This paper introduces VIKEY, a training-free framework that enhances temporal reasoning in Video Large Language Models (VideoLLMs) using sequential Visual Prompting (VP) and Keyword-Frame Mapping (KFM). By overlaying frame-index numbers (e.g., "frame #01") and aligning textual keywords with specific frames, VIKEY achieves SOTA-level temporal understanding even with sparse frame sampling (20% of original frames).
TL;DR
Processing every frame in a video is too expensive, but skipping frames makes VideoLLMs "forget" the order of events. VIKEY solves this without any extra training. By simply "burning" frame numbers into the corner of the video and mapping keywords in the user's question to those numbers, it allows models to reason about time with 80% fewer frames.
Academic Positioning: This work is a "Training-Free Efficiency Plug-in." It challenges the notion that better temporal reasoning requires complex new architectures, suggesting instead that the bottleneck is often the lack of explicit temporal anchors in the input space.
The "Broken Continuity" Problem
When we watch a video of a referee giving a red card, we understand the sequence: Foul -> Whistle -> Card. However, if a VideoLLM only sees three sparse frames, it might see the player on the ground and the referee holding a card, but lose the causal link.
The authors discovered that VideoLLMs fail here not because they can't "see," but because the temporal positional embeddings (RoPE) are often insufficient to reconstruct a coherent timeline when the gap between frames is too large.
Methodology: The VIKEY Framework
VIKEY operates on a simple yet profound insight: VideoLLMs can use frame numbers as "Dictionary Keys."
1. Sequential Visual Prompting (VP)
The system physically overlays "frame #01", "frame #02" etc., onto the bottom-left corner of each sampled frame. Through "Positional Embedding Degradation" tests, the authors proved that these numbers act as a safety net—even if the model's internal sense of time is "collapsed" mathematically, it can still read the numbers on the screen to figure out the order.
2. Keyword-Frame Mapping (KFM)
This is the "logic" layer. If a user asks "What happened before the person picked up the broom?", the KFM module:
- Extracts the keyword "picked up the broom."
- Uses CLIP to find which frame looks most like that action.
- Rewrites the prompt: "What happened before the person picked up the broom (frame #05)?"
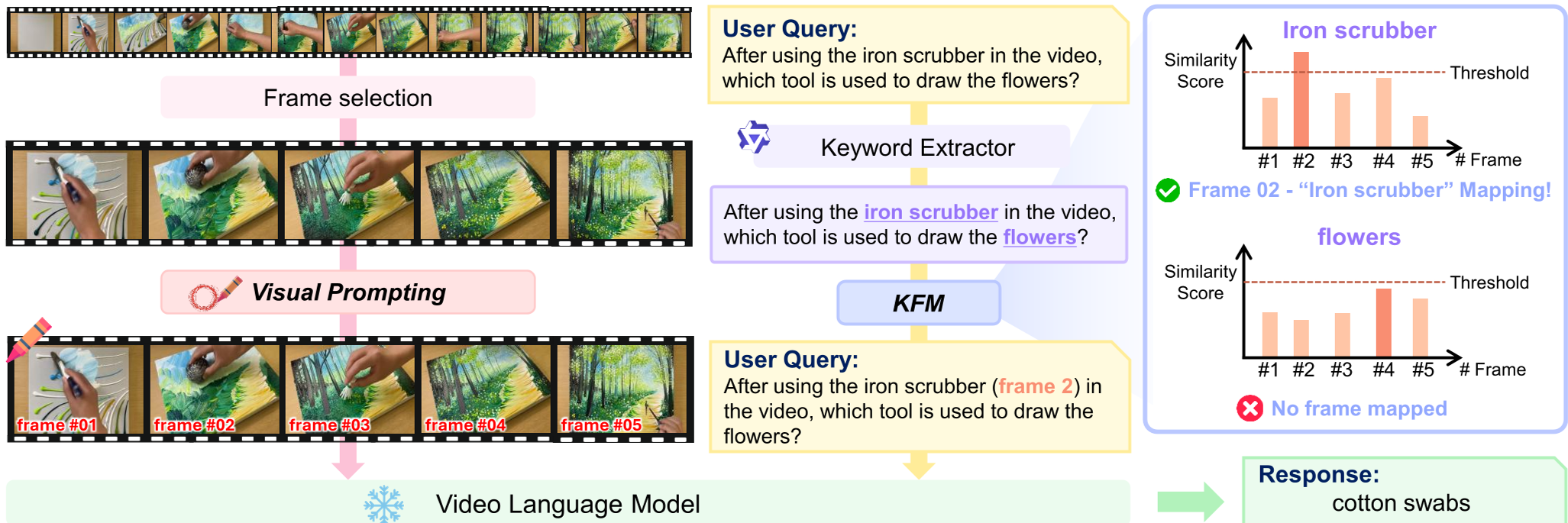 Figure: The overall pipeline showing Frame-number VP and the KFM rewriting process.
Figure: The overall pipeline showing Frame-number VP and the KFM rewriting process.
Key Insights: The "Bottom-Left" Bias
One of the paper's most intriguing findings is a strong positional bias. Probing the model revealed that placing the frame index in the Bottom-Left (BL) or Bottom-Right (BR) corners resulted in nearly 100% accuracy for frame lookup, while the Top-Left corner often caused "off-by-one" errors.
