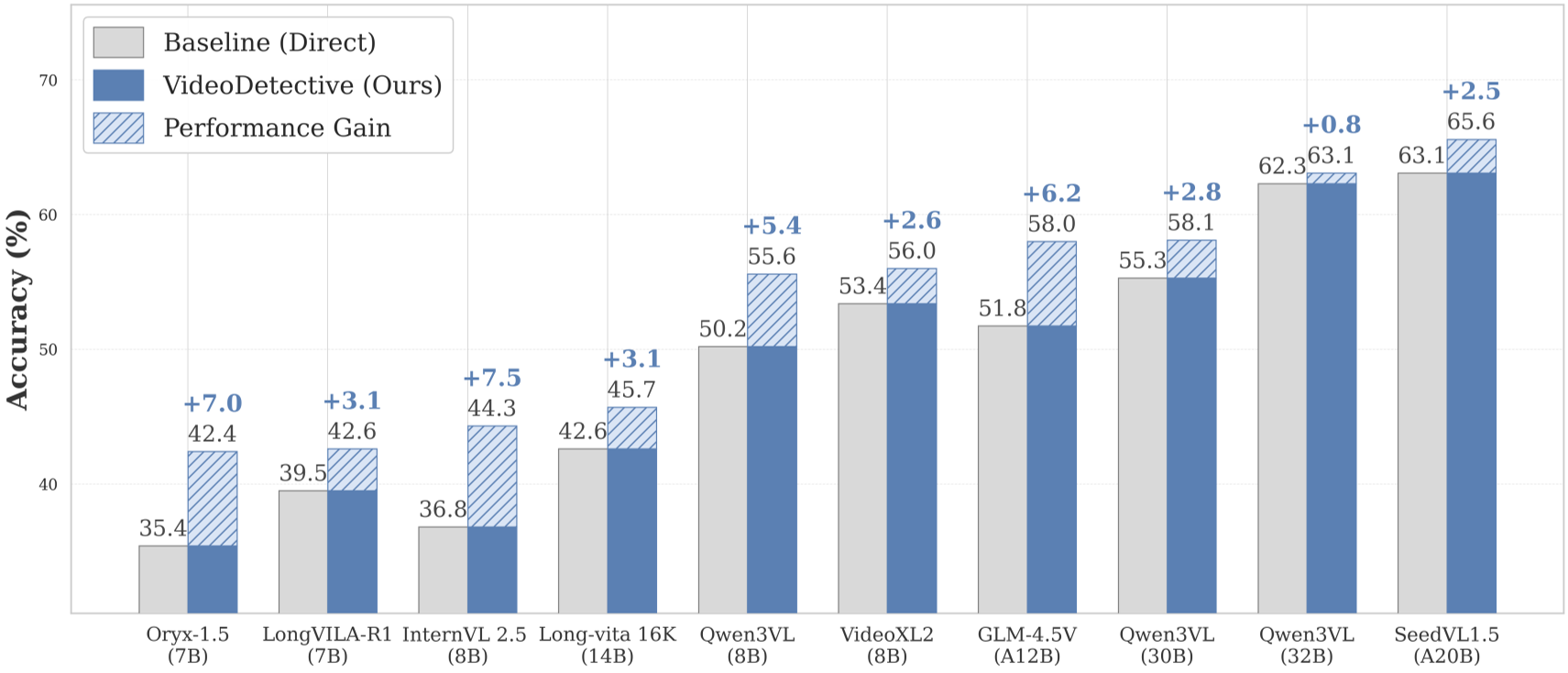
Experiments: Surpassing the Giants
VideoDetective was tested across a variety of backbones (InternVL, Qwen, SeedVL) and benchmarks (VideoMME, MLVU).
Key Results:
- Plug-and-Play Gains: It provided a 7.5% boost to InternVL-2.5 (8B) without any additional training.
- Beating Proprietary Models: When paired with SeedVL-1.5 (20B), it achieved 67.9% on LongVideoBench, surpassing GPT-4o and Gemini-1.5-Pro.
- Efficiency: It reaches these SOTA levels using roughly 10x fewer tokens than the top-tier proprietary models, making it significantly cheaper for production use.
Deep Insight: Is the Bottleneck the Brain or the Eyes?
An intriguing "scaling analysis" in the paper reveals that upgrading the LLM (the plan/reasoner) from 8B to 30B barely changed performance. However, upgrading the Visual Encoder (the eyes) led to a massive jump.
Takeaway: Under the VideoDetective framework, we don't necessarily need a "smarter" brain to handle the long context; we need "better eyes" to verify the clues the framework localizes.
Conclusion
VideoDetective proves that long-video understanding isn't just a hardware challenge—it's an algorithmic one. By shifting from linear sequence processing to topological belief propagation, we can build systems that reason more like humans: making a guess, verifying it, and using the context of the "neighborhood" to find the next clue.
Limitations
The system currently relies on the VLM's ability to self-reflect (identifying "missing keywords"). If a visual model is over-confident or hallucinates a "match," the belief field can be poisoned by false signals. Future work in robust uncertainty estimation will be key to making the "Detective" even more reliable.