ViewSplat is a novel pose-free, feed-forward 3D Gaussian Splatting (3DGS) framework that achieves state-of-the-art novel view synthesis by shifting from static primitive regression to a view-adaptive dynamic representation. Key achievements include superior fidelity on RE10K and ACID benchmarks while maintaining high real-time rendering speeds (154 FPS).
TL;DR
ViewSplat introduces a view-adaptive dynamic refinement layer to generalizable 3D Gaussian Splatting. By using a hypernetwork to generate target-view-conditioned residual updates, it allows 3D primitives to "morph" their geometry and appearance on-the-fly to match specific viewpoints. This achieves SOTA fidelity in pose-free reconstruction, outperforming static methods that rely on high-order Spherical Harmonics.
Positioning: This work moves beyond the "regression-only" paradigm of feed-forward 3DGS, introducing a lightweight dynamic update mechanism that mimics the refinement process of optimization-based methods but at 150+ FPS.
Problem & Motivation: The Static Primitive Bottleneck
Traditional generalizable 3DGS (e.g., pixelSplat, MVSplat) follows a rigid pipeline: extract features -> regress Gaussian attributes -> render. While fast, this "one-size-fits-all" approach fails when encountering:
- Non-Lambertian effects: Mirrors and glossy surfaces look different from every angle.
- Estimation Errors: A single forward pass often produces slightly displaced centers or incorrect scales that a static renderer cannot fix.
The authors observed that while regressing a universal 3D scene is hard, adjusting primitives for a specific view is significantly easier.
Methodology: View-Adaptive Dynamic Splatting
The core innovation of ViewSplat is the View-Dependent Head. Instead of predicting just the Gaussians, the model predicts weights for a dynamic MLP.
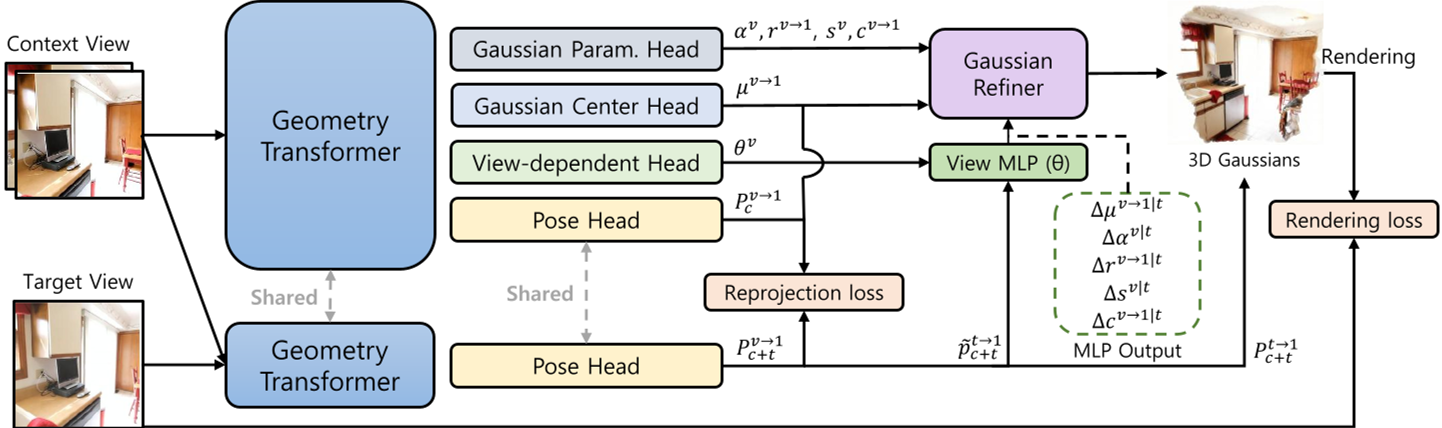
1. The Hypernetwork Design
The architecture uses a Dense Prediction Transformer (DPT) to generate pixel-wise parameters for a "View MLP." This allows the model to create custom response functions for different parts of the scene (e.g., complex functions for shiny metal, simple ones for flat walls).
2. Pose Reparameterization
Feeding a raw $4 imes 4$ matrix into an MLP is inefficient. ViewSplat reparameterizes the target pose into:
- A 3D unit viewing direction.
- A 1D log-scale distance (preserving sensitivity for near-field objects where perspective changes are most drastic).
3. Residual Refinement
The View MLP outputs residuals ($\Delta \mu, \Delta \alpha, \Delta r, \Delta s, \Delta c$) which are added to the base Gaussians. This "Dynamic Refinement" allows the primitives to shift and change opacity/color based on where the camera is.