Why? The authors hypothesize that LLMs are conditioned on web videos where subtitles and watermarks appear at the bottom. The models have learned to treat the bottom region as a primary source for metadata.
Performance & Efficiency
VIKEY isn't just a "neat trick"; it's a massive efficiency gain. In the 20% frames setting, VIKEY helped LLaVA-Video-7B achieve higher scores on the VideoMME Temporal Reasoning benchmark than the baseline did with 100% of the frames.
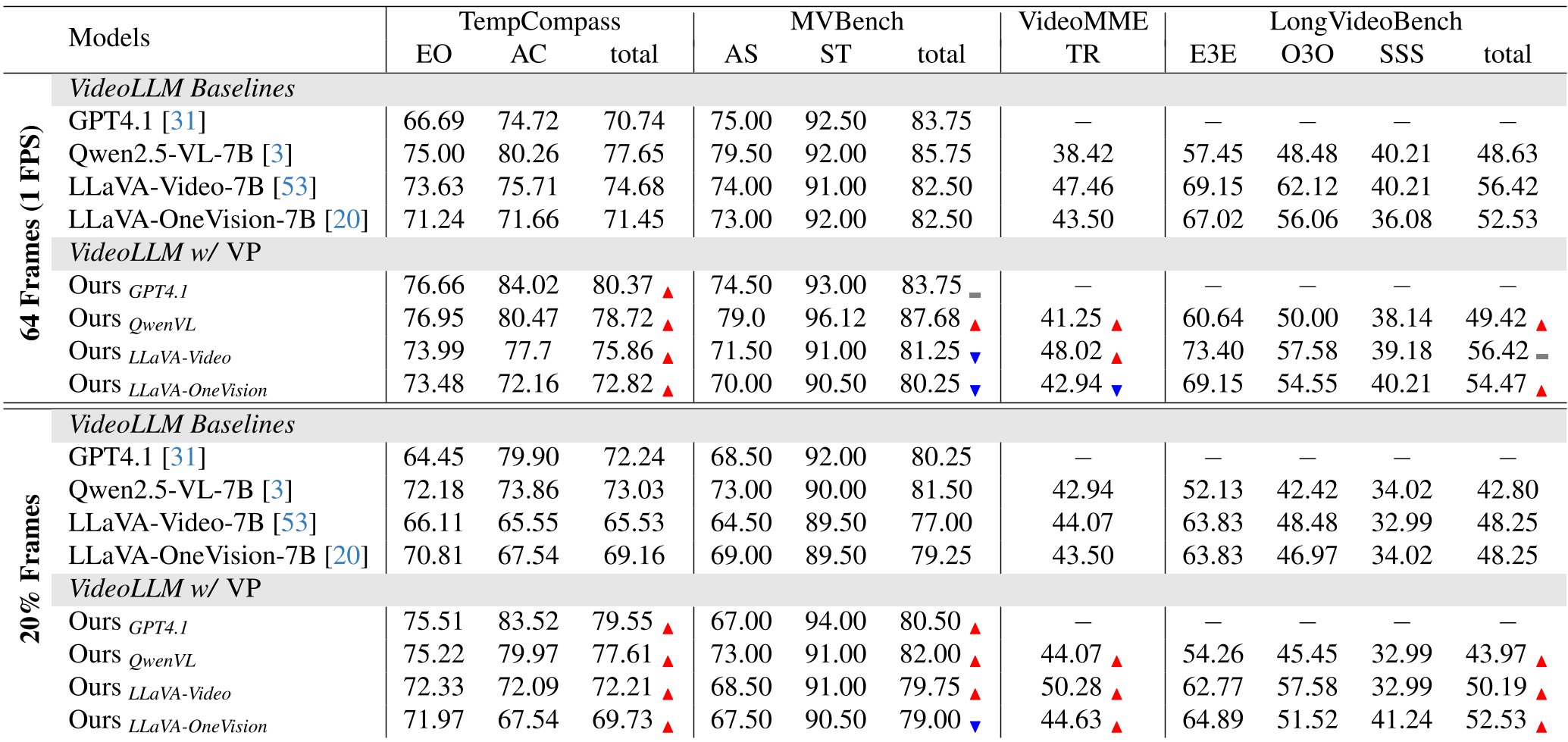 Table: VIKEY consistently outperforms baselines, especially in "20% Frames" scenarios.
Table: VIKEY consistently outperforms baselines, especially in "20% Frames" scenarios.
Critical Analysis & Conclusion
Takeaway: VIKEY proves that "Temporal Reasoning" can be partially offloaded to "Spatial Referencing." If you give the model a label it can see, it doesn't need to "guess" the time from the sequence order.
Limitations:
- Occlusion: The frame numbers can occasionally cover small, critical details.
- Visual Ambiguity: If a video has many identical frames (e.g., a static camera), CLIP similarity might map a keyword to the wrong frame number, leading the model astray.
Future Outlook: VIKEY opens the door for "Dynamic Prompting," where the model could potentially choose where to place visual markers based on the scene content (Saliency-aware VP), ensuring that indices never block the action.