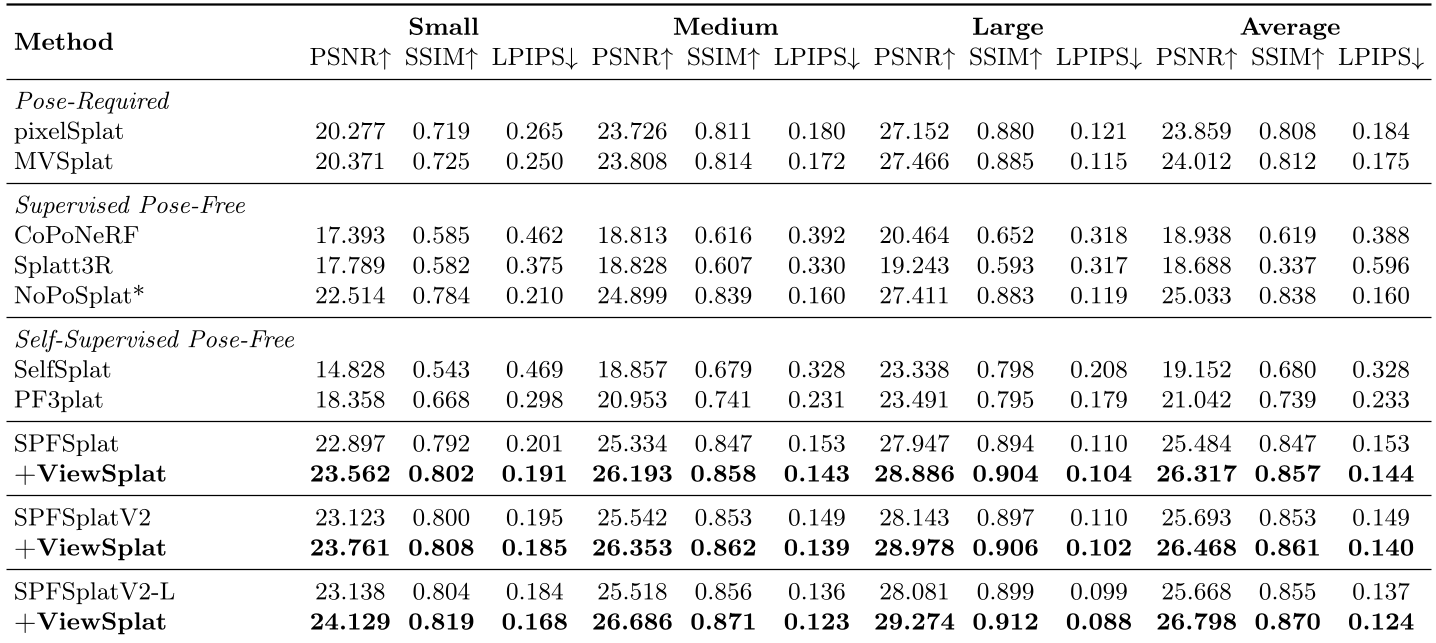
Experiments & Results: New SOTA in Pose-Free NVS
ViewSplat was tested on RE10K (interiors) and ACID (nature) datasets. It consistently outperformed previous baselines across all metrics.

Key Insights from Results:
- SH Degrees vs. Dynamic Updates: The authors found that increasing Spherical Harmonics (SH) degrees from 4 to 8 provided almost no gain. However, ViewSplat's residual updates at SH degree 4 vastly outperformed high-order SH models, proving that MLPs are better at capturing non-linear appearances than SH coefficients.
- Syncing $\mu$ and $\alpha$: An important ablation showed that if you update the position ($\mu$) without updating the opacity ($\alpha$), the scene collapses into artifacts. Proper view-adaptation requires a holistic update of all geometric and photometric attributes.
Critical Analysis & Conclusion
Takeaway: ViewSplat successfully demonstrates that the bottleneck in feed-forward 3DGS wasn't necessarily the feature backbone, but the rigidity of the primitive representation. By making the splatting process view-adaptive, they regained much of the fidelity lost when moving away from per-scene optimization.
Limitations:
- Unobserved Regions: Like all reconstruction models, it cannot "hallucinate" parts of the room that weren't in the input images (see Fig. 6 in the paper).
- Rendering Overhead: The dynamic refinement does reduce rendering speed (from ~390 FPS to ~150 FPS), though it remains well above the real-time threshold.
Future Outlook: This view-adaptive paradigm could be extended to 4D (temporal) scenes or integrated with generative priors (Diffusion Models) to solve the "unobserved region" problem